Saudações. Nesse artigo vamos explorar o REDIS, um software de armazenamento de dados baseado em memória RAM.
O REDIS é um software que provê um serviço de armazenamento de dados de alta velocidade. Ele foi feito para operar armazenando dados em formato “chave valor” com a maior velocidade computacional possível ao basear-se em armazenamento puramente na memória RAM (nano-segundos, latência interna de CPU e latência entre a CPU e a RAM).
Nas arquitetura de mercado (x86, arm, mips, …) essas operações de CPU-RAM são o mais rápido que se pode alcançar. Só há como ser mais rápido que isso em ambientes confinados de ASIC, FPGA, DPU ou GPU.
Você ja usa o REDIS!
Basicamente tudo que você faz na Internet e os aplicativos que usa no smartphone fazem uso intenso dele ou algum software semelhante e concorrente.
Todos os conceitos e recursos do REDIS serão explicados em capítulos específicos, eis um breve resumo:
Principais aplicações práticas do REDIS
- Como memória compartilhada entre sistemas (variáveis globais dos programas de um sistema);
- Como CACHE (cópia) de dados, provendo alta velocidade a consultas repetitivas;
- Como fila de escrita atrasada de aplicações de alta velocidade;
- Como banco de dados distribuídos (cluster de vários servidores REDIS);
- Como HUB de mensagens PUB/SUB (o REDIS avisa a vários clientes sobre uma nova chave);
- Como memória de contexto e curto prazo para a inteligência artificial e chatbots;
Principais formas de rodar o REDIS
- A mais comum: como servidor de CACHE local (98% dos casos) puramente em RAM, sem senha, em Docker/container;
- Como banco de dados persistente de alta velocidade: opera na RAM mas grava os dados em disco (escrita atrasada: RDB, AOF);
- Com HUB mensageiro (Pub/Sub e Streams): usado para montar chats e trocar sinalizações ou mensagens entre sistemas que rodam em servidores diferentes;
- Em cluster REDIS simples onde vários servidores REDIS ficam sincronizados entre si em tempo real;
- Em cluster REDIS com Sentinel (serviço de monitoramento, ativação/desativação e escalonamento);
Conhecimentos e procedimentos prévios
- Instalação e uso de Linux;
- Instalação de programas básicos;
- Data/hora sincronizada via NTP;
- Ajuste fino no kernel Linux (geral) e ajustes de uso de RAM e memória virtual;
Licenciamento e alternativas ao REDIS
O REDIS era 100% gratuito e open-source, livre para uso e distribuição comercial. Infelizmente isso mudou e ele foi dividido em dois softwares, o REDIS Community Edition segue a linha original, e o Redis Core segue a linha comercial, possuindo mais recursos (RediSearch, RedisGraph, RedisBloom, etc…) com licenças mais restritas.
Por conta disso ele sofreu FORKs de código gerando concorrentes da mesma natureza, 100% compatíveis com o protocolo de cliente-servidor. Dessa forma, os conceitos aqui servem para os softwares:
- REDIS Community: versão aberta e gratuita;
- REDIS Core: versão comercial, mais avançada;
- DragonFly: fork do REDIS 100% compatível, um dos melhores, tem suporte a multi-threading;
- KeyDB: fork do REDIS com maior similaridade, tem suporte a multi-threading;
- Tile38: compativel e mais focado em dados de geolocalização;
- Ardb: possui mais opções de backends (RocksDB, LMDB, etc..);
- ValKey: embora seja muito semelhante ao REDIS, não é compatível o suficiente para substituir o REDIS Server de forma transparente;
1 – Introdução ao REDIS
Para aprendizado e uso simples, você pode instalar o REDIS em uma máquina virtual ou VPS, exemplo:
# Rodando REDIS no HOST (direto no Linux)
# Instalar pacote:
apt-get -y install redis
# Ativar o REDIS durante o boot do Linux:
systemctl enable redis-server
# Ativar o serviço:
systemctl start redis-server
# Conectar usando o redis-cli no proprio HOST:
redis-cli
Para rodar em Docker:
# Rodando REDIS no DOCKER
# Criar e rodar o container:
docker run -d --name redis redis:7.4.1-alpine
# Conectar usando o redis-cli dentro do container:
docker exec -it redis redis-cli
Entrando (conectar) no REDIS e testar PING/PONG e ECHO:
# Conectar ao REDIS rodando no mesmo servidor:
redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> PING
PONG
127.0.0.1:6379> echo OLA
"OLA"
127.0.0.1:6379> quit
Os comandos “ping” e “echo” são as duas formas de testar a comunicação entre o cliente (redis-cli) e o servidor (redis-server).
Os comandos do REDIS podem ser executados em minúsculo ou maiúsculo (case-insensitive), não há diferença entre “ping” e “PING“, “set” ou “SET“.
É recomendado que todos os comandos sejam em MAIÚSCULO.
Apenas tome cuidado com o nome das chaves pois elas fazem diferença entre minúsculas e maiúsculas (case-sensitive).
2 – Aprendendo a usar o REDIS: tipos de chaves simples
Prévia do capítulo
Se você está com pressa e quer achar logo o que procura, aqui está o resumo de todos os exemplos e possibilidades de uso das chaves simples que será apresentado nesse capítulo:
- KEYS: consulta a lista de chaves existentes;
- EXISTS: retorna se uma chave existe, precisamente, quantas chaves existem;
- GET: retorna o valor da chave especifiada;
- MGET: retorna o valor de várias chaves especificadas num único comando;
- MSET: permite criar várias chaves num único comando;
- DEL: deleta uma chave pelo nome exato, suporta deletar várias chaves;
- SET: cria uma chave;
- SET EX: cria uma chave com expiração em segundos;
- SET PX: cria uma chave com expiração em milisegundos;
- SET EXAT: cria uma chave com expiração agendada no futuro em timestamp;
- SET PXAT: cria uma chave com expiração agendada no futuro em timestamp com milisegundos;
- SET KEEPTTL: cria uma chave, mas se ela ja existir o valor é alterado sem mexer no TTL;
- SET NX: cria uma chave somente se ela não existir;
- SET XX: altera uma chave somente se ela existir;
- TTL: consulta o tempo em segundos que uma chave ainda tem de vida;
- PTTL: consulta o tempo em milisegundos que uma chave ainda tem de vida;
- PERSIST: remove o TTL da chave e a torna persistente/perpétua;
- EXPIRE: edita o TTL de uma chave e define o novo tempo de vida em segundos;
- PEXPIRE: edita o TTL de uma chave e define o novo tempo de vida em milisegundos;
- STRLEN: retorna o tamanho em bytes do valor da chave (espaço alocado em RAM);
- SETRANGE: permite alterar bytes específicos do valor da chave;
- GETRANGE: permite obter bytes específicos do valor da chave;
- INCRBY: incrementa um número inteiro do valor numérico de uma chave;
- DECRBY: decrementa um número inteiro do valor numérico de uma chave;
- INCRBYFLOAT: incrementa (valor positivo) ou decrementa (valor negativo) um número de ponto flutuante de um valor numérico de uma chave (não existe o comando DECRBYFLOAT);
- FLUSHALL: bomba nuclear que limpa todo o terreno e apaga todas as chaves do REDIS;
O que são chaves simples?
Os comandos de chaves simples são todas do mesmo tipo e armazenam um único valor em uma chave nomeada, vamos explorar os comandos mais viciados: SET, GET, APPEND, STRLEN, MSET, MGET, DEL.
Você pode armazenar números inteiros, de ponto flutuante (um pouco perigoso) e texto. O uso mais comum é armazenamento de texto em formato JSON e binários em representação BASE64.
Conecte-se ao REDIS (comando: redis-cli), os blocos abaixo vão expor somente comandos dentro do terminal do REDIS.
SET, GET, APPEND, STRLEN, MSET, MGET, DEL: básico de REDIS para CRUD
CRUD é o nome que se dá a sistemas que operam nas operações mais simples de manipulação de dados: (C) Create, (R) Read, (U) Update e (D) Delete.
Enquanto que no SQL temos INSERT, SELECT, UPDATE e DELETE, no REDIS temos as mesmas operações e vários operadores para gerir as propriedades, INSERT e UPDATE são representados pelo “SET” e “MSET“, DELETE é representado pelo “DEL” e pela expiração do tempo de vida da chave, e o SELECT é representado pelo “GET” e “MGET“.
Exemplos primordiais:
# Criar uma chave eterna:
# * Observe a diferença entre maiúsculas e minúsculas no nome da chave:
SET NOME "Aluno do Mestre"
OK
SET Nome "Patolino da Silva"
OK
SET nome "Julio Cesar"
OK
# Verificar se a chave existe:
EXISTS NOME
(integer) 1
# Verificar quantas chaves existem na lista de nomes de chaves desejados:
EXISTS NOME Nome nome xpto nao_existe nao_existe_mesmo abcd123 aa99999
(integer) 3
# Obter valor das chaves:
GET NOME
"Aluno do Mestre"
GET Nome
"Patolino da Silva"
GET nome
"Julio Cesar"
# Alterar valor de uma chave existente (igual a criacao da chave):
SET NOME "Pequeno Gafanhoto"
OK
# Listar todas as chaves existentes:
KEYS *
1) "nome"
2) "NOME"
3) "Nome"
# Adicionar valor (concatenar no final) em uma chave existente:
APPEND nome ", O imperador"
(integer) 24
GET nome
"Julio Cesar, O imperador"
STRLEN nome
(integer) 24
# Criar/definir mulplicas chaves ao mesmo tempo (chave valor chave valor ...)
MSET client_1023_nome "Patrick" client_1023_profissao "Empresario"
OK
# Obter varias chaves ao mesmo tempo:
MGET client_1023_nome client_1023_profissao
1) "Patrick"
2) "Empresario"
# Apagando uma chave:
DEL client_1023_nome
(integer) 1
# Tentando apagar uma chave que não existe:
DEL client_1023_nome
(integer) 0
# Tentando obter valor de uma chave que não existe:
GET client_1023_nome
(nil)
# Apagando múltiplas chaves:
DEL NOME Nome nome client_1023_nome client_1023_profissao
(integer) 5
# Verificando as chaves apos deletarmos todas que criamos:
KEYS *
(empty array)
SETRANGE e GETRANGE – Comandos para manipular texto dentro de uma chave
# Criar uma chave com um texto para manipulacao:
SET frase "O rato roeu a roupa do rei de roma"
OK
# Conferindo:
GET frase
"O rato roeu a roupa do rei de roma"
# Verificando tamanho da frase:
STRLEN frase
(integer) 34
# Nossa frase de exemplo tem 34 bytes.
# Para manipulá-la o cursor de manipulação deve ser posicionado.
# A posição do cursor pode ir de zero (primeiro caracter) ao
# tamanho da frase menos 1, ou seja, se a frase tem 34 bytes,
# o cursor pode ir de 0 a 33
# Mudando a primeira letra:
SETRANGE frase 0 "X"
(integer) 34
GET frase
"X rato roeu a roupa do rei de roma"
# Mudando as 6 primeiras letras no inicio:
SETRANGE frase 0 "O tatu"
(integer) 34
GET frase
"O tatu roeu a roupa do rei de roma"
# Obtendo um pedaço da frase:
GETRANGE frase 0 5
"O tatu"
# - Posições negativas movem o cursor apartir do último byte em
# direção ao inicio. Com 34 digitos a última posição é -1
GETRANGE frase -4 -1
"roma"
GETRANGE frase -11 -1
"rei de roma"
INCRBY e DECRBY – Números inteiros para incremento e decremento
# Criar um contador:
SET blog_visitantes "1"
OK
GET blog_visitantes
"1"
# Incrementar (+1), o retorno será o valor pos-incremento:
INCRBY blog_visitantes 1
(integer) 2
# Incrementar (+1000):
INCRBY blog_visitantes 1000
(integer) 1002
# Decrementar (-1):
DECRBY blog_visitantes 1
(integer) 1001
# Decrementar (-30):
DECRBY blog_visitantes 30
(integer) 971
# CUIDADO aqui: cuidado ao informar um argumento negativo:
# Exemplo:
SET temperatura 32
OK
# - incrementar valor negativo = decrementar
INCRBY temperatura -1
(integer) 31
# - descrementar valor negativo = incrementar
DECRBY temperatura -10
(integer) 41INCRBYFLOAT – Números flutuantes para incremento e decremento
# Criar um contador:
SET divida_com_agiota "10000"
OK
GET divida_com_agiota
"10000"
# Incrementar (+120.31), o retorno será o valor pos-incremento:
INCRBYFLOAT divida_com_agiota 120.31
"10120.30999999999999961"
# Deveria retornar 10120.31, mas devido a erros
# acumulativos de ponto flutuante você só obteria
# o valor exato de 10120.31 se fizer um round() na linguagem
# de programacão que faz uso do REDIS.
# Para entender mais sobre esse problema, leia o padrão IEEE 754
# Decrementar (-120.31)
# Não há o comando decrbyfloat, incrementa um valor negativo
# para decrementar:
INCRBYFLOAT divida_com_agiota -120.31
"10000"
3 – Databases no REDIS e o isolando básico de dados
Certa vez um cliente me ligou dizendo que o REDIS estava funcionando na aplicação que ele configurou, mas ao entrar no REDIS ele não enxergava nenhuma chave. Ele desconhecia o conceito de databases do REDIS!
O REDIS possui, por padrão, a capacidade de alternar entre 16 databases, esse valor pode ser aumentado ou reduzido se você personalizar a configuração (explico a configuração em capítulos seguintes).
Você não pode dar nomes aos “databases“, eles possuem apenas um número, de 0 a 15 (os 16 possíveis por padrão). Cada database é chamado de “keyspace” na terminologia do REDIS.
Sempre que você acessa um servidor REDIS você está por padrão no database 0 (zero). As chaves que você criar estarão confinadas no keyspace zero!
# Criando uma chave, naturalmente no database 0 (zero) - db0
SET teste "O rato foi de base"
OK
GET teste
"O rato foi de base"
# Pulando para o database 1 - db1
SELECT 1
OK
# O prompt do redis-cli apontará o [1] como indicador que você
# está em um database específico, diferente do padrão.
# Os comandos abaixo não consideram digitar o "[1]", coloquei apenas para
# demonstrar que está dentro do database.
# Ao tentar consultar a chave 'teste', ela não existe.
[1] GET teste
(nil)
[1] SET teste "O gato morreu envenenado ao comer o rato radioativo"
OK
[1] GET teste
"O gato morreu envenenado ao comer o rato radioativo"
# Alternando para o database 0 (zero) padrão - db0
SELECT 0
OK
# Consultando a chave de 'teste' do database 0
GET teste
"O rato foi de base"
Fique atento ao usar o recurso de database para não se perder. O recurso é mais bem utilizado quando você determina um keyspace para cada aplicação que não pode se misturar com outras no mesmo servidor REDIS.
Algumas manobras do conceito:
# Visualizando os databases em uso:
INFO keyspace
# Keyspace
db0:keys=8,expires=0,avg_ttl=0
db1:keys=1,expires=0,avg_ttl=0
# Alternando para db1
SELECT 1
OK
# Limpar ambiente do database:
[1] FLUSHDB
OK
# Conferindo uso dos databases:
# - Observe que o db1 não aparece no resultado, databases vazios são ignorados
INFO keyspace
# Keyspace
db0:keys=8,expires=0,avg_ttl=0
# Criar 2 chaves de teste:
[1] set frase_01 "Tudo baseado em gambiarra se resolve com uma nova gambiarra."
[1] set frase_02 "As suas gambirras sao as melhores pois sao suas."
# Conferindo o uso de chaves dentro do database db1:
# - Retorna o número de chaves em uso
[1] DBSIZE
(integer) 2
# Limpando ambiente (destruindo todas as chaves de todos os databases)
# - O flushall NÃO é confinado ao database em uso, ele limpa TUDO
[1] FLUSHALL
OK
# Visualizando os databases em uso:
INFO keyspace
# Keyspace
#(fim, sem outras linhas, apagou tudo de todos os databases)
4 – Chaves temporárias – gerenciando tempo de vida (TTL)
Apenas crias as chaves faz com que elas existam perpetuamente, se você fez uso de RDB/OAF elas durarão para sempre a menos que algum algoritmo interno a remova (por falta de espaço em RAM por exemplo).
Ao usar o REDIS para cache de dados (cópia de dados oficiais que estão em outro local), é importante determinar um tempo de vida para as chaves.
Imagine um site onde o resultado de um jogo é exibido para 1 milhão de visitantes por segundo. Armazenar esse resultado em um banco SQL resultaria em 1 milhão de consultas SELECT por segundo.
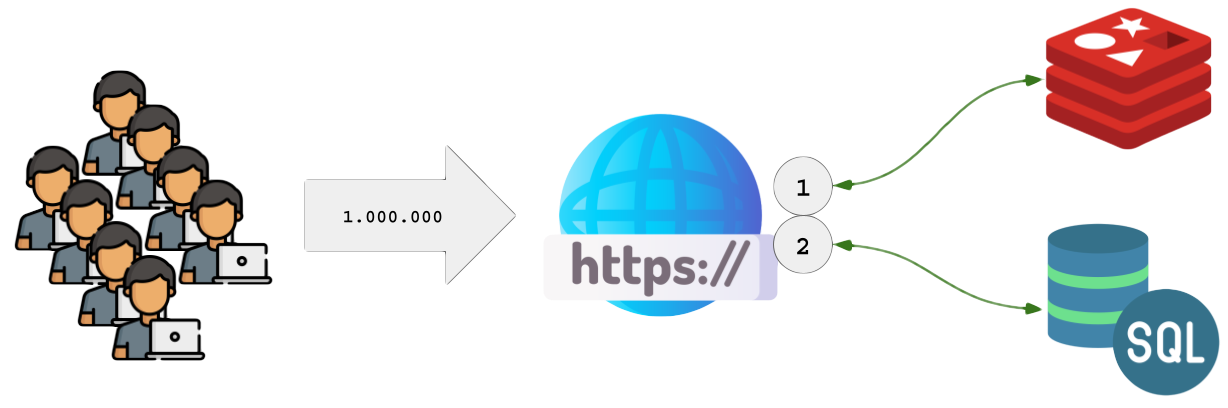
O site poderia ser programado para procurar a chave “resultado_jogos” no REDIS e se ela existir, retornar seu valor ao visitante (1).Essa chave poderia ser criada com TTL de 3 segundos. Sempre que a chave expirar ela desaparece do REDIS, e na sua ausência o site buscaria o resultado no servidor SQL e gravaria novamente a chave no REDIS com TTL de 3 segundos. O REDIS seguraria uma taxa de 3 milhões de consultas para cada uma SQL SELECT. A cada minuto, por volta de 60 milhões de exibições seriam atendidas pelo REDIS e apenas 30 SQLs seriam executadas.
SET com TTL, EXPIRE, PEXPIRE, EXPIREAT, PEXPIREAT, PERSIST
Gerir chaves e o tempo que elas vão durar – tempo de vida ou TTL (time to live) – é de suma importância para sistemas de alta velocidade.
Um sistema baseado em banco de dados SQL pode enviar as chaves alteradas para o REDIS de maneira ativa para que os sistemas que faz uso dos dados nem precise tocar no SQL.
Exemplo: um banco de dados com 500 mil cadastros que faz rotinas de verificação constantes nos registros pode aproveitar a oportunidade e enviar uma ordem SET para o REDIS a cada registro analisado, fazendo o REDIS possuir uma cópia fiel de toda a base, e sempre que um registro é alterado uma nova ordem SET é enviada, atualizando o REDIS.
Algumas chaves podem alternar entre a volatilidade (expiram) e a não volatilidade de acordo com as necessidades do sistema que faz uso do REDIS, logo, tanto determinar a validade (EXPIRE) quanto garantir a persistência (PERSIST) sem alterar o valor ou redefinir a chave é muito desejavel.
Veja todos os exemplos de como criar chaves com expiração, alterar e retirar expiração e consultar o tempo de expiração das chaves:
# Exemplo 1:
# Criar uma chave (perpetua):
SET resultado_megasena "01 - 17 - 19 - 29 - 50 - 57"
OK
# Definir o TTL da chave em 3 segundos (some 3 segundos após esse comando):
EXPIRE resultado_megasena 3
(integer) 1
GET resultado_megasena
"01 - 17 - 19 - 29 - 50 - 57"
# Espere 3 segundos e consulte a chave:
# - o retorni nil significa que a chave nao existe
GET resultado_megasena
(nil)
# Criando a chave e a expiração em milisegundos (3s = 3000ms) no mesmo comando:
SET resultado_megasena "01 - 17 - 19 - 29 - 50 - 57" PX 3000
OK
# Exemplo 2:
# Criando uma chave com 20 segundos de TTL
SET cadastro_cliente_1001 "{ 'nome': 'Marco Polo', 'idade': '31' }" EX 20
OK
# Consultar o tempo restante para a chave expirar (em segundos):
TTL cadastro_cliente_1001
(integer) 17
# Consultar o tempo restante para a chave expirar (em milisegundos):
PTTL cadastro_cliente_1001
(integer) 12025
# Apos os 20 segundos, ao consultar a chave e o TTL:
GET cadastro_cliente_1001
(nil)
TTL cadastro_cliente_1001
(integer) -2
PTTL cadastro_cliente_1001
(integer) -2
# Exemplo 3:
# Criar uma chave que expira em uma data-hora-minuto-segundo específico,
# com a definição em TIMESTAMP (unix-timestamp UTC):
# - Expirar em 2030-01-01 20:00:30 UTC (timestamp 1893528030)
SET md5_certificado "2e448cc4f5f04172825f478092872ff2" EXAT 1893528030
OK
# - Expirar em 2030-01-01 20:00:30 UTC (timestamp 1893528030) e 500 milisegundos
SET md5_certificado "2e448cc4f5f04172825f478092872ff2" PXAT 1893528030500
OK
# - Alterar a expiração para 2035-10-15 12:15:00 UTCP (timestamp 2076063300):
EXPIREAT md5_certificado 2076063300
(integer) 1
# - Alterar a expiração para 2035-10-15 12:15:00 UTCP (timestamp 2076063300) e 750ms:
PEXPIREAT md5_certificado 2076063300750
(integer) 1
# Exemplo 4:
# Criar uma chave como temporária, e em seguida torná-la permanete:
SET token_auth "xpto99113933" EX 900
OK
# Remover o TTL da chave:
PERSIST token_auth
(integer) 1
# Consultar TTL da chave:
TTL token_auth
(integer) -1
# Verificar seu valor:
GET token_auth
"xpto99113933"
SET…KEEPTTL: Gerindo TTL de chaves existentes
Definir o valor de uma chave existente acaba por remover o TTL da mesma e resulta na transformação de uma chave temporária em perpétua, o que pode ser indesejado. O argumento KEEPTTL serve para redefinir o valor sem redefinir ou apagar seu TTL. Veja os exemplos abaixo:
# Exemplo 1:
# Criar uma chave temporária, tempo de vida em 45 segundos:
SET client_1010_password "tulipa" EX 45
OK
# Verificante tempo restante para expiração:
TTL client_1010_password
(integer) 41
# Alterando valor da chave:
SET client_1010_password "perola"
OK
# Perdeu-se o TTL e a chave se tornou perpétua:
TTL client_1010_password
(integer) -1
# Definindo o TTL para 45s
# - Renovar? Redefinir o TTL viola o compromisso feito na criação da chave.
EXPIRE client_1010_password 45
(integer) 1
# Exemplo 2:
# Criar uma chave temporária:
SET client_1020_password "123mudar" EX 600
OK
# Alterando a chave sem alterar o limite de tempo definido na criação:
SET client_1020_password "pocoio123" KEEPTTL
OK
# Conferindo o valor:
GET client_1020_password
"pocoio123"
# Conferindo o TTL restante:
TTL client_1020_password
(integer) 573
# Após 10 minutos:
GET client_1020_password
(nil)
SET…NX: Não sobrescrever valor existente
O argumento “NX” serve como condicional “só se intrometa na chave se ela não existir”, semelhante ao “CREATE IF NOT EXISTS” do SQL.
Um exemplo prático é a reserva de um assento no cinema. O primeiro usuário que reserva o assento impede que outro usuário faça tal reserva por cima.
# Exemplo 1:
# Reservar a cadeira H3 para o CPF 123.654.789-00
SET cinema_sala:014_sessao:9912_cadeira:h03 "123.654.789-00"
OK
# Tentar reservar cadeira H3 para o CPF 987.789.777-11
SET cinema_sala:014_sessao:9912_cadeira:h03 "123.654.789-00" NX
OK
# Verificar quem pegou a reserva primeiro:
GET cinema_sala:014_sessao:9912_cadeira:h03
"123.654.789-00"
SET…XX: Somente sobrescrever valor existente
O comando SET usado com o argumento XX faz o contrário do argumento NX. O XX informa ao REDIS que a ordem de definir o valor só deve ser obedecido se a chave existir.
Se a chave não existir ela não será criada.
Um exemplo do uso do XX é quando você pretende atualizar dados constantes de um evento que está sendo monitorado, mas se o evento for encerrado e ainda chegarem atualizações elas devem ser ignoradas para não reviver o evento (como um UPDATE de uma sessão RADIUS que já sofreu ACCT-STOP).
# Exemplo 1:
# Iniciando uma sessao (criar somente se ela não existir):
SET radius_session:282747272:txpackets "1" NX
OK
# Atualizando a sessão (atualizar apenas se ela ja existir):
SET radius_session:282747272:txpackets "384828" XX
OK
# Finalizando a sessao (dados ja foram salvos no SQL, dispensar do REDIS):
DEL radius_session:282747272:txpackets
(integer) 1
# Atualizando a sessão deletada (não criará a chave inexistente):
SET radius_session:282747272:txpackets "384828" XX
(nil)
FLUSHALL: Limpar tudo e começar do zero
Esse comando deve ser usado apenas em ambientes REDIS para puro cache intermediário.
Em ambientes com uso de RDB/AOF onde o REDIS é usado como banco de dados principal, usar o FLUSHALL é semelhante a dar um “DROP DATABASE” ou “SELECT sem WHERE”, use com cuidado ou nem use!
# Limpando a memória do REDIS e apagando todas as chaves
FLUSHALL
OK
5 – Armazenando listas simples
As listas simples são um tipo de dados (chaves e valores) que ocupam um pavilhão diferente do REDIS e possuem seus próprios comandos de CRUD. Não é mais possível usar SET, GET, DEL aqui. Você irá aprender novos comandos que fazem as operações nas chaves de lista.
Prévia do capítulo
- RPUSH: adiciona um item no final da lista;
- LPUSH: adiciona um item no inicio da lista, move os itens existentes para baixo;
- RPOP: remove e retorna o último elemento da lista (coleta e retirada do último item);
- LPOP: remove e retorna o primeiro elemento da lista (coleta e retirada do primeiro item);
- LLEN: retorna o número de itens da lista;
- LRANGE: retorna uma faixa de itens da lista;
- LINDEX: retorna o item que consta no índice informado;
- LINSERT: Insere um novo item na lista antes ou depois de um item existente;
- LREM: Remove um ou mais itens baseado na busca pelo seu valor exato;
- LTRIM: Truncar lista, remove todos os itens que não estejam na faixa especificada;
- DEL: apaga a chave da lista simples (deletar lista);
Qual propósito das listas simples
A ideia de usar listas em vez de chaves simples é gerir os membros da lista pelo seu número de índice. Esse tipo de dado é simples o suficiente para gerir filas de mensagens, notificações, tarefas que podem ser removidas a medida que são coletadas pelo programa que vai cuidar delas.
Dica: Recomendo que você não inicie o uso das listas até concluir a leitura dos próximos capítulos que apresentam as listas SET e listas HASH, principalmente as listas HASH. Se sua necessidade for integração em tempo real, não deixe de ler sobre PUB/SUB e Streams no REDIS.
Ao manipular listas adicionando ou removendo itens, observe o retorno numérico, ele informa quantos itens tem na lista após a operação.
As listas possuem uma peculiaridade: os índices EXIBIDOS são inteiros de 1 em diante, mas as consultas e comandos devem considerar de 0 (zero) ao último índice exibido menos 1. Exemplo: ao criar uma lista de 50 itens, o retorno da lista exibirá de 1 a 50, mas para manipulá-los você deve considerar de 0 a 49. A mesma lógica do SETRANGE e GETRANGE.
RPUSH, LRANGE, LLEN, LINDEX: Usando as listas na prática
# Exemplo 1 - Lista de compras
# Criar lista adicionando itens um apos o outro:
RPUSH compras "Ovos"
(integer) 1
RPUSH compras "Leite"
(integer) 2
RPUSH compras "Pano de chao"
(integer) 3
# Lista na memoria baseando-se no retorno dos comandos:
# "compras"
# indice de manipulação | valor
#------------------------------------
# 0 | Ovos
# 1 | Leite
# 2 | Pano de chao
#-------------------------------------
# Obter número de itens na lista:
LLEN compras
(integer) 3
# Visualizando a lista (0 a total-1, -1 em si representa o último item):
LRANGE compras 0 -1
1) "Ovos"
2) "Leite"
3) "Pano de chao"
# Obter item específico pelo índice interno (0 a total menos 1):
LINDEX compras 0
"Ovos"
LINDEX compras 1
"Leite"
LINDEX compras 2
"Pano de chao"
# Ao tentar obter um número de índice que não existe:
LINDEX compras 3
(nil)
# Obtendo primeiro item (índice 1 do retorno, índice 0 na lista)
LRANGE compras 0 0
1) "Ovos"
# Obtendo segundo item:
LRANGE compras 1 1
1) "Leite"
# Obtendo terceiro item:
LRANGE compras 2 2
1) "Pano de chao"
# Obtendo o primeiro e segundo item:
LRANGE compras 0 1
1) "Ovos"
2) "Leite"
# Obtendo último item:
LRANGE compras -1 -1
1) "Pano de chao"
# Obtendo os dois últimos itens:
LRANGE compras -2 -1
1) "Leite"
2) "Pano de chao"
# Apagar a lista:
DEL compras
(integer) 1
# Recriar a lista num único comando:
RPUSH compras "Ovos" "Leite" "Pano de chao"
(integer) 3
RPUSH, LPUSH, LPOP, RPOP, LREM, LINSERT: Adicionar e remover elementos da lista
Para adicionar itens na lista com RPUSH e LPUSH, e remover itens com LPOP e RPOP, devemos ficar atentos para não remover por acidente ou duplicar itens.
# Exemplo 1 - Lista de animais, usando rpush
RPUSH animais "Anta"
(integer) 1
RPUSH animais "Babuino" "Carneiro"
(integer) 3
RPUSH animais "Dromedalio" "Elefante" "Foca"
(integer) 6
RPUSH animais "Gurila" "Hiena" "Impala" "Jaguatirica" "Krill" "Mamute"
(integer) 12
LRANGE animais 0 -1
1) "Anta"
2) "Babuino"
3) "Carneiro"
4) "Dromedalio"
5) "Elefante"
6) "Foca"
7) "Gurila"
8) "Hiena"
9) "Impala"
10) "Jaguatirica"
11) "Krill"
12) "Mamute"
# Obter e remover o primeiro item (remove "Anta"):
LPOP animais
"Anta"
# Obter e remover o ultimo item (remove "Mamute"):
RPOP animais
"Mamute"
# Exemplo 2 - Lista de nomes, usando lpush
LPUSH nomes "Ana"
(integer) 1
LPUSH nomes "Bruno" "Carolina"
(integer) 3
LPUSH nomes "Diana" "Eliane" "Francisco" "Geraldo"
(integer) 7
LPUSH nomes "Henrique" "Iolanda" "Juliano" "Kaleb" "Marlon" "Naiara"
(integer) 13
LRANGE nomes 0 -1
1) "Naiara"
2) "Marlon"
3) "Kaleb"
4) "Juliano"
5) "Iolanda"
6) "Henrique"
7) "Geraldo"
8) "Francisco"
9) "Eliane"
10) "Diana"
11) "Carolina"
12) "Bruno"
13) "Ana"
# Obter e remover o primeiro item (remove "Naiara"):
LPOP nomes
"Naiara"
# Obter e remover o ultimo item (remove "Ana"):
RPOP nomes
"Ana"
# Verificar lista de nomes atualizada:
LRANGE nomes 0 -1
1) "Marlon"
2) "Kaleb"
3) "Juliano"
4) "Iolanda"
5) "Henrique"
6) "Geraldo"
7) "Francisco"
8) "Eliane"
9) "Diana"
10) "Carolina"
11) "Bruno"
# Remover buscando valor exato do item (-1 = última ocorrencia): apagando "Marlon"
LREM nomes -1 "Marlon"
(integer) 1
# Remover buscando valor exato do item (1 = primeira ocorrencia): apagando "Iolanda"
LREM nomes 1 "Iolanda"
(integer) 1
# Remover buscando valor exato do item (0 = todas as ocorrencia): apagando "Bruno"
LREM nomes 0 "Bruno"
(integer) 1
# Verificar lista de nomes atualizada:
LRANGE nomes 0 -1
1) "Kaleb"
2) "Juliano"
3) "Henrique"
4) "Geraldo"
5) "Francisco"
6) "Eliane"
7) "Diana"
8) "Carolina"
# Truncando a lista: mantem apeans itens do início da lista, índice 0 a 2 (3 itens apenas)
LTRIM nomes 0 2
OK
# Verificar lista de nomes atualizada:
LRANGE nomes 0 -1
1) "Kaleb"
2) "Juliano"
3) "Henrique"
# Substituir item da lista pelo índice (0="Kaleb", alterar para "Kaleb Silva":
LSET nomes 0 "Kaleb Silva"
OK
# Insere "Judiscleide" após "Juliano"
LINSERT nomes AFTER "Juliano" "Judiscleide"
(integer) 4
# Insere "Ingrid" antes de "Henrique"
LINSERT nomes BEFORE "Henrique" "Ingrid"
(integer) 5
# Verificar lista de nomes atualizada:
LRANGE nomes 0 -1
1) "Kaleb Silva"
2) "Juliano"
3) "Judiscleide"
4) "Ingrid"
5) "Henrique"
Tempo de vida da lista simples
Por padrão, toda lista é permanente – não possui TTL.
Somente a lista inteira pode ter ou não tempo de vida, os itens da lista não tem propriedades avulsas de tempo de vida.
Listas não suportam recursos condicionais como NX e XX.
Para tornar uma lista temporária você precisa usar os comandos EXPIRE ou PEXPIRE.
Consulte o TTL restante com os comandos TTL ou PTTL.
Se quiser remover o TTL, use o comando PERSIST.
# Criando lista:
RPUSH tarefas "Retirar o lixo" "Limpar canil" "Varrer o corredor"
(integer) 3
# Consultando TTL: por padrão as listas são permanentes
TTL tarefas
(integer) -1
# Atribuindo um TTL em segundos:
EXPIRE tarefas 1200
(integer) 1
# Consultando o TTL:
TTL tarefas
(integer) 1138
# Removendo o TTL da lista:
PERSIST tarefas
(integer) 1
# Conferindo se o TTL foi removido (-1 significa que não tem TTL):
TTL tarefas
(integer) -1
6 – SETs – Listas sem duplicação
Os SETs são listas muito parecidas com as listas simples mas possuem um recurso adicional: não permitem que membros (itens) sejam duplicados. Os itens são chamados de “membros” da SET.
Outro detalhe é que os SETs não lidam com ordem do membros – não há índice – logo não há como inserir membros no inicio ou no fim da lista, eles são posicionados desordenadamente. Se você quiser a lista de membros ordenados (numérica ou alfabética) você deve fazer isso na linguagem de programação que faz uso da SET.
Os membros das listas SETs devem ser referidos pelo valor exato do item, uma vez que ele é único.
SETs são uma ótima forma de gerir tarefas únicas sem se preocupar com repetições acidentais!
A expiração ou persistência da SET é controlada pelos comandos EXPIRE, PEXPIRE e PERSIST, assim como as demais chaves anteriores.
Dica: use as listas SETs para armazenar nome de chaves de outros tipos que armazenam dados mais complexos e completos (como o JSON do valor a ser tratado, outras listas e SETs, etc…).
Cuidado: nomes de membros são case-sensitive, “Joana” e “joana” não são a mesma palavra.
Prévia do capítulo
- SADD: Adiciona um ou mais itens na lista;
- SMEMBERS: Retorna todos os elementos da lista (puxar lista);
- SISMEMBER: Verifica se um item existe na lista (retorno boleano);
- SRANDMEMBER: Retorna um membro aleatório da lista (não remove);
- SCARD: Retorna o número de membros da lista;
- SMOVE: Move um membro de uma lista para outra;
- SUNION: Retorna a lista de membros de várias SETs reunidas;
- SINTER: Retorna os itens em comum entre as listas;
- SDIFF: Retorna membros que diferem nas listas;
- SREM: Remove um item da lista;
- SPOP: Remove e retorna um ou mais membros da lista aleatoriamente;
- DEL: apaga a chave da lista SET (deletar lista);
Usando SETLISTs
Exemplos de uso de listas SET:
# Criando SET:
# - o comando SADD retorna o número de novos membros adicionados na lista
SADD systasks "cookie_check" "temp_files" "session_timeout" "reboot" "update"
(integer) 5
# Quantidade de membros da SET:
SCARD systasks
(integer) 5
# Obter lista de membros da SET:
SMEMBERS systasks
1) "cookie_check"
2) "temp_files"
3) "session_timeout"
4) "reboot"
5) "update"
# Tentar adicionar um membro que ja existe:
SADD systasks "cookie_check"
(integer) 0
# Adicionar um novo membro:
SADD systasks "auto_clean"
(integer) 1
# Verificar se um membro existe (um membro que existe):
SISMEMBER systasks cookie_check
(integer) 1
# Verificar se um membro existe (um membro que não existe):
SISMEMBER systasks cookie_flush
(integer) 0
# Removendo um membro existente:
SREM systasks cookie_check
(integer) 1
# Removendo um membro inexistente:
SREM systasks cookie_check
(integer) 0
# Remover 1 membro aleatoriamente (retorna o membro removido):
SPOP systasks 1
1) "temp_files"
# Obter um 1 membro aleatoriamente:
SRANDMEMBER systasks
"session_timeout"
SRANDMEMBER systasks
"update"
SRANDMEMBER systasks
"auto_clean"
# Mover um membro de uma lista (systasks) para outra (donetasks):
# - Se a lista de destino não existir a SET será criada
# - Se o membro já existir na lista de destino ele será removido da SET de origem
SMOVE systasks donetasks "update"
1) "update"
# Mover um membro que não existe retorna 0 (false)
SMOVE systasks donetasks "update"
(integer) 0
# Transformando SET permanente em temporaria:
EXPIRE systasks 3600
(integer) 1
# Conferindo TTL:
TTL systasks
(integer) 3595
# Removendo o TTL da lista:
PERSIST systasks
(integer) 1
# Conferindo se o TTL foi removido (-1 significa que não tem TTL):
TTL systasks
(integer) -1
Operações com coleções de SETs
Combinando listas SETs por meio de comparações, diferenciações e junções. Exemplos:
# Criar SET para lista de usuarios online
SADD online_users "amanda" "admin" "suporte01" "suporte02"
# Criar SET de usuarios que logaram no sistema recentemente:
SADD last_users "estagiario01" "estagiario02" "sobrinho_do_chefe" "suporte02"
# Criar SET de usuarios bloqueados:
SADD blocked_users "xpto" "analista_formado"
# Criar lista de usuarios demitidos
SADD fired_users "joao" "matias" "suporte02"
# Obter os membros das duas listas
SUNION online_users last_users blocked_users
1) "amanda"
2) "admin"
3) "suporte01"
4) "suporte02"
5) "estagiario01"
6) "estagiario02"
7) "sobrinho_do_chefe"
8) "xpto"
9) "analista_formado"
# Gerar nova lista SET com o resultado da união (SUNION) de listas:
SUNIONSTORE recent_users online_users last_users
(integer) 7
SMEMBERS recent_users
1) "amanda"
2) "admin"
3) "suporte01"
4) "suporte02"
5) "estagiario01"
6) "estagiario02"
7) "sobrinho_do_chefe"
# Obter membros em comum nas listas (estão contidos)
# - Membro que existe em todas as listas SETs referidas
SINTER online_users last_users
1) "suporte02"
# Obter membros em comum nas listas (não há nenhum):
SINTER online_users last_users blocked_users
(empty array)
# Gerar nova lista SET baseado no resultado da SINTER de listas:
SINTERSTORE users_to_check online_users last_users
(integer) 1
# Membros que diferem nas listas (não estão contidos)
# - Membro que consta em uma lista mas não consta na outra
SDIFF online_users last_users
1) "amanda"
2) "admin"
3) "suporte01"
# Gerar nova SET com o resultado da diferença entre sets (SDIFF):
SDIFFSTORE offline_recent_users online_users last_users
(integer) 3
SMEMBERS offline_recent_users
1) "amanda"
2) "admin"
3) "suporte01"
Esses foram todos os comandos que envolvem listas SET, simples e pontual, a melhor maneira de lidar com entradas bem identificadas.
7 – Listas em chave HASH: campos e seus valores
Já estudamos as listas simples (itens numerados), em seguida as listas SET (membros singulares), agora temos a lista HASH, que é capaz de armazenar campos com valores.
A lista HASH mantem a característica de unicidade dos membros, assim como as listas SET, a grande diferença é que agora temos um objeto no REDIS que se parece mais com um ARRAY bidimensional de 2 colunas.
Temos agora um tipo de dado ideal para salvar cadastrados de clientes e registros completos, podemos ter uma lista com valores em JSON vinculados direto aos membros da lista (campo) em vez de referenciar outras chaves e isso reduz muito o número de operações, permitindo gerir uma única entidade no cache para todos os dados do objeto.
De agora em diante vou omitir o retorno dos comandos pois você ja entende o suficiente!
Prévia do capítulo
- HSET: preenche campos em uma chave HASH, cria a chave se não existir;
- HGET: obter o valor do campo dentro de uma chave HASH;
- HGETALL: obter todos os campos de uma chave HASH;
- HSETNX: semelhante a operação SET..NX, só adiciona o campo se ele não existir dentro da chave HASH;
- HEXISTS: confere se um campo existe dentro da chave HASH;
- HMGET: obter um ou vários campos específicos dentro de uma chave HASH;
- HDEL: deletar um ou mais campos dentro da chave HASH;
- HLEN: retorna o número de campos dentro de uma chave HASH;
- HKEYS: retorna a lista de campos (nome dos campos apenas) de uma chave HASH;
- HVALS: retorna a lista de valores (somente valores) dos campos de uma chave HASH;
- HINCRBY: incrementa ou decrementa o valor numérico (apenas inteiros) de um campo na chave HASH;
- HINCRBYFLOAT: incrementa ou decrementa o valor de um campo HASH numérico em ponto flutuante;
- HSCAN: realiza buscas mágicas nos campos da chave HASH;
- DEL: apaga a chave da lista HASH (deletar lista);
Usando listas HASH
# Criando lista HASH:
# Criar a chave HASH e preencher pelo menos 1 para de "campo"="valor"
HSET cliente:1 id 1
HSET cliente:1 nome "Patolino Silveira"
HSET cliente:1 nascimento "17/01/1990"
# Criar a chave HASH num único comando:
HSET cliente:2 id 2 nome "Felicia Martins" nascimento "27/02/1994"
# Obter todos os campos da chave HASH:
HGETALL cliente:1
1) "id"
2) "1"
3) "nome"
4) "Patolino Silveira"
5) "nascimento"
6) "17/01/1990"
7) "status_contratual"
8) "ATIVO"
# Adicionar um campo na HASH somente se o campo não existir:
# - Exemplos de operações que não vao ser executadas pois os campos ja existem:
HSETNX cliente:1 nascimento "01/01/1999"
HSETNX cliente:2 nascimento "01/01/1999"
# - Exemplos de operações que serão executadas pois os campos não existem ainda:
HSETNX cliente:1 status_contratual "ATIVO"
HSETNX cliente:2 status_contratual "PENDENTE"
# Conferindo campos especificos de chaves HASH:
HGET cliente:1 nascimento
"17/01/1990"
HGET cliente:2 nascimento
"27/02/1994"
# Tentando acessar chaves HASHs e campos que não existem:
HGET cliente:1 profissao
(nil)
HGET cliente:2 profissao
(nil)
# Conferir se um campo existe dentro da chave HASH:
# - Campo que existe:
HEXISTS cliente:1 nome
(integer) 1
# - Campo que não existe:
HEXISTS cliente:1 profissao
(integer) 0
# Obtendo vários campos no mesmo pedido:
HMGET cliente:1 nome nascimento status_contratual
1) "Patolino Silveira"
2) "17/01/1990"
3) "ATIVO"
# Obtendo vários campos envolvendo um campo que não existe:
HMGET cliente:1 nome nascimento status_contratual profissao
1) "Patolino Silveira"
2) "17/01/1990"
3) "ATIVO"
4) (nil)
# Removendo campo da chave HASH:
HDEL cliente:1 nascimento
(integer) 1
# Removendo um campo que não existe mais:
HDEL cliente:1 nascimento
(integer) 0
# Contar o número de campos que existe dentro de uma chave HASH:
HLEN cliente:1
(integer) 3
# Obter os campos (somente nome dos campos) de uma chave HASH:
HKEYS cliente:1
1) "id"
2) "nome"
3) "status_contratual"
# Obter os valores (somente valores) dos campos de uma chave HASH:
HVALS cliente:1
1) "1"
2) "Patolino Silveira"
3) "ATIVO"
# Manipulando contadores dentro da chave:
HSET cliente:1 nota_credito 1
# Incrementar contadores numéricos inteiros
# - Use valores positivos (1, ...) para incrementar
# - Use valores negativos para decrementar (-1, -2, ...)
HINCRBY cliente:1 nota_credito 5
(integer) 6
HGET cliente:1 nota_credito
"6"
# Incrementar contadores numéricos de ponto flutuante
HSET cliente:1 juros_mensal 1.5
(integer) 1
# Incrementando 0.75 ao valor atual do campo
HINCRBYFLOAT cliente:1 juros_mensal 0.75
"2.25"
# Fazendo buscas por campos e seus valores em uma chave HASH
# - Usado para chaves HASH com muitos campos
HSCAN cliente:1 0 MATCH n*
1) "0"
2) 1) "nome"
2) "Patolino Silveira"
3) "nota_credito"
4) "3"
# Definindo expiração da chave HASH (não é possivel expirar campos)
# - Expirar em 60 segundos:
EXPIRE cliente:1 60
(integer) 1
# Consultando tempo de vida da chave:
TTL cliente:1
(integer) 55
# Consultando tempo de vida da chave em milisegundos:
PTTL cliente:1
(integer) 52191
# Removendo TTL e voltando a chave para modo permanente:
PERSIST cliente:1
(integer) 1
# Apagando a chave:
DEL cliente:1
(integer) 1
8 – Sorted Lists – Listas de pontuações ordenadas
O REDIS tem um tipo de lista feita sob medida para sistemas de pontuação, muito utilizado pelas redes sociais, fóruns, chats e estatísticas para permitir acesso rápido a postagens e objetos com grande número de pontuações (curtidas, compartilhamentos, comentários).
Prévia do capítulo
- ZADD: insere um elemento na lista (cria a lista se ela não existir), define ou incrementa a pontuação do elemento;
- ZSCORE: consultar a pontuação de um elemento específico;
- ZCARD: obter o número total de elementos de uma lista;
- ZINCRBY: incrementa ou decrementa a pontuação de um elemento na lista;
- ZRANGE: obter a lista de elementos ordenados da menor para maior pontuação;
- ZREVRANGE: obter a lista de elementos ordenados da maior para menor pontuação;
- ZRANGEBYSCORE: obter a lista de elementos que tenham a pontuação dentro da faixa desejada, do menor para o maior;
- ZREVRANGEBYSCORE: obter a lista de elementos que tenham a pontuação dentro da faixa invertida desejada, do maior para o menor (tanto a faixa quanto a lista);
- ZREM: remover um elemento de uma lista pelo nome do elemento;
- DEL: apaga a chave da lista (deletar lista);
Usando listas ordenadas
Para melhor fixação, vou trabalhar em um exemplo de sistema de votação para presidente de uma associação de moradores! Nossa lista atuará como um resultado de urna eletrônica.
# Criando lista ordenada:
# Criar a chave e preencher pelo menos 1 elemento com "pontuação"="elemento"
# - ZADD retorna o número de elementos adicionados
# - Entrar com votos para presidente (pelo apelido do candidato)
# - Cadastrando um por um com sua pontuação inicial:
ZADD votacao:presidente 1 danilo_gentil
(integer) 1
ZADD votacao:presidente 1 polvo_honesto
(integer) 1
ZADD votacao:presidente 0 padre_exorcista
(integer) 1
# - Cadastrando vários ao mesmo tempo (sempre pontos seguidos do nome do elemento)
ZADD votacao:presidente 0 gorda_do_1001 1 corno_do_2003 3 sindico_corrupto
(integer) 3
# Cadastrar elemento já registrado resulta em substituição da pontuação:
# - Antes o polvo_honesto tinha 1 ponto, ao adicionar com 30 pontos ele passa a
# ter 30 pontos em vez de 31 (substituição do ZADD)
ZADD votacao:presidente 30 polvo_honesto
(integer) 0
# Obter pontuação de um elemento específico:
ZSCORE votacao:presidente padre_exorcista
"0"
# O ZADD permite o uso de INCR, NX e XX
# - INCR incrementa a pontuação informada na pontuação existente,
# sem o INCR a pontuação informado substitui a pontuação existente
ZADD votacao:presidente INCR 19 polvo_honesto
"49"
# ZADD + NX só adiciona o elemento se ele não existir
# - O elemento padre_exorcista já existe e pontuado com 13,
# o comando NX abaixo não será efetivado:
ZADD votacao:presidente NX 14 padre_exorcista
(integer) 0
ZSCORE votacao:presidente padre_exorcista
"0"
# - O elemento manicure_fofoqueira não existe, ele será inserido
# com a pontuação inicial informada
ZADD votacao:presidente NX 3 manicure_fofoqueira
(integer) 1
ZSCORE votacao:presidente manicure_fofoqueira
"3"
# ZADD + XX só efetiva a adição se o elemento já existir,
# - O elemento manicure_fofoqueira já existe pontuado com 3,
# substituir pontuação pela pontuação informada:
ZADD votacao:presidente XX 5 manicure_fofoqueira
(integer) 0
ZSCORE votacao:presidente manicure_fofoqueira
"5"
# ZADD + XX + INCR só efetiva a adição se o elemento já existir e incrementa a pontuação
# - O elemento manicure_fofoqueira já existe pontuado com 5,
# incrementar 7 na pontuação atual:
ZADD votacao:presidente XX INCR 7 manicure_fofoqueira
"10"
# Contar quantos elementos (candidatos no nosso caso) em uma lista:
ZCARD votacao:presidente
(integer) 7
# Incrementar pontuação de um elemento (valor atual + valor incrementado)
# - Retorna a nova pontuação do elemento
ZINCRBY votacao:presidente 47 "danilo_gentil"
"48"
ZINCRBY votacao:presidente 51 "polvo_honesto"
"81"
ZINCRBY votacao:presidente 13 "padre_exorcista"
"13"
ZINCRBY votacao:presidente 11 "gorda_do_1001"
"11"
ZINCRBY votacao:presidente 1 "corno_do_2003"
"2"
ZINCRBY votacao:presidente 39 "sindico_corrupto"
"42"
# Exibir conteúdo da lista pela pontuação crescente
# - Zero é o primeiro índice, -1 representa o último índice
# - Ordem do menos votado para o mais votado
ZRANGE votacao:presidente 0 -1 WITHSCORES
1) "corno_do_2003"
2) "2"
3) "gorda_do_1001"
4) "11"
5) "padre_exorcista"
6) "13"
7) "sindico_corrupto"
8) "42"
9) "danilo_gentil"
10) "48"
11) "polvo_honesto"
12) "81"
# Exibir conteúdo da lista pela pontuação crescente, somente nome dos elementos:
ZRANGE votacao:presidente 0 -1
1) "corno_do_2003"
2) "gorda_do_1001"
3) "padre_exorcista"
4) "sindico_corrupto"
5) "danilo_gentil"
6) "polvo_honesto"
# Exibir conteúdo da lista pela pontuação invertida:
# - Ordem do mais votado para o menos votado
ZREVRANGE votacao:presidente 0 -1 WITHSCORES
1) "polvo_honesto"
2) "81"
3) "danilo_gentil"
4) "48"
5) "sindico_corrupto"
6) "42"
7) "padre_exorcista"
8) "13"
9) "gorda_do_1001"
10) "11"
11) "corno_do_2003"
12) "2"
# Exibir conteúdo da lista pela pontuação invertida, somente nome dos elementos:
ZREVRANGE votacao:presidente 0 -1
1) "polvo_honesto"
2) "danilo_gentil"
3) "sindico_corrupto"
4) "padre_exorcista"
5) "gorda_do_1001"
6) "corno_do_2003"
# Exibir conteúdo da lista filtrando uma faixa de pontuação (na faixa 20 e 30)
# - Ordem do menos votado para mais votado
ZRANGEBYSCORE votacao:presidente 30 100 WITHSCORES
1) "sindico_corrupto"
2) "42"
3) "danilo_gentil"
4) "48"
5) "polvo_honesto"
6) "81"
# Exibir conteúdo da lista filtrando uma faixa de pontuação, somente nomes:
ZRANGEBYSCORE votacao:presidente 30 100
1) "sindico_corrupto"
2) "danilo_gentil"
3) "polvo_honesto"
# Exibir conteúdo da lista filtrando uma faixa de pontuação, lista invertida:
# - Ordem do mais votado para menos votado
# - A faixa deve ser informada contendo o maior valor primeiro
ZREVRANGEBYSCORE votacao:presidente 100 30 WITHSCORES
1) "polvo_honesto"
2) "81"
3) "danilo_gentil"
4) "48"
5) "sindico_corrupto"
6) "42"
# Exibir conteúdo da lista numa faixa de pontuação, lista invertida, apenas nomes:
ZREVRANGEBYSCORE votacao:presidente 100 30
1) "polvo_honesto"
2) "danilo_gentil"
3) "sindico_corrupto"
# Remover um elemento da lista (candidato desistiu da eleição!)
ZREM votacao:presidente "danilo_gentil"
(integer) 1
# Remover elementos pela posição na lista ordenada
# começando pelo menos votado
# - Lembre-se: lista é ordenada do menor para o maior
# - Zero (0) representa o menos votado, um (1) o segundo menos votado
# - Removendo do primeiro (0) ao segundo (1)
ZREMRANGEBYRANK votacao:presidente 0 1
(integer) 2
# Visualizando a lista apos retirar as duas menores pontuações:
ZRANGE votacao:presidente 0 -1 WITHSCORES
1) "padre_exorcista"
2) "13"
3) "sindico_corrupto"
4) "42"
5) "polvo_honesto"
6) "81"
# Remover elementos pela posição na lista ordenada invertida
# começando pelo mais votado
# - Lembre-se: lista invertida (*REV*) coloca a maior pontuação primeiro
# - Zero (0) representa o mais votado, um (1) o segundo mais votado
# - Removendo do primeiro (0) ao segundo (1)
ZREMRANGEBYRANK votacao:presidente 0 1
(integer) 2
# Exibir o primeiro item da lista invertida (ordenada pela maior pontuação)
# para descobrir o vencedor:
ZREVRANGE votacao:presidente 0 0 WITHSCORES
1) "polvo_honesto"
2) "81"
# Exibir o primeiro item da lista invertida, somente o nome do elemento:
ZREVRANGE votacao:presidente 0 0
1) "polvo_honesto"
# Colocar tempo de vida na lista ordenada:
EXPIRE votacao:presidente 86400
# Retirar TTL da lista ordenada (voltar como permanente):
PERSIST votacao:presidente
# Apagando a chave:
DEL votacao:presidente
(integer) 1
Concluímos os tipos mais comuns de chaves no REDIS, com esse conhecimento você cobrirá 90% de todas as implementações de REDIS.
9 – Configurando o REDIS (no host)
Apenas rodar o REDIS pode ser o suficiente para usá-lo, mas não é o suficiente para mantê-lo em segurança e previnir acessos indevidos.
Você não vai querer usar o REDIS como cache do seu banco de dados de clientes e qualquer BOT na Internet conseguir acesso e rapar todas as suas chaves, principalmente se houver dados sigiloso (senhas, cartão de crédito).
O Arquivo de configuração do REDIS é normalmente armazenado em /etc/redis/redis.conf
Vamos abordar as principais configurações.
# - bind: informa em quais IPs o REDIS escutará as requisições
# ao configurar apenas IPs de loopback (127.0.0.1 e ::1)
# o REDIS não abrirá a escuta nos IPs das interfaces de rede
# e estará exclusivo para uso interno do HOST
# Se voce colocar 0.0.0.0 e :: você abrirá o REDIS em todos
# os IPs e isso requerirá a implementação de autenticação.
bind 127.0.0.1 ::1
# Porta do REDIS
port 6379
# No modo protegido (yes), se você nao informar mecanismos de autenticação
# o REDIS não abrirá portas nos IPs das interfaces de rede.
protected-mode yes
# Número de conexões aguardando atendimento
tcp-backlog 511
# Tempo de inatividade antes de fechar a conexão com o cliente, 0=manter pra sempre
timeout 0
# Intervalo entre mensagens de keepalive para manter a conexão ativa,
# importante para impedir e quebra da conexão quando ela atravessa um NAT/CGNAT
tcp-keepalive 30
# Modo daemon, yes para rodar em background (modo HOST),
# no para rodar em foreground (importante no modo DOCKER para segurar o exec)
daemonize yes
# Arquivo para gravar o PID do processo
pidfile /run/redis/redis-server.pid
# Nivel de log, opcoes: debug, verbose, notice, warning
loglevel notice
# Arquivo de log para depurar eventos internos e erros
logfile /var/log/redis/redis.log
# Total de bases de dados suportadas (de 0 a 15)
# - 16 é o número máximo suportado
databases 16
# Nao exibir mensagem de saudação ao conectar no REDIS
always-show-logo no
# Alterar argumentos exibidos na lista de processos do Linux
set-proc-title yes
# Formato da nova mensagem de argumentos exibidos na lista de processos do Linux
# opcao util caso você informe a senha no argumento, assim ao modificar
# o argumento a senha deixa de ser exibida na lista de processos.
proc-title-template "{title} {listen-addr} {server-mode}"
# Modo de segurança de dados: ao colocar como yes o REDIS para
# de aceitar novas escritas se as rotinas que salvam os dados
# no disco derem eror
stop-writes-on-bgsave-error yes
#------------------------------------- RDB - Salvamento de dados
# Ativar o modo persistente do REDIS
# Ativar compressao de dados:
# - yes ativa compressão LZF (levemente mais lento, ocupa menos espaço em disco)
# - no grava os dados sem compressão (mais rápido mas ocupa mais espaço em disco)
rdbcompression yes
# Inserir checksum para impedir/detectar corrupção de registros no armazenamento
# - yes ajuda a evitar corrupções e panes entre restarts acidentais
# - no ajuda a deixar o salvamento em disco mais rápido, porem mais sensível a
# danos.
rdbchecksum yes
# Arquivo em disco onde as chaves de RAM serão salvas
dbfilename redis_6379_dump.rdb
# Deletar arquivo RDB danificado?
# - yes para deletar arquivos corrompidos e continuar sem eles,
# - no para manter o arquivo para analise e recuperações
# caso os dados sejam importantes
rdb-del-sync-files no
# Pasta onde os arquivos RDB serão gravados, prefira
# sempre informar uma pasta montada em um sistema de alta velocidade
# como SSD/NVME
dir /var/lib/redis/
#------------------------------------- AOF - Salvamento de dados
# Ativar modo AOF?
# - yes ativa o registro de todas as operações para recuperação exata
# - no deixa o modo AOF desativado (padrão)
appendonly no
# Arquivo de registro de todas operações
appendfilename "appendonly.aof"
# Sub-diretório onde os arquivos de AOF serão gravados no disco
# Esse diretório ficará dentro da pasta definida na config [dir]
# por padrão em: /var/lib/redis/ + [appenddirname]
# Caminho final: /var/lib/redis/appendonlydir/
appenddirname "appendonlydir"
# Frequencia de gravação das operações no AOF por meio de um pedido
# de sync() ao sistema operacional.
# - everysec: de 1 em 1 segundo
# - always: sempre que houver qualquer gravação de chaves ou expiração
# - no: deixar que o sistema operacional decida quando efetivar a escrita atrasada
appendfsync everysec
# Controlar se haverá pause na sincronização do AOF
# durante uma reescrita do arquivo.
# - yes pausa a sincronizacao durante reescritas, melhor desempenho mas
# abre a possibilidade da perda de dados se o servidor REDIS
# for desligado da energia durante a reescrita
# - no faz com que a reescrita não pause a chamada do sync() ao sistem aoperacional
# durante as reescritas
no-appendfsync-on-rewrite no
#( parei aqui )
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble yes
aof-timestamp-enabled no
replica-serve-stale-data yes
replica-read-only yes
repl-diskless-sync yes
repl-diskless-sync-delay 5
repl-diskless-sync-max-replicas 0
repl-diskless-load disabled
repl-disable-tcp-nodelay no
replica-priority 100
acllog-max-len 128
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no
lazyfree-lazy-user-del no
lazyfree-lazy-user-flush no
oom-score-adj no
oom-score-adj-values 0 200 800
disable-thp yes
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-listpack-entries 512
hash-max-listpack-value 64
list-max-listpack-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-listpack-entries 128
zset-max-listpack-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4096
stream-node-max-entries 100
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
jemalloc-bg-thread yes
10 – REDIS e a segurança
Temos quatro camadas de segurança para implementar em um ambiente REDIS:
- O firewall: protegerá o serviço evitando que endereços IPs externos ou não confiáveis iniciem conexões com a porta TCP do REDIS. Deixar a porta do REDIS aberta na Internet é perigosíssimo e é considerada uma falha grave;
- A criptografia na transmissão TCP/IP: visa proteger a informação em trânsito. Pacotes IP podem ser capturados na rede (sniffers, port-mirror) ou nos hosts envolvidos (eBPF, pcap, tcpdump, wireshard, …) e podem ser interceptadas e sequestradas (roubo de sessão e ataque man-in-the-middle). Opções:
- TLS surgiu na versão 1.0 em 1999, em 2006 saiu a versão 1.1, em 2008 a versão 1.2, e em 2018 saiu o padrão corrente TLS 1.3, prefira sempre usar TLS 1.3;
- O SSL foi descontinuado, logo, sempre que você encontrar o termo em algum software (Python por exemplo) ele na verdade quer dizer TLS;
- O uso de VPN entre os servidores pode simplificar o uso de criptografia entre os serviços pois acaba transferindo essa responsabilidade para a camada de baixo (IP ou Ethernet);
- A autenticação dos clientes: evitará que, mesmo com uso de criptografia (TLS), somente clientes com credenciais específicas (senha ou login e senha) possam fazer acesso para leitura e escrita de dados do serviço, atuando como uma camada adicional de controle;
- A criptografia dos valores das chaves: criptografar o valor das chaves para que outros clientes do mesmo REDIS não possam fazer uso dos dados que não lhe sejam pertinentes. Essa solução parece esquisita e pouco praticável, mas obrigatória para evitar vazamento de dados críticos nos pontos de captura:
- Dados na RAM: a memória RAM tem suas páginas extraídas no sistema que roda o REDIS ou no sistema abaixo da VPS/VM (hypervisor, KVM) e até mesmo nos circuitos eletrônicos da RAM (espionagem industrial avançada);
- Dados na SWAP: quando o SO resolve emular a RAM no disco, operações na memória virtual podem ir parar em setores do disco que mais tarde serão lidos;
- Dados persistentes: O backup (AOF, RDB) armazenado em disco cria um novo ponto de contato para o vazamento dessas informações caso esses arquivos sejam acessados por terceiros. As vezes o sistema é super seguro, mas o backup dele acaba em um pendrive ou em um disco armazenado em local inseguro fisicamente;
- Sincronização dos clusters: quando vários servidores REDIS estão em sincronia, qualquer um deles que for exposto ou comprometido levará ao vazamento de todas as chaves;
Exemplos de incidentes comuns quando os itens acima não são considerados:
- Ataque DDoS (SYN-FLOOD) na porta TCP do REDIS, impedindo que as aplicações conseguissem acesso remoto (REDIS na nuvem);
- Funcionário corrupto instalou sniffer vampiro (raspberry no cabo de rede) e capturou os pacotes IPs contendo chaves com cartões de crédito de uma aplicação que armazenava pagamentos no REDIS;
- REDIS sem senha em container, mesmo privado e local, permitiu que um usuário de dentro de um container vizinho se conectasse e puxasse todas as chaves e seus valores;
- Funcionário retirou um dos discos RAID 1 do servidor de backup, substitui por um novo disco, levou o disco removido para a casa e fez a leitura de todos os backups da empresa;
11 – Implementando Firewall
Não é escopo do artigo a construção dessas regras mas consulte seu especialista em segurança para implementar o firewall. Implementações de firewall e filtro TCP/IP:
- Firewall de borda de serviços: o mais indicado a ser feito. É um firewall provido pelo datacenter ou provedor que filtra pacotes antes do servidor;
- Firewall avançado: você pode desejar um firewall com DPI (deep packet inspect). Esse tipo de firewall é capaz de analisar cabeçalhos dos protocolos e prover um nível superior de deteção e bloqueio de ameaças. O datacenter ou provedor pode prover um appliance (físico ou máquina virtual) adicional para lhe fornecer esse recurso;
- Firewall do host: fazendo uso de iptables/nftables por meio de script próprio ou programa de firewall (ufw);
- Firewall do container: raramente utilizado mas o container pode ser construído com nftables e subir regras no ENTRYPOINT para permitir apenas IPs de origem específicos (e “DROP” no resto);
- Localhost only: quando executado direto no HOST (sem container), ele não deve abrir a porta TCP em IP público (IPv4 ou IPv6), assim ele se torna inalcançável pela Internet rodando apenas no IP de loopback (127.0.0.1 ou ::1);
- Intranet da STACK: o REDIS pode rodar sem porta redirecionada pelo Docker. Esse é o tipo de segurança de STACKs de aplicativos que fazem uso do REDIS mas não publicam porta externa para ele (Baserow por exemplo). O REDIS fica acessível na mesma rede (docker network) da STACK onde os containers conversam entre si em uma intranet totalmente privada;
A internet é uma selva, não entre nela sem proteção!
12 – Implementando TLS no REDIS
Vamos ativar TLS (Transport Layer Security) no servidor REDIS e seus clientes para que a comunicação TCP/IP seja segura com uso de criptografia moderna.
REDIS com TLS usando unidade certificadora local
Vamos criar uma CA (unidade certificadora) que emitirá os certificados (chaves públicas assinadas pela CA) para o servidor REDIS e para os clientes.
Nota importante: infelizmente o REDIS não suporta recursos de revocação de certificados:
- CRL – Certificate Revocation List: arquivo onde a CA armazena os certificados que foram revogados.
- OCSP – Online Certificate Status Protocol): método para conferir em tempo real o arquivo CRL. A CA fornece por meio de uma URL o CRL a todos os sistemas da organização, economizando o tempo gasta com a distribuição do CLR manualmente, e a reinicialização dos sistemas que fazem uso de TLS.
Se um cliente é comprometido (tem sua chave privada roubada ou é considerado não-confiável pela organização), devemos tornar notório que aquele certificado não é mais aceito. Como o REDIS não suporta CRL/OCSP, ficamos sem ter como impedir que um certificado revogado seja impedido de iniciar a conexão TLS – teremos um pirata conectado! Por conta disso não devemos ignorar a camada de autenticação por senha ou login/senha (veremos no próximo capítulo).
Em um ambiente de alta segurança, cada chave privada ficaria armazenada com seu dono e jamais estará exposta a outra pessoa, mesmo que essa pessoa seja de cima da hierarquia (a CA por exemplo), somente as chaves públicas com pedido de assinatura (CSR) e chaves públicas assinadas (CRT) são transmitidas entre os membros da organização. Os procedimento seguros são:
- O cliente que deseja obter um certificado gera localmente sua chave privada (.key) e a mantem protegida e segura;
- O cliente gera o arquivo de chave pública contendo os atributos que lhe são próprios (e-mail, nome, tipo de certificado desejado, etc…), esse arquivo se chama CSR (Cert-Sign-Request – requisição para assinatura de certificado). Embora o CSR seja a chave pública, essa chave pública não goza de confiança na organização, o arquivo CSR deve ser enviado para a CA;
- A CA (unidade certificadora) faz a assinatura digital do CSR do cliente, gerando assim um arquivo contendo:
- A chave pública do cliente;
- Os atributos aceitos pela CA e inseridos pela CA;
- O tipo, data, número de série e validade;
- Todos esses parâmetros geram um hash (sha256) que é assinado de forma que nenhum byte possa ser editado após a assinatura. A assinatura é realizada com a chave privada da CA e pode ser conferido com a chave pública da CA (ca.crt). O arquivo resultante é o CRT (certificado) do cliente que poderá ser aceito como confiável em toda a organização;
Como o exemplo é didático, vou armazenar todo mundo junto no mesmo servidor. Você e sua organização devem estabelecer protocolos e softwares para manter uma CA local.
Primeiramente, gere o arquivo Diffie-Hellman, ele auxilia a geração de chaves efêmeras durante as sessões:
# Adicional (não faz parte da CA nem dos certificados):
# - Gerar arquivo Diffie-Helman (gerador de chaves efêmeras)
[ -f /etc/redis/dh.pem ] || openssl dhparam -out /etc/redis/dh.pem 2048
Construindo uma CA simples auto-assinada:
# Criar diretório para gerenciar certificados e chaves privadas
mkdir -p /etc/redis/ca/certs
# - Gerar chave privada da CA - usar RSA de 2048 bits
cd /etc/redis/ca/
[ -f /etc/redis/ca/ca.key ] || \
openssl genrsa -out /etc/redis/ca/ca.key 2048
# - Gerar certificado auto-assinado da CA
cd /etc/redis/ca/
[ -f /etc/redis/ca/ca.crt ] || \
openssl req \
-x509 -new -nodes \
-key /etc/redis/ca/ca.key \
-sha256 \
-days 3650 \
-out /etc/redis/ca/ca.crt \
-subj "/CN=Redis-CA"
Gerando chaves e CRSs do servidor (server) e dos clientes (client):
# Função de geração de chave privada certificado assinado pela CA
generate_full_cert(){
cname="$1"
cdir="/etc/redis/ca/certs"
ckey="$cdir/$cname.key"
ccsr="$cdir/$cname.csr"
cert="$cdir/$cname.crt"
csbj="/CN=redis-$cname.intranet.br"
# - Ja existe, nada a fazer
[ -f "$ckey" -a -f "$cert" ] && return
# - Gerar chave privada do servidor
[ -p "$cdir" ] || mkdir -p "$cdir"
[ -f "$ckey" ] || openssl genrsa -out "$ckey" 2048
# - Gerar CSR do servidor
[ -f "$ccsr" ] || \
openssl req -new -key "$ckey" -out "$ccsr" -subj "$csbj"
# - Assinar CSR na CA e gerar o certificado
[ -f "$cert" ] || \
openssl x509 \
-req \
-in "$ccsr" \
-CA /etc/redis/ca/ca.crt \
-CAkey /etc/redis/ca/ca.key \
-CAcreateserial \
-out "$cert" \
-days 3650 \
-sha256
# - Ajustar posse da chave privada
chown redis:redis $ckey
}
# Gerar chave privada + certificado do servidor
generate_full_cert server
# Gerar chave privada + certificado do cliente
generate_full_cert client
Vamos usar o certificado “server” para o servidor REDIS, e o certificado “client” para o cliente de teste. Os clientes poderão se comunicar com o servidor de maneira totalmente segura: eles trocam chaves públicas, conferem a assinatura da CA no certificado um do outro, geram chaves efêmeras para criptografar os dados entre eles. Comunicação 100% segura.
Configurando o servidor REDIS para uso de TLS da CA local:
# - Caminho do certificado da CA
tls-ca-cert-file /etc/redis/ca/ca.crt
# - Caminho da chave privada e publica do servidor REDIS
tls-cert-file /etc/redis/ca/certs/server.crt
tls-key-file /etc/redis/ca/certs/server.key
# - Arquivo com parâmetros Diffie-Hellman para
# troca de chaves efêmeras
tls-dh-params-file /etc/redis/dh.pem
# - Travar segurança na versão corrente do TLS em 1.3
#tls-protocols "TLSv1.2 TLSv1.3"
tls-protocols "TLSv1.3"
# - Travar em cifras seguras para impedir downgrade de criptografia:
#tls-ciphersuites ECDHE-ECDSA-CHACHA20-POLY1305
tls-ciphersuites TLS_CHACHA20_POLY1305_SHA256:TLS_AES_256_GCM_SHA384
# Portas TCP:
# Você tambem pode manter:
# "port 6379" sem TLS e
# "tls-port 6380" com TLS, assim você atende o legado
# até que todos os clientes mudem para a porta TLS
#
# Se zerar a porta e configurar
# apenas a porta TLS, o REDIS fica 100% em modo TLS
# e não atenderá clientes sem criptografia TLS
#
# Operando na porta padrão com TLS:
port 0
tls-port 6379
#...Reinicie o servidor REDIS:
# Reiniciar REDIS rodando no HOST:
service redis restart
# Se for em container Docker:
docker restart NOME-CONTAINER-REDIS-AQUI
Vamos tentar conectar localmente usando redis-cli para observar que a conexão sem criptografia não funciona mais:
# Conectar no REDIS local:
redis-cli
127.0.0.1:6379> keys *
Error: Connection reset by peer
not connected> set a 1
Error: Connection reset by peer
not connected> quitIniciando a conexão no redis-cli usando as credenciais (certificado de CA para conferir a assinatura do certificado de chave pública, e a chave privada do cliente-001):
# Conectar no REDIS local com TLS, usando credenciais do client-001:
redis-cli --tls --cacert /etc/redis/ca/ca.crt -h 127.0.0.1 -p 6379 \
--cert /etc/redis/ca/certs/client.crt \
--key /etc/redis/ca/certs/client.key
set teste "Funcionou"
OKSempre que puder, faça uso do REDIS em modo TLS, mantenha os certificados e chaves seguros!
13 – REDIS no Docker
No mundo real, o REDIS é usado 99.99% do tempo em containers (Docker, Docker Swarm, Kubernets, …).
Preparativos e conceitos importantes
Você pode usar imagens oficiais (https://hub.docker.com/_/redis) ou criar suas imagens, o importante é dominar todas as configurações ensinadas até aqui e ficar atendo com os detalhes.
Uma coisa importante é a comunicação entre os containers pelos nomes. Sempre rode seus containers em redes específicas (parâmetro network), pois nas redes específicas os containers tem acesso via DNS interno (127.0.0.11) do Docker aos nomes e IPs dos containers na mesma rede.
Sempre nomeie bem seus containers. Assim você pode usar “http://redis-abcd/” em vez de precisar fixar e anotar IPs.
Exemplo:
# Criar uma rede específica:
docker network create network_db
# Criar containers de REDIS:
docker run -d --name redis-abcd --network network_db redis:7.4.1-alpine
docker run -d --name redis-xpto --network network_db redis:7.4.1-alpine
# Rodar o comando ping dentro do container 'redis-abcd'
# para pingar o container 'redis-xpto' pelo nome:
docker exec -it redis-abcd /bin/ash -c 'ping -c 4 redis-xpto'
PING redis-xpto (172.18.0.3): 56 data bytes
64 bytes from 172.18.0.3: seq=0 ttl=64 time=0.099 ms
64 bytes from 172.18.0.3: seq=1 ttl=64 time=0.066 ms
64 bytes from 172.18.0.3: seq=2 ttl=64 time=0.064 ms
64 bytes from 172.18.0.3: seq=3 ttl=64 time=0.067 ms
--- redis-xpto ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.064/0.074/0.099 ms
# Observe a resolução de nomes:
docker exec --user root -it redis-abcd ash -c 'cat /etc/resolv.conf'
# Generated by Docker Engine.
# This file can be edited; Docker Engine will not make
# further changes once it has been modified.
nameserver 127.0.0.11
options ndots:0
# Based on host file: '/etc/resolv.conf' (internal resolver)
# ExtServers: [4.2.2.2]
# Overrides: []
# Option ndots from: internal
Volumes e montagens: salvando dados e usando arquivos externos
O REDIS para somente cache e rodando sem mapeamento de portas não precisa de mais nada. Ele pode ser destruido, refeito, reiniciado, e nenhum dado é perdido pois ele armazena cache – cópia de informações que estão em outros locais.
Dentro de um container nenhum arquivo do HOST pode ser acessado. Todo container é uma jaula de binários descartáveis, que podem ser destruídos e reconstruídos a qualquer momento. Para que uma aplicação dentro de um container possa salvar dados ou ler arquivos persistente é por meio de montagens.
Essas montagens mapeiam um arquivo ou diretório do HOST dentro do container. Quando o container é destruido, o mapeamento é destruido, mas não o alvo do mapeamento no HOST.
Volumes nomeados (palavras simples, a-z0-9) são criados no HOST no caminho:
/var/lib/docker/volumes
Exemplo:
# Rodar um container do REDIS mapeando um volume a uma pasta dentro do container
# Obs.: use "-v" ou "--volume"
docker run \
-d \
--name redis-exemplo1 \
--network network_db \
--volume redis_data:/data \
redis:7.4.1-alpine
No exemplo acima, o diretório do HOST /var/lib/docker/volumes/redis_data/_data será mapeado dentro do container na pasta /data
Os volumes podem ser feitos da mesma forma usando o argumento “mount” do Docker, para mapear pastas mais específicas, exemplo:
# Criar diretório de storage de dados persistentes para todos os containers:
mkdir -p /storage
# Criar uma pasta especifica para o redis-exemplo2
mkdir -p /storage/redis-exemplo2
# Rodar um container com mapeamento específico
docker run \
-d \
--name redis-exemplo2 \
--network network_db \
--mount \
type=bind,source=/storage/redis-exemplo2,destination=/data,readonly=false \
redis:7.4.1-alpine
Montando arquivos específicos para uso no container, em vez de diretório:
# Criar uma pasta especifica para o redis-exemplo3
mkdir -p /storage/redis-exemplo3
# Arquivo de configuração do REDIS:
touch /storage/redis-exemplo3/redis.conf
# Arquivos das chaves:
touch /storage/redis-exemplo3/ca.crt
touch /storage/redis-exemplo3/server.key
touch /storage/redis-exemplo3/server.crt
# Rodar um container com mapeamento específico
docker run \
-d \
--name redis-exemplo3 \
--network network_db \
-v /storage/redis-exemplo3/redis.conf:/data/redis.conf \
-v /storage/redis-exemplo3/ca.crt:/data/ca.crt \
-v /storage/redis-exemplo3/server.key:/data/server.key \
-v /storage/redis-exemplo3/server.crt:/data/server.crt \
redis:7.4.1-alpine
# Conferindo os arquivos dentro do container:
docker exec -it redis-exemplo3 ash -c 'ls -lah /data/'
total 8K
drwxr-xr-x 2 redis redis 4.0K Jan 16 17:39 .
drwxr-xr-x 1 root root 4.0K Jan 16 17:39 ..
-rw-r--r-- 1 redis root 0 Jan 16 17:39 ca.crt
-rw-r--r-- 1 redis root 0 Jan 16 17:31 redis.conf
-rw-r--r-- 1 redis root 0 Jan 16 17:39 server.crt
-rw-r--r-- 1 redis root 0 Jan 16 17:39 server.key
Comando personalizado ao rodar o REDIS no container
Ao criar um container (“docker create” ou “docker run”) você pode, após o nome da imagem no final do comando, especificar qual será a programa (CMD) a ser executado dentro do container. Cada container tem seu CMD padrão (ou não). No caso do redis, o CMD padrão é simplesmente “redis-server”, mas podemos especificar outro comando ou o mesmo comando com argumentos.
Vou juntar os conceitos dos exemplos anteriores, extrapolar um pouco e especificar o CMD completo, observe:
# Criar uma pasta especifica para o redis-exemplo4
mkdir -p /storage/redis-exemplo4
# Pasta para dados RDB/AOF
mkdir -p /storage/redis-exemplo4/data
# Pasta e arquivo de configuração do REDIS:
mkdir -p /storage/redis-exemplo4/conf
touch /storage/redis-exemplo4/conf/redis.conf
# Obs: no redis.conf os arquivos de TLS devem
# ser buscados em /config/
# Pasta e arquivos das chaves:
mkdir -p /storage/redis-exemplo4/tls
touch /storage/redis-exemplo4/tls/ca.crt
touch /storage/redis-exemplo4/tls/server.key
touch /storage/redis-exemplo4/tls/server.crt
# Rodar um container com mapeamento específico de pasta e arquivos
docker run \
-d \
--name redis-exemplo4 \
--network network_db \
-v /storage/redis-exemplo4/data:/data \
-v /storage/redis-exemplo4/conf/redis.conf:/config/redis.conf \
-v /storage/redis-exemplo4/tls/ca.crt:/config/ca.crt \
-v /storage/redis-exemplo4/tls/server.key:/config/server.key \
-v /storage/redis-exemplo4/tls/server.crt:/config/server.crt \
redis:7.4.1-alpine \
redis-server /config/redis.conf
# Conferindo os arquivos dentro do container:
docker exec -it redis-exemplo4 ash -c 'ls -lah /config/'
total 8K
drwxr-xr-x 2 root root 4.0K Jan 16 17:49 .
drwxr-xr-x 1 root root 4.0K Jan 16 17:49 ..
-rw-r--r-- 1 root root 0 Jan 16 17:48 ca.crt
-rw-r--r-- 1 root root 0 Jan 16 17:48 redis.conf
-rw-r--r-- 1 root root 0 Jan 16 17:48 server.crt
-rw-r--r-- 1 root root 0 Jan 16 17:48 server.key
Mapeando porta externa na porta interna
O REDIS normalmente abre a porta 6379 dentro do container, o que significa que os containers na mesma rede (docker network) poderão acessar o container pelo nome na porta TCP/6379, esse é o conceito de “porta interna”.
Ao mapear no docker “-p 6379:6379” você mapeia a porta externa 6379 na porta interna 6379, mas esse mapeamento pode ser diferente, qualquer porta externa para qualquer porta interna, desde que a porta interna esteja aberta dentro do container por algum programa.
Você pode mudar essa porta interna (6001 por exemplo), como também pode mapea-la no HOST para acesso externo em outra porta (7001 por exemplo). Containers de outras redes e clientes vindos da Internet usarão a porta externa quando forem conectar no IP do HOST, e usarão a porta interna se estiverem no mesmo “docker network” do REDIS.
Também vamos alterar o CMD para que o redis-server rode com opções de persistência (AOF) e seja protegido por uma senha simples “TULIPA”. Observe (somando mais conceitos):
# Criar uma pasta especifica para o redis-exemplo4
mkdir -p /storage/redis-exemplo5
# Rodar um container com mapeamento específico de pasta e arquivos
docker run \
-d \
--name redis-exemplo5 \
--network network_db \
-p 7001:6001 \
-v /storage/redis-exemplo5:/data \
-e REDIS_PASSWORD=TULIPA \
redis:7.4.1-alpine \
redis-server \
--requirepass TULIPA \
--port 6001 \
--save 900 1 \
--save 300 10 \
--save 60 10000 \
--dir /data \
--appendonly yes \
--appendfilename "appendonly.aof"
# Conferindo os arquivos dentro do container:
docker exec -it redis-exemplo5 ash -c 'ls -lah /data/ /data/*'
/data/:
total 12K
drwxr-xr-x 3 redis root 4.0K Jan 16 19:11 .
drwxr-xr-x 1 root root 4.0K Jan 16 19:11 ..
drwx------ 2 redis redis 4.0K Jan 16 19:11 appendonlydir
/data/appendonlydir:
total 16K
drwx------ 2 redis redis 4.0K Jan 16 19:11 .
drwxr-xr-x 3 redis root 4.0K Jan 16 19:11 ..
-rw------- 1 redis redis 88 Jan 16 19:11 appendonly.aof.1.base.rdb
-rw------- 1 redis redis 0 Jan 16 19:11 appendonly.aof.1.incr.aof
-rw------- 1 redis redis 88 Jan 16 19:11 appendonly.aof.manifest
# Testando - Observe que precisa dar o AUTH com a senha para funcionar:
docker exec -it redis-exemplo5 redis-cli -p 6001
127.0.0.1:6001> set teste "xpto acme"
(error) NOAUTH Authentication required.
127.0.0.1:6001> auth TULIPA
OK
127.0.0.1:6001> set teste "xpto acme"
OK
Administrando REDIS pela WEB
Se você prefere administrar pela WEB em vez de conectar no terminal, o Redis-Commander é um software simples de usar e provê uma interface simples e pontual:
# Commander do Redis
# https://hub.docker.com/r/rediscommander/redis-commander
# Gestor de REDIS: radm / tulipa
#
# Instalar comando htpasswd:
apt-get -y install apache2-utils
# Gerar senha:
RADM=$(htpasswd -nb radm 'tulipa' | sed -e 's/\\$/\\$\\$/g')
undocker redis-commander
docker run \
-d --restart=always \
--name redis-commander -h radm.exemplo.com.br \
\
--env REDIS_HOSTS=REDIS-CACHE:10.140.255.151:6379,REDIS-DB:10.140.255.152:6379 \
\
--label "traefik.enable=true" \
--label "traefik.http.middlewares.radmauth.basicauth.users=$RADM" \
--label "traefik.http.routers.rediscmd.rule=Host(\`radm.exemplo.com.br\`)" \
--label "traefik.http.routers.rediscmd.entrypoints=websecure" \
--label "traefik.http.routers.rediscmd.tls=true" \
--label "traefik.http.routers.rediscmd.tls.certresolver=letsencrypt" \
--label "traefik.http.routers.rediscmd.middlewares=radmauth" \
--label "traefik.http.services.rediscmd.loadbalancer.server.port=8081" \
\
rediscommander/redis-commander:latest
Considerações
Lembre-se sempre de documentar suas implementações, produza um relatório pontual de tudo que você fez e salve em local seguro. O backup e a recuperação são tão importantes quanto a implementação.
Grato pela atenção,
Patrick Brandão – patrickbrandao@gmail.com