
Nesse tutorial vamos configurar 5 servidores (VPS, VM ou Bare) para atuar como cluster de servidores REDIS.
Cluster “é um grupo de servidores interconectados que trabalham juntos como um único sistema para aumentar a disponibilidade e o desempenho”.
O objetivo aqui é ter vários servidores REDIS rodando em diferentes computadores mas atuando como um único sistema que pode perder suas partes e continuar operacional de maneira transparente e sem downtime.
Pre-requisitos:
- Instalação do Linux (Debian) e programas básicos;
- Internet fixa no servidor para sincronismo com os servidores NTP;
- Vários servidores (VM, VPS ou Baremetal) diferentes;
- Conhecimento básico de REDIS:
- REDIS Guia Completo: https://blog.patrickbrandao.com/redis-guia-completo/
1 – Conceitos fundamentais de REDIS
O REDIS é um servidor de chave/valor. Tudo que você faz nele envolve armazenar uma chave que possui um valor. Existem vários tipos de chaves que definem o formato do valor (string, lista de itens, lista de objetos, …).
O conceito fixo e imutável é a chave, principalmente o nome da chave.
Ao armazenar a chave “cliente_19283_cadastro” (SET) em um servidor, basta consultar a mesma chave para extrair seu valor (GET).
# (cliente 1)
# Criar uma chave:
SET cli283_cad 'id=19283,nome=Patolino'
OK
# (cliente 2)
# Consultar valor da chave:
GET cli283_cad
"id=19283,nome=Patolino"
Ilustrando:
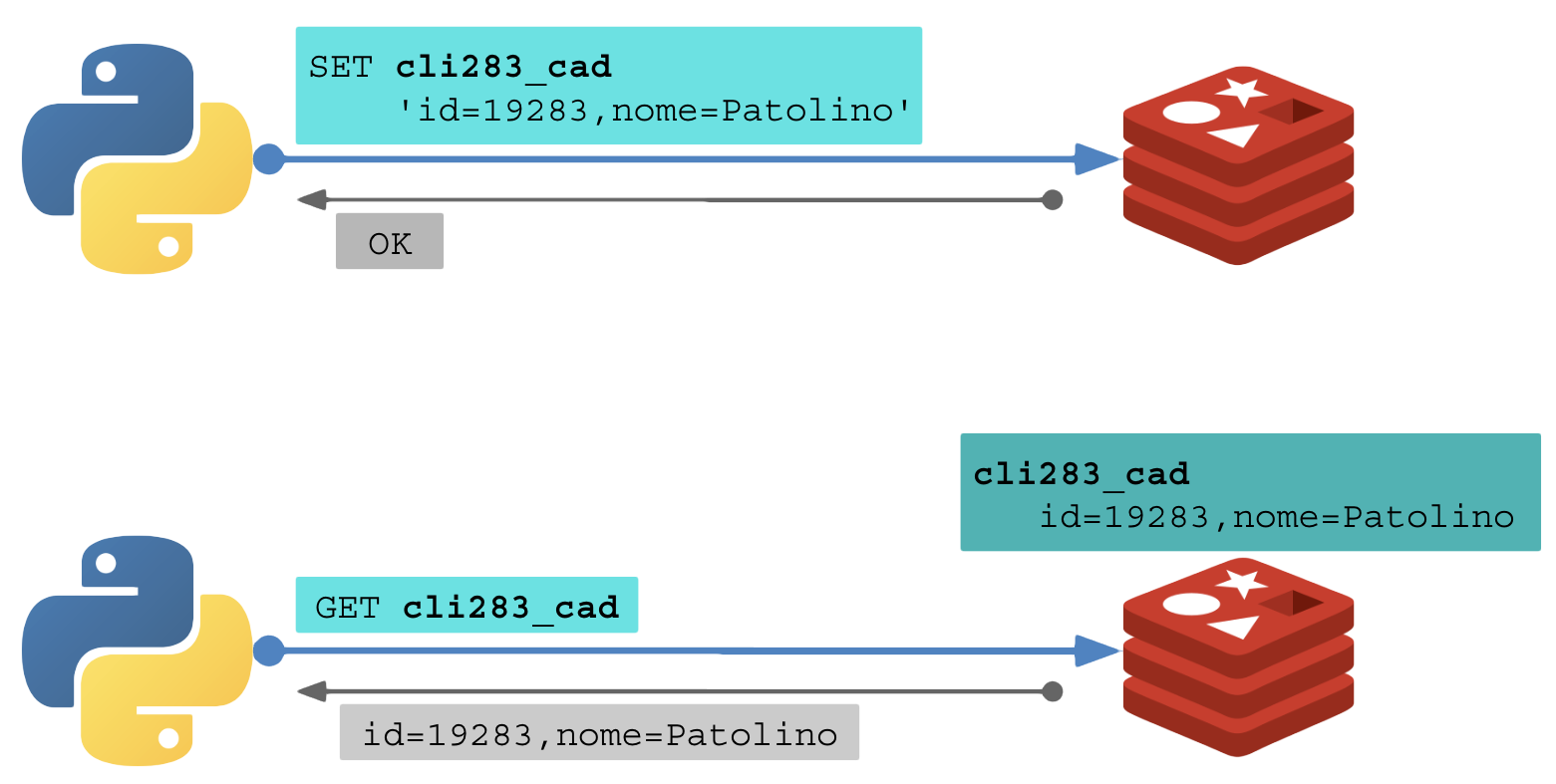
A maioria dos ambientes com Redis o executam em instância única.
Os sistemas o utilizam como cache ou banco de dados para compartilhar as chaves entre diferentes execuções e entre diferentes programas.
Exemplo: um sistema em Python que rode várias instâncias separadas mas que atendem os mesmos pedidos podem armazenar as informações no REDIS para garantir que seu clone vizinho economize o trabalho. Esse programas não conversam diretamente entre si, eles usam o Redis como caixa de objetos, arquivos, logs, mensageiro, etc.
O Redis é uma alternativa simples e rápida para dados cujo uso não seria viável com outros sistemas (SQL, NOSQL, Storage).
É muito comum encontrar sistemas (stack/composer) que sobem sua própria instância particular do REDIS, exemplo:
- ChatWoot: stack contendo administração, APIs, PostgreSQL e REDIS (#1);
- N8N: stack com editor, worker, webhook, PostgreSQL e REDIS (#2);
- APP em Python: stack com processo Python, PostgreSQL e REDIS (#3);
Nesses exemplos o REDIS é resiliente pela gestão do Docker Swarm com um pequeno downtime entre a queda e o reestabelecimento. Um problema comum é que as stacks dobram o overhead (mínimo de recursos consumidos para rodar o REDIS fica entre 80 a 200 MB).
Uma forma mais econômica para ambientes com muitas stacks é rodar uma única instância do REDIS e compartilhar seu acesso com vários clientes, dando a cada sistema um um banco de dados interno como forma de isolamento (ChatWoot no DB 11, N8N no DB 12, APP Python no DB 13, …).
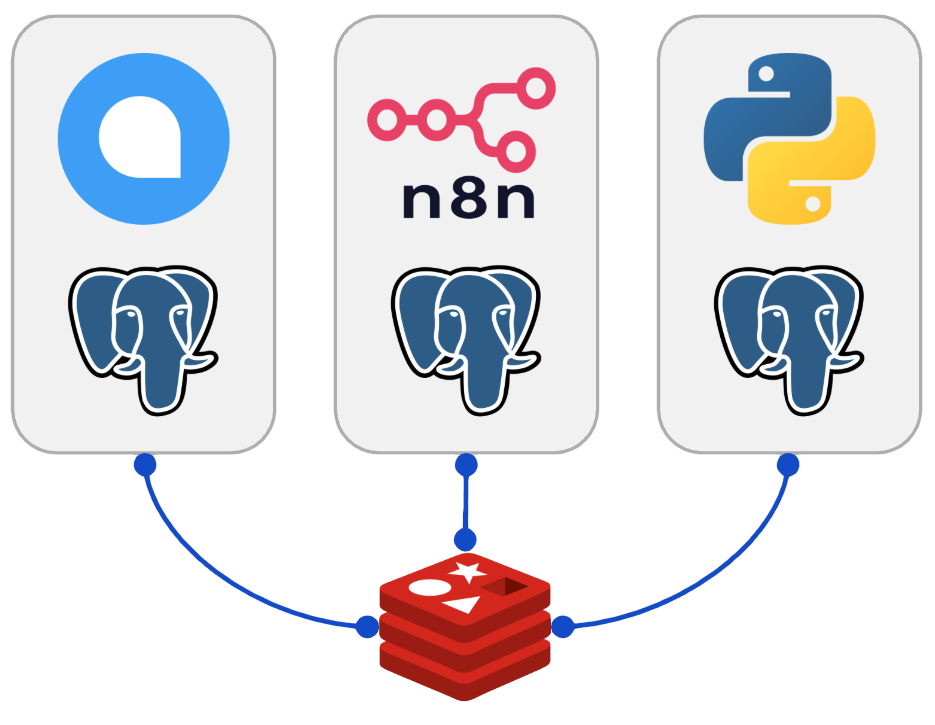
Esses programas podem rodar em qualquer lugar desde que tenham acesso ao IP do servidor REDIS.
Existem duas fragilidades em centralizar as aplicações em uma única instância do Redis:
- O Redis é um ponto único de falha. Um sistema que utilize PUB/SUB para se comunicar em tempo real com outros sub-sistemas ficarão 100% offline se essa instância do REDIS cair;
- O Redis é single-thread: se você possui um servidor/VPS com muitos núcleos, ele usará apenas 1 deles.
Problemas ao ter um REDIS parado:
- Todos os sistemas ficam prejudicados ou offline;
- Todas as chaves em RAM são perdidas;
- O trabalho salvo em cache é perdido;
- Sem o cache, um trabalho custoso precisará ser repetido a cada execução do software que antes era beneficiado pelo cache (carga maior de CPU/RAM/IO);
- Sistemas baseados em PUB/SUB saem do ar instantaneamente;
Problemas com o Redis single-thread:
- Se um único núcleo consegue entregar 20 mil requisições por segundo, esse será seu limite operacional, criando gargalos de performance;
Faz mais sentido, em um ambiente com vários servidores/VPS, que em cada servidor tenha uma instância do Redis que sincronize com as demais, isso resolve problemas e adiciona vantagens:
- Seu aplicativo pode mudar de “casa”: o software muda de lugar e ao chegar no novo servidor os dados já estão lá esperando por ele;
- Você não precisará de nenhuma tecnologia de cluster ou redundância por baixo adicionando complexidades, como:
- Cluster de hypervisor como o Proxmox, VMWare, …
- Cluster de containers como Kubernetes, Docker Swarm;
- Cluster de dados persistentes (Ceph, GlusterFS, rsync, …);
- Você não precisa de nenhuma rotina adicional alem do cluster Redis;
- Você não é impedido de usar nenhuma outra tecnologia de cluster como o Swarm para manter suas stacks, mas o REDIS terá seu cluster particular e mais eficiente.
- O balanceamento das chaves em várias instâncias contorna a limitação de performance single-thread;
Demonstração simplificada:
Vamos explorar a montagem desse cluster.
2 – Como funciona o Redis Cluster
O Cluster será formado por vários servidores REDIS atuando em parceria para fornecer um único serviço consistente. Vamos analisar os conceitos e algoritmos envolvidos.
2.1 – Sharding
Sharding (fragmentação) é o processo de dividir o conjunto de dados em pedaços menores e distribuí-los entre diferentes nós. Como se aplica ao Redis:
- O sharding usa um modelo de Hash Slots;
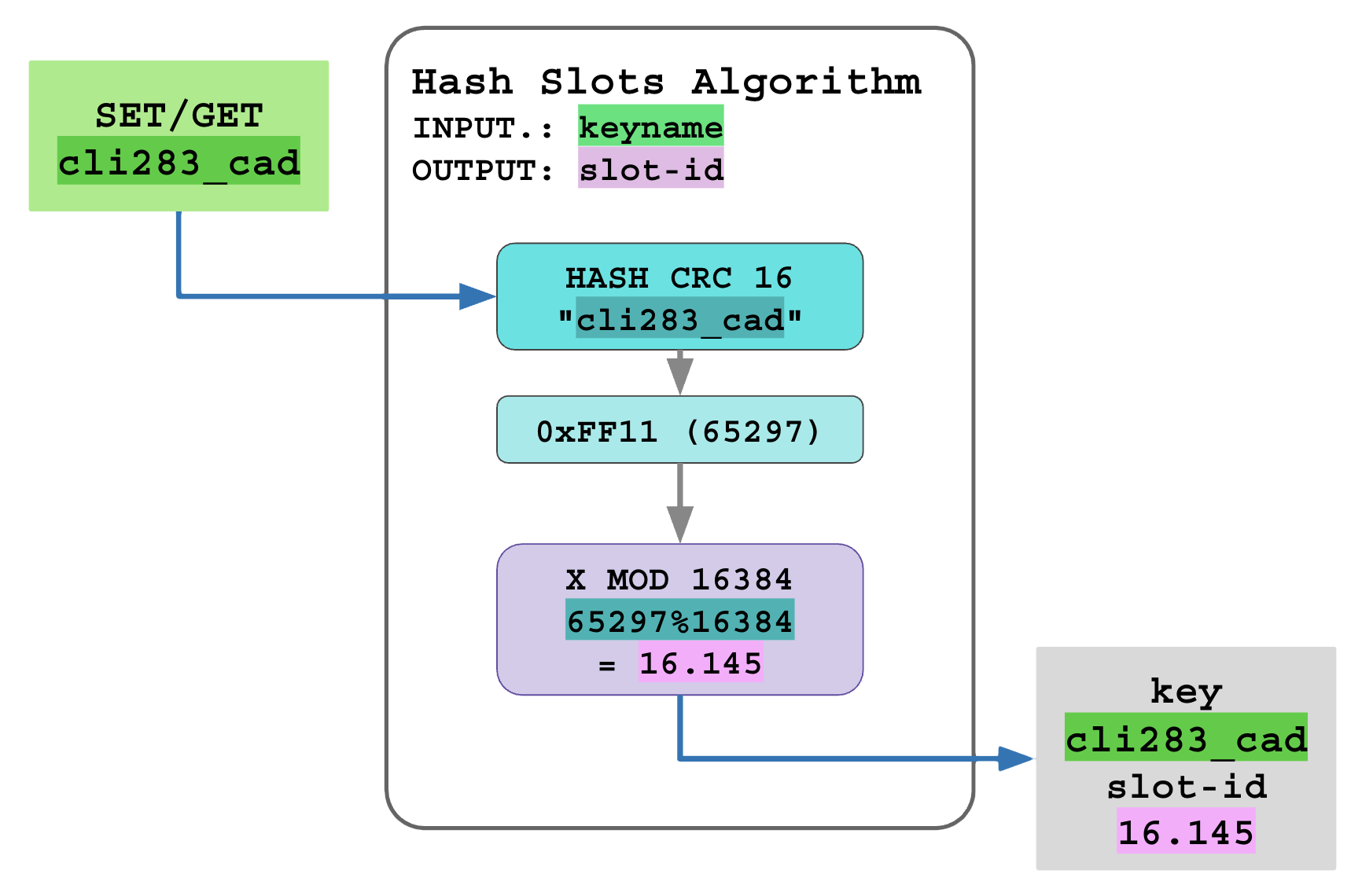
- Cada chave é mapeada para um slot específico usando os seguintes passo:
- O nome da chave é recebido e passa pela função CRC16, produzindo um número de 16 bits (0 a 65535),
- O número de 16 bits é dividido pela constante 16384 para isolar o resto da divisão (MOD, módulo), esse resto é o SLOD-ID,
- Essa combinação CRC16(keyname)%16384 distribui de maneira rápida e satisfatoriamente uniforme todas as chaves em números entre 0 e 16383.
Visualização do cálculo de SLOD-ID:
O segundo passo no Redis Cluster é selecionar qual dos servidores ficará responsável pela chave.
2.2 – Particionamento de Hash-Slots em Shard-Slots
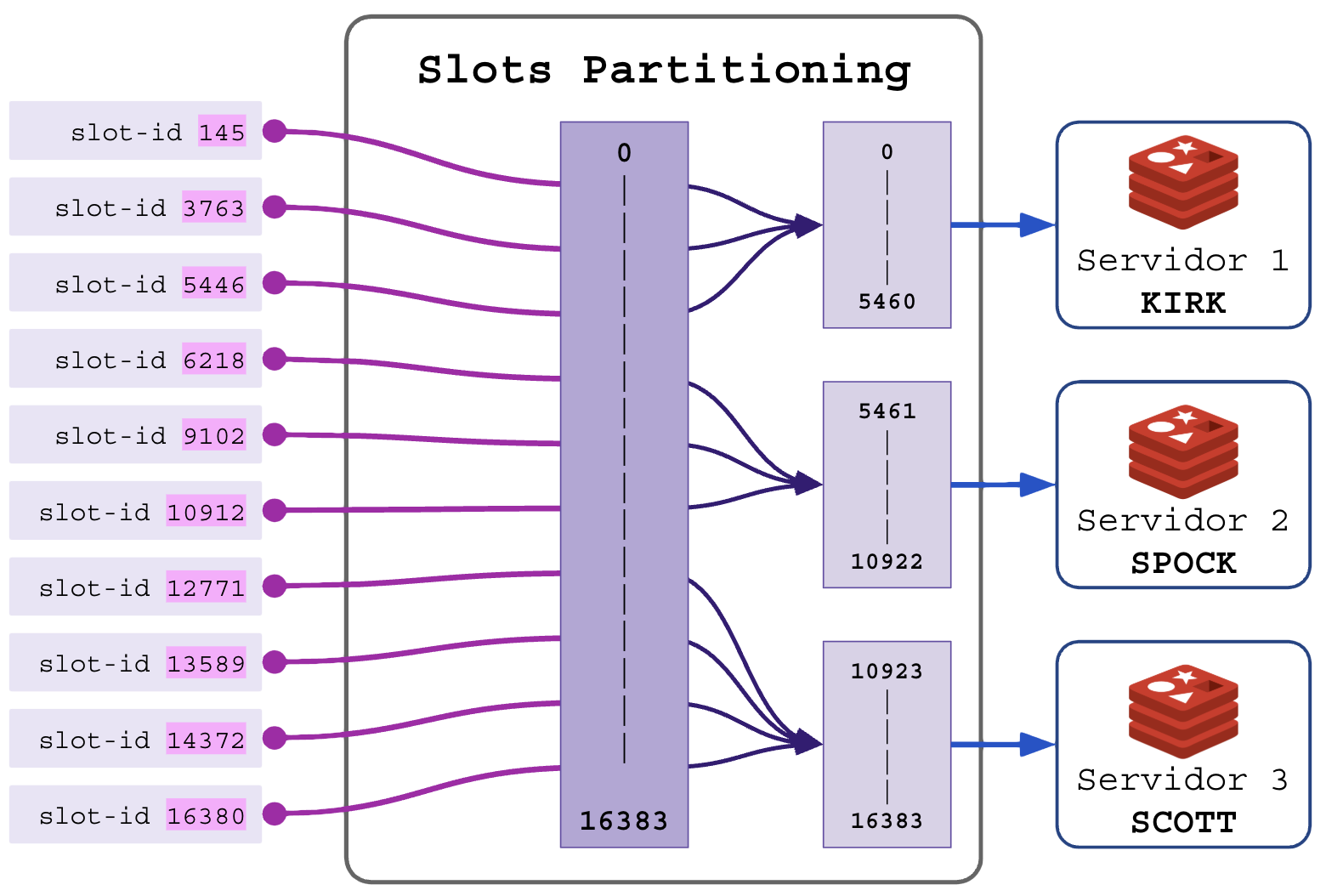
Os valores possíveis do SLOT-ID estão entre 0 e 16383 (16384 possibilidades). Podemos particionar esse range entre os servidores que formarão o cluster.
Divisão das partições (SHARD-SLOTS):
- Para cluster de 3 servidores (16384/3=5461 slots para cada):
- Servidor 1 gerencia slots 0-5460 (partição 1 de 3);
- Servidor 2 gerencia slots 5461-10922 (partição 2 de 3);
- Servidor 3 gerencia slots 10923-16383 (partição 3 de 3);
- Para cluster de 4 servidores (16384/4=4096 slots para cada):
- Servidor 1 gerencia slots 0-4095 (partição 1 de 4);
- Servidor 2 gerencia slots 4096-8191 (partição 2 de 4);
- Servidor 3 gerencia slots 8192-12285 (partição 3 de 4);
- Servidor 4 gerencia slots 12286-16381 (partição 4 de 4);
O cluster precisa saber a quantidade de membros e a posição de cada um para fazer o particionamento. Ilustrando:
2.3 – Balanceamento de carga
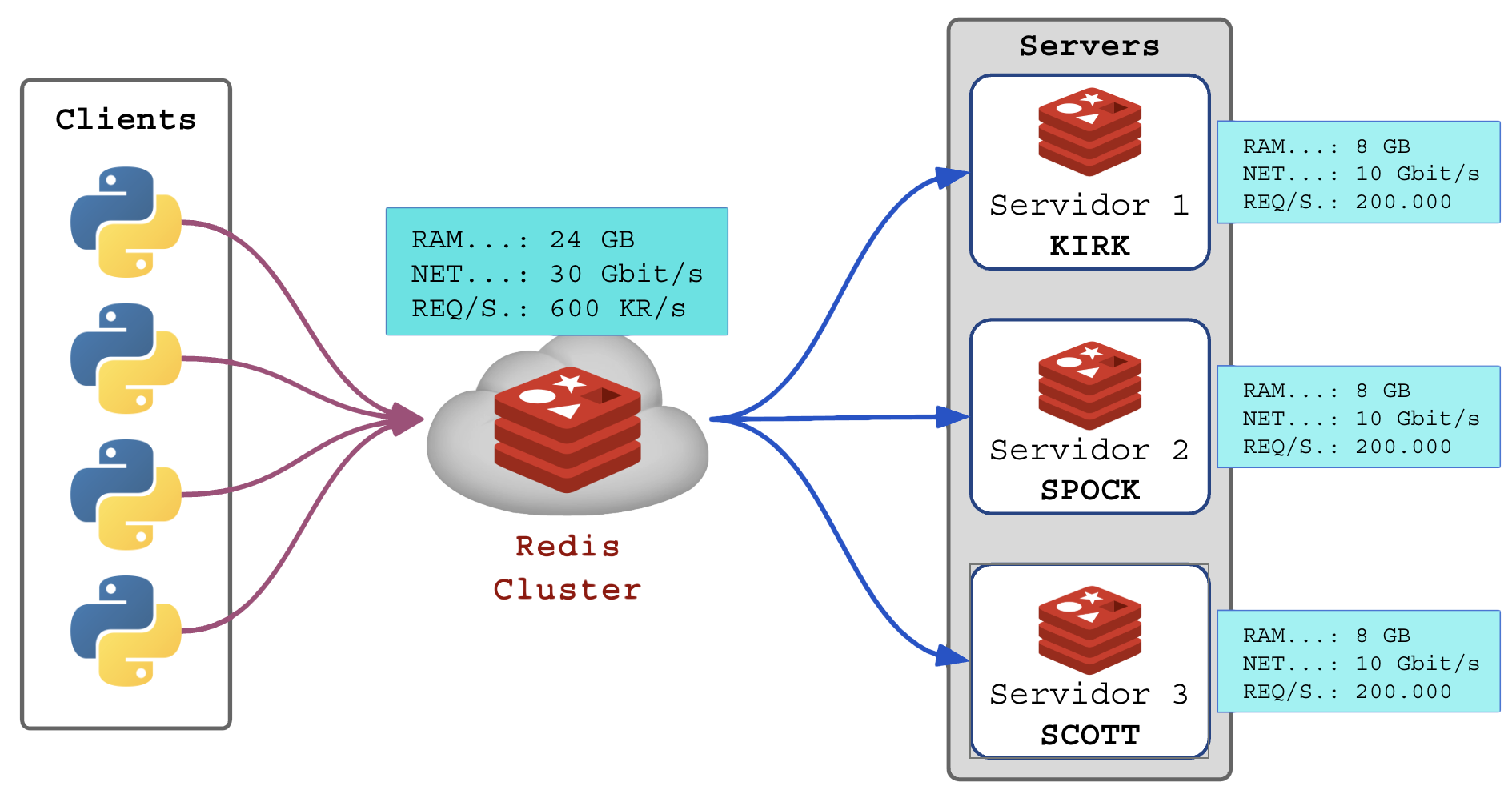
Com a combinação de vários servidores REDIS recebendo ordens balanceadas em SHARD-SLOTS particulares, o cluster provê o balanceamento da carga e a soma de recursos.
Em um ambiente com 3 servidores conseguimos:
- Se cada servidor possuir 8 GB de RAM, 3 servidores fornecem 24 GB de capacidade de armazenamento em RAM das chaves;
- Se cada servidor suportar 10 Gbit/s de banda, teremos 30 Gbit/s de banda larga;
- Se cada servidor suporta 200 mil operações, teremos 600 mil de operações;
Cluster agregado:
2.4 – Replicação e Redundância
A replicação é a parte que provê a redundância dos dados caso um dos nós da rede venha a desaparecer por algum motivo (queda da VM, queda da rede, bug ou travamento, reboot, falta de RAM/OOM, …).
Em um cluster com 3 nós com 8 GB de RAM cada provê o total de 24 GB de pool para o trabalho, mas ao replicar os 8 GB de um nó em outro as coisas podem “sair do controle” e você terá 16 GB de alocação. Conceitos:
- MASTER: é instância do REDIS responsável pela partição de slots que lhe coube no setup do cluster;
- REPLICA: é instância do REDIS responsável por importar a partição de um master para guardar como backup a quente caso ele caia. Detalhes:
- A réplica é assíncrona: o MASTER obedece o cliente e só depois comunica o update para a réplica;
- LAG: a latência entre o master e a réplica cria diferença entre os dados;
- Se a latência for de 10 mili segundos, o update demorará esses 10ms para se tornar disponível na réplica;
Assim, se seu master tem 8 GB de RAM disponíveis e ja fez uso de 5 GB, sua réplica consumirá 5 GB, consumindo um total de 10 GB em sua infra.
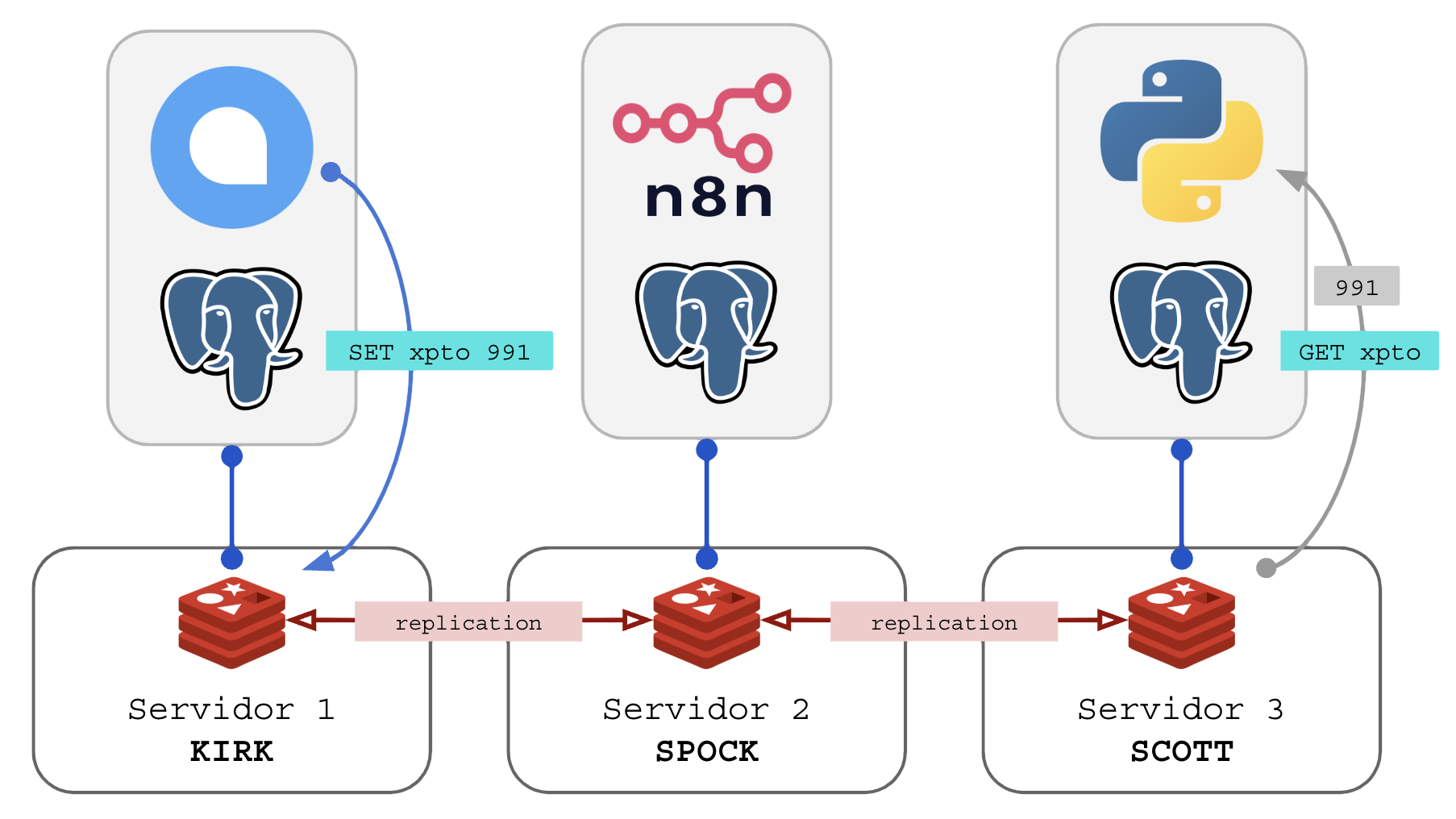
Cada instância master precisa de uma instância replica remota para lhe servir de backup em tempo real. Em nosso exemplo com 3 servidores, cada servidor executará 2 instâncias do Redis. Diagrama:
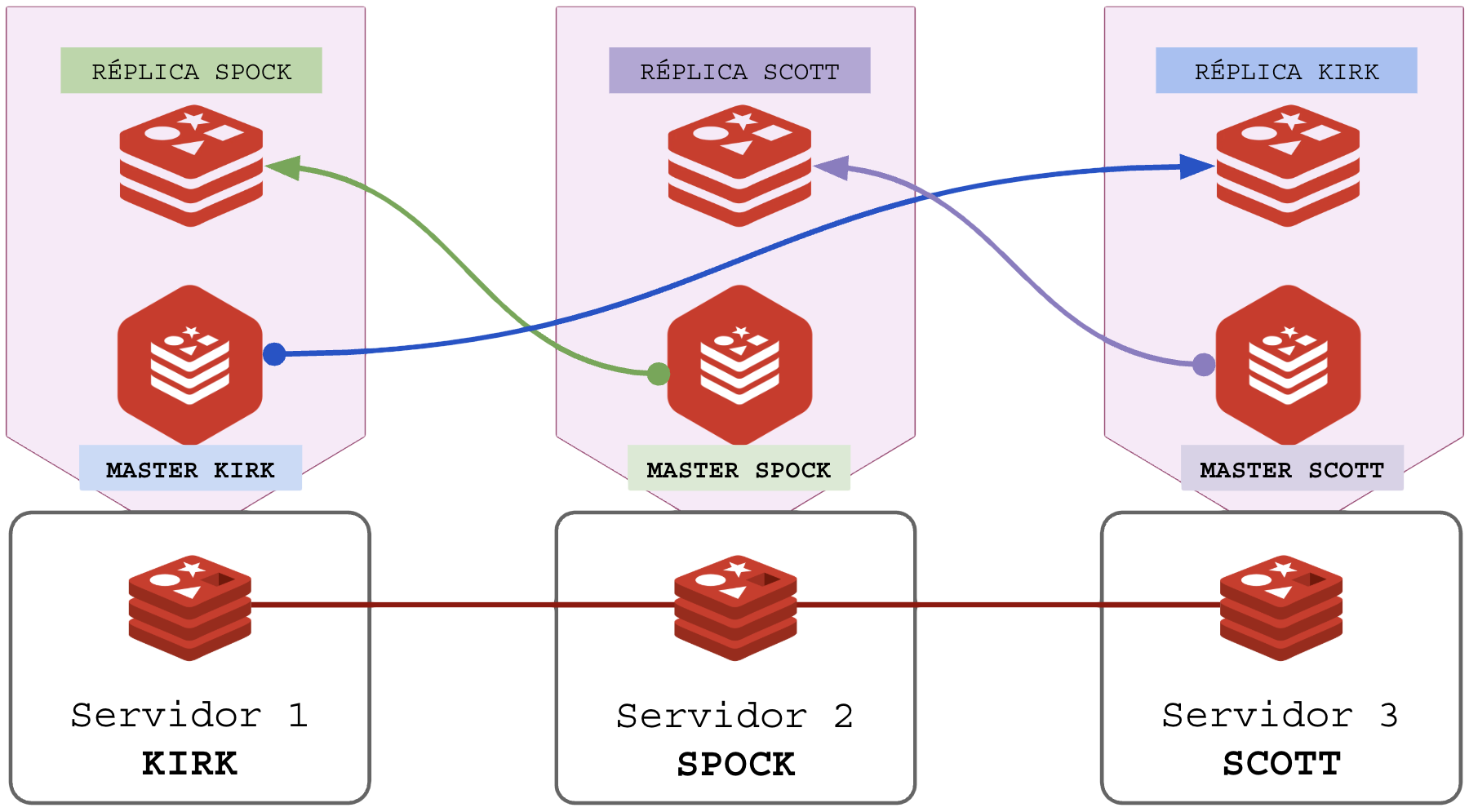
Quando o cliente criar alguma chave o processo de replicação é automático do MASTER para sua respectiva RÉPLICA:
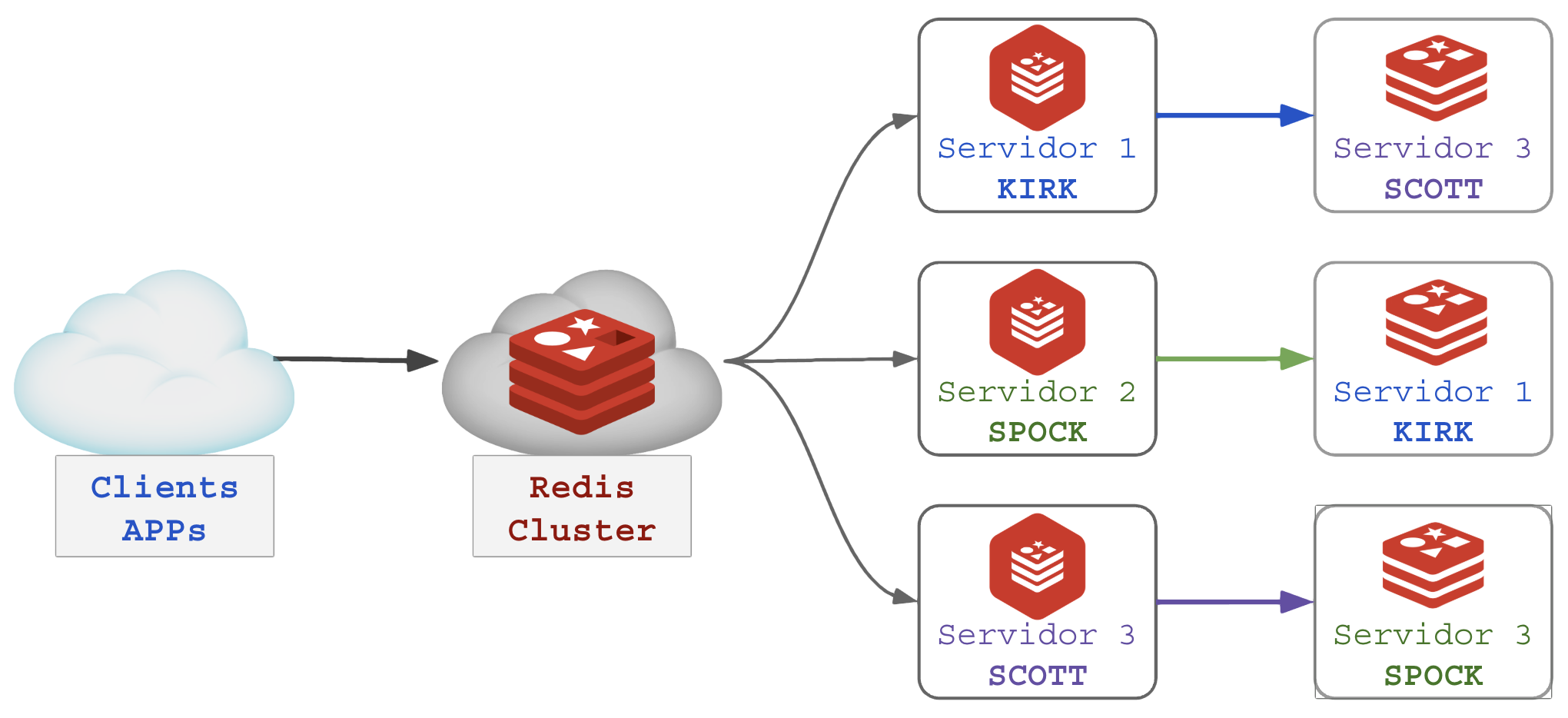
Em caso de falha de um dos serviços MASTER, sua RÉPLICA assume o atendimento dos clientes. Se o servidor SPOCK do exemplo acima for desligado, o cluster continua funcionando com integridade de dados como demonstrado abaixo:
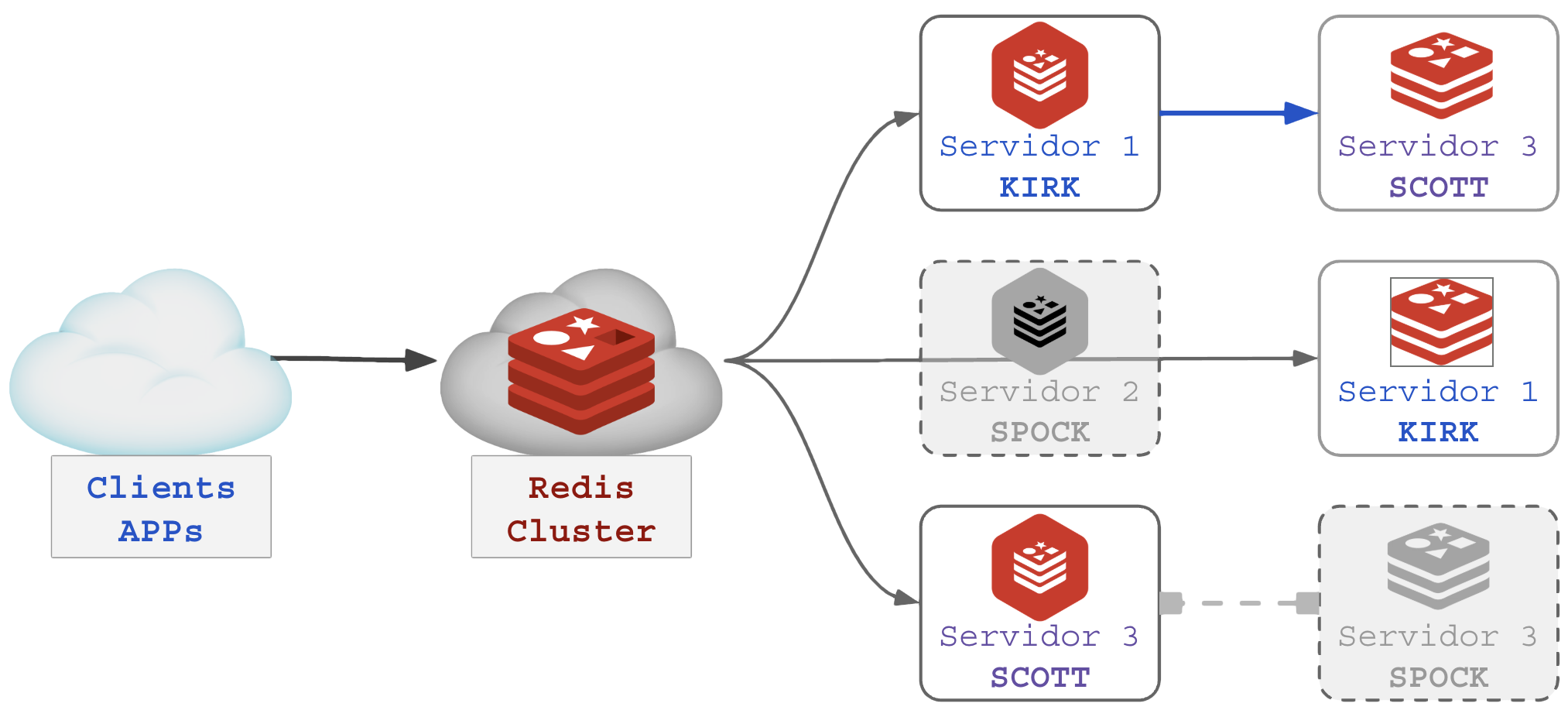
Note que ao desligar o servidor SPOCK, o a instância RÉPLICA de SPOCK estava no servidor KIRK, que passou a dobrar o consumo de CPU/RAM/IO pois atenderá 66% da carga do cluster até que SPOCK seja religado ou o cluster redistribua os Sharding Slots. O servidor SCOTT segue em produção mas sem sua réplica que estava em SPOCK.
A designação é definida pelas configurações de Eleição e promoção:
- Eleição: todos os nós elegem os MASTERs e suas prioridades;
- Promoção: cada nó inativo no processo de eleição é promovido a MASTER ou RÉPLICA.
2.5 – Operações de READ/WRITE e READONLY
Um servidor RÉPLICA cuida de manter a cópia dos dados de seu MASTER, nesse modo ele não pode ser usado para operações de escrita (criar chaves, alterar chaves, remover chaves, empilhar e desempilhar listas). É possível consultar uma réplica com o comando READONLY, mas ele não participa da produção até que se torne um master.
2.6 – Cluster sem réplica
É preciso deixar claro que a presença da réplica é opcional.
Se o objetivo for apenas performance máxima sem redundância você pode fazer um simples cluster não-replicado.
Esse caso é muito usado em ambientes que contornam a natureza single-thread do Redis.
Ao criar um servidor dedicado para o Redis com 16 núcleos, montar um cluster com 16 instâncias nesse mesmo nó entregará em torno de 8x mais performance que uma instância simples:
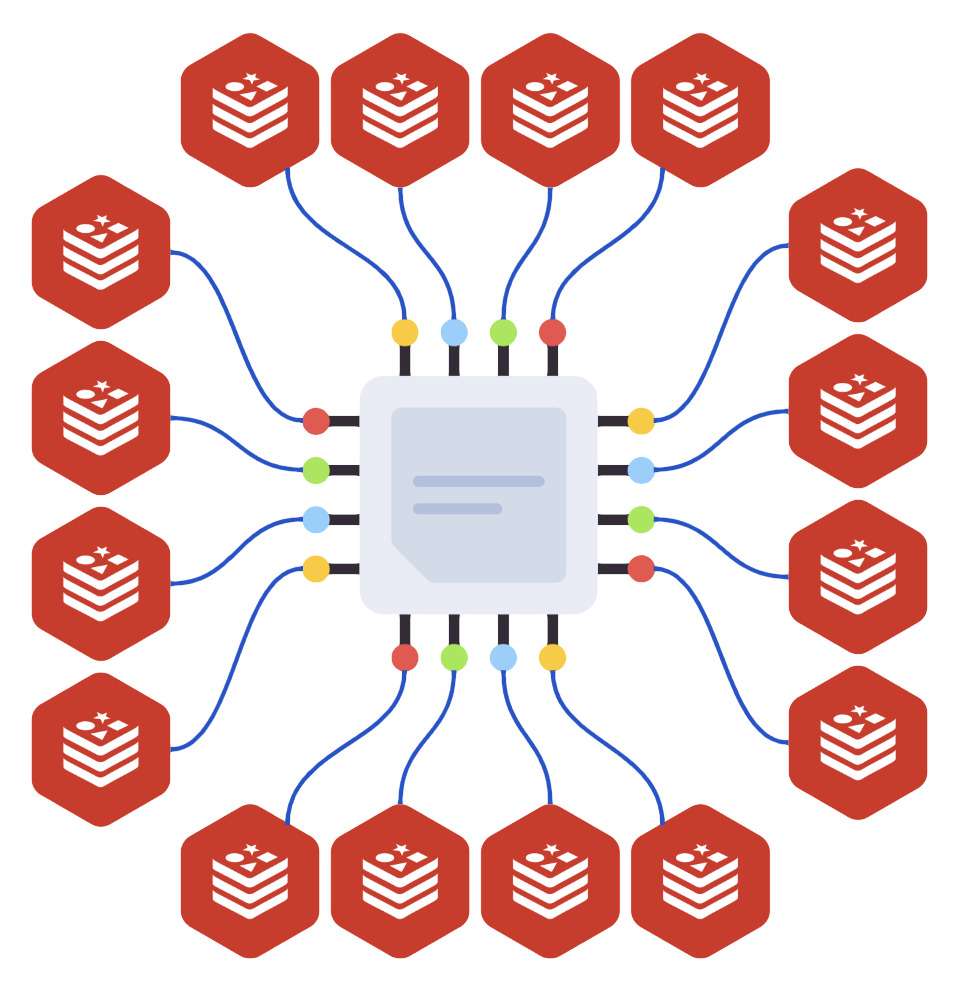
Será necessário fazer uma afinidade de CPU em cada instância para aprisioná-la no núcleo designado (capítulo de Tuning).
2.7 – Tipos de clientes do cluster
A dúvida mais comum é: “Em qual IP o cliente se conecta para usar o cluster?“
Existem dois tipos de clientes:
- Naive/Non-cluster-aware: simples, software que deseja usar o REDIS como se ele fosse um nó solitário (softwares em stack fazem isso);
- Cluster-aware: integrado, software cliente está preparado para se conectar ao cluster e possui os endereços dos nós;
- Smart Clients: dinâmico, conecta-se a um servidor e aprende por meio dos avisos de redirecionamento quais são os servidores do cluster e seus particionamentos.
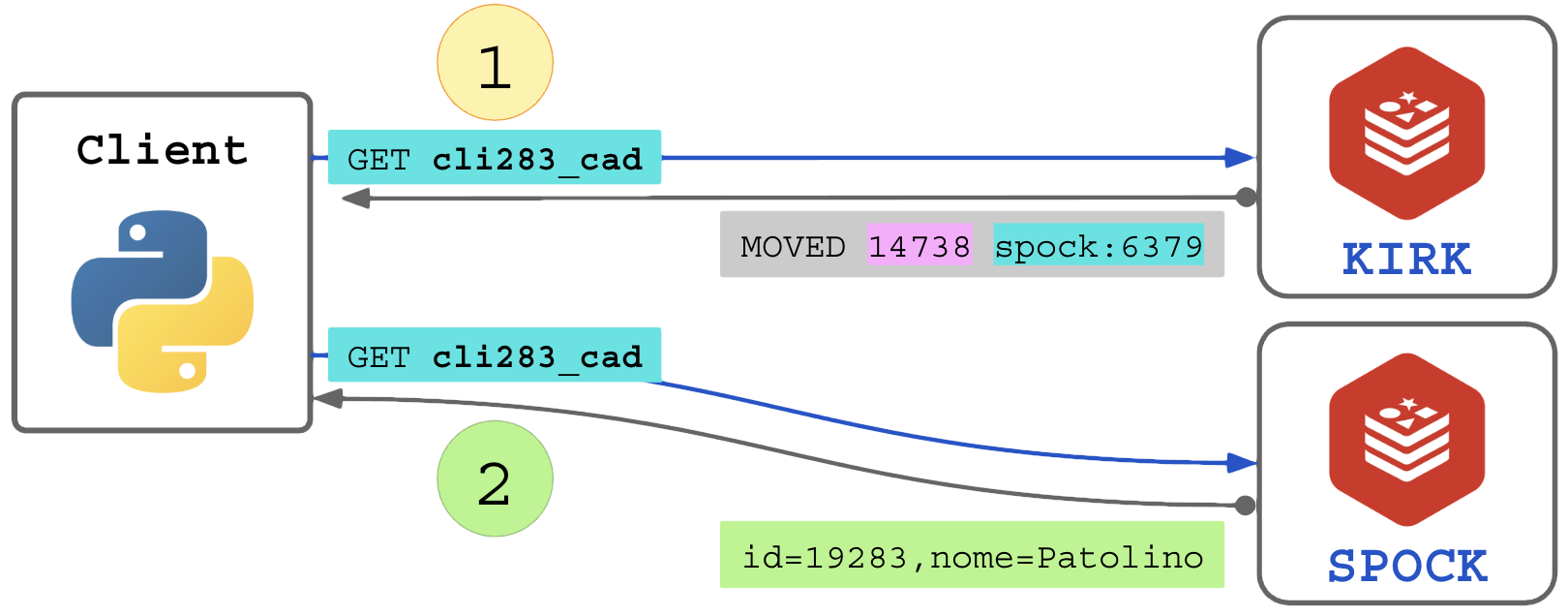
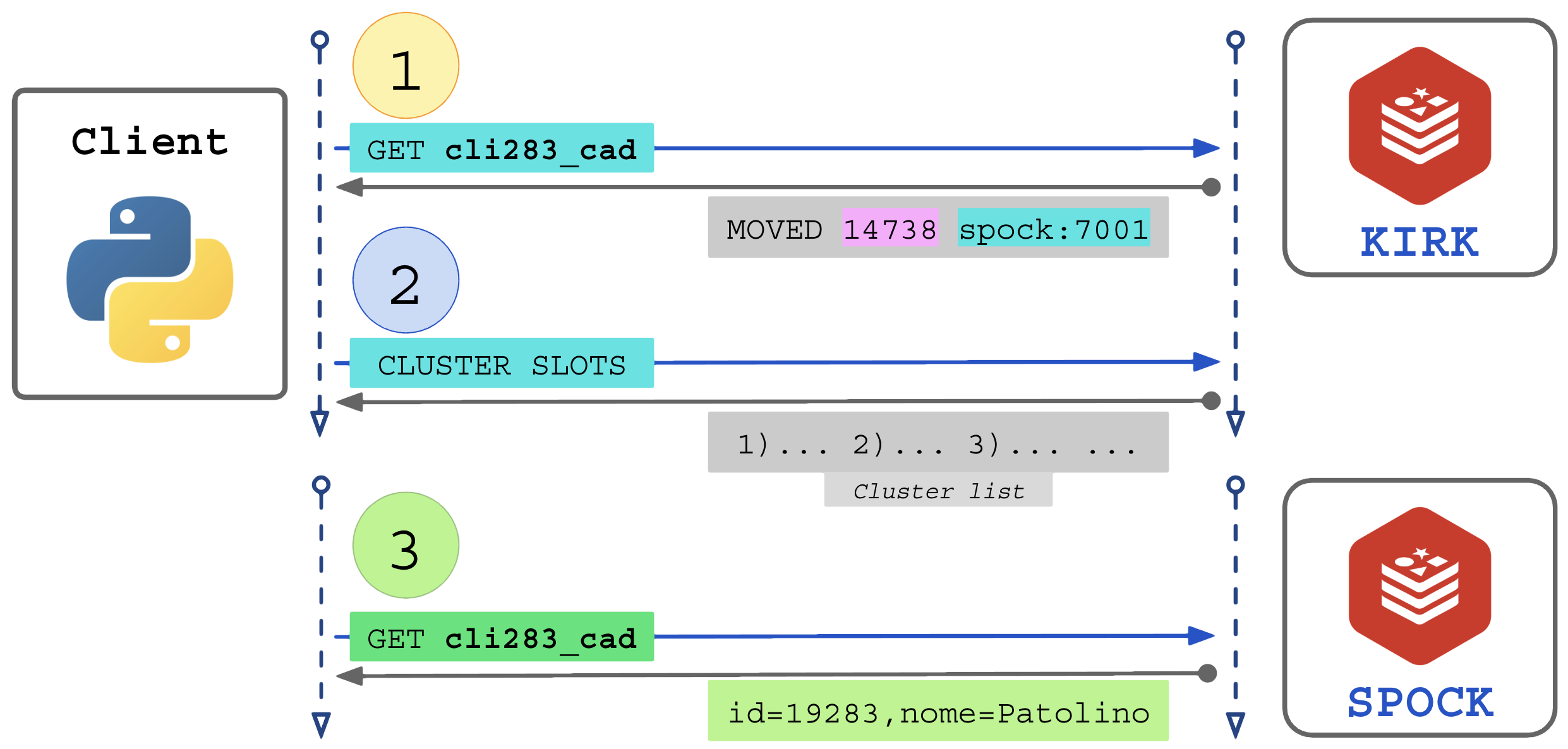
Todo nó no cluster sabe em qual partição dos slots ele opera. Se uma requisição é enviada solicitando uma chave cujo SLOT-ID não é de responsabilidade dele, ele responde “não sou eu, vá no servidor adequado no IP x.x.x.x porta pppp” (MOVED).
O cliente “Naive/Non-cluster-aware” que aponta fixamente para um dos IPs do cluster pode sofrer com dois problemas graves:
- Latência maior: toda requisição de escrita e leitura resultará em um redirecionamento para o servidor adequado, serão necessárias 2 conexões para cada operação;
- Indisponibilidade: se o nó para qual o cliente aponta desaparecer da rede ele ficará desconectado do cluster;
- Desconexão permanente: se apontar para um nó descontinuado e que nunca mais tornará ao cluster.
Fluxo de uso do cliente simples:
A solução definitiva é e o Smart Client. O cliente se conecta a qualquer IP do cluster e ao receber um MOVED ele se torna cluster-aware, solicitando a lista de clusters ao nó e se atualizando para enviar requisições aos nós corretos.
O Smart Client inicia apontando para apenas 1 IP/porta do cluster.
Fluxo do Smart Client integrado ao cluster:
- Se o cliente não sabe que está acessando um cluster, ele fará a busca da lista somente se receber um MOVED como resposta, se tornando Smart Client a partir desse ponto;
- Se o cliente foi previamente instruído da presença do cluster (cluster-aware) ele já solicita a lista imediatamente;
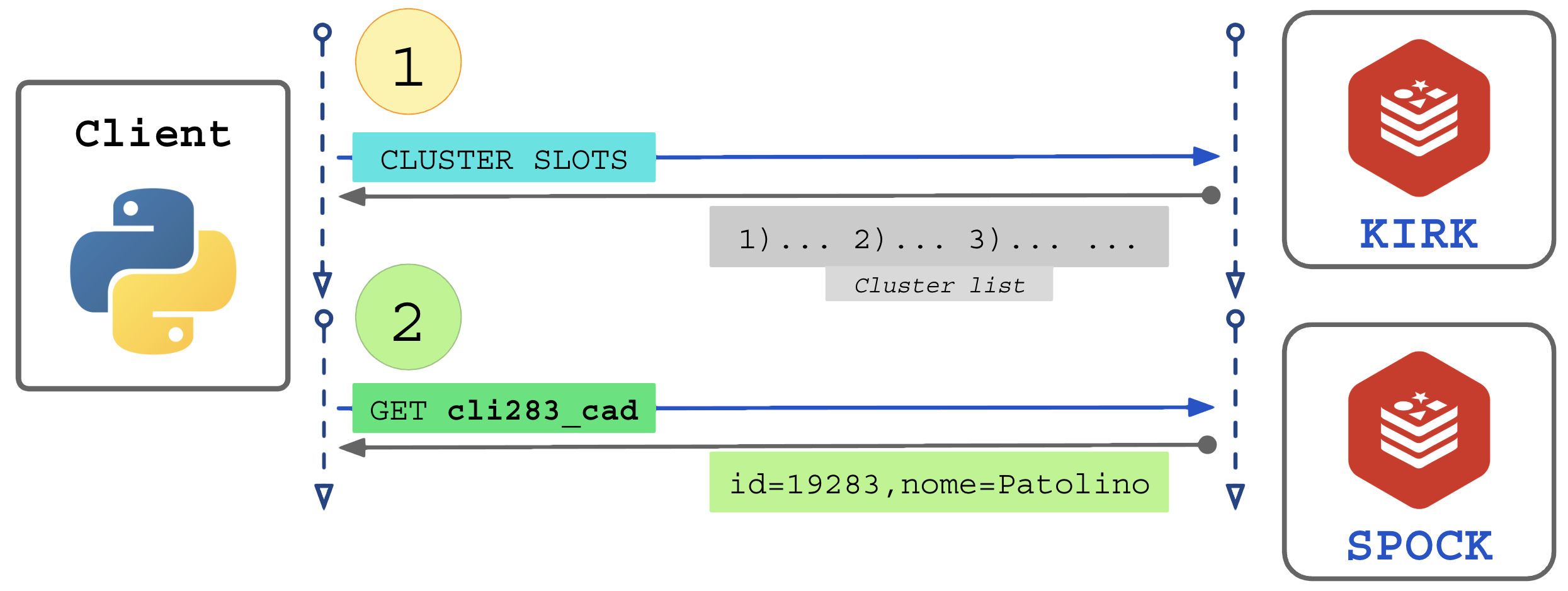
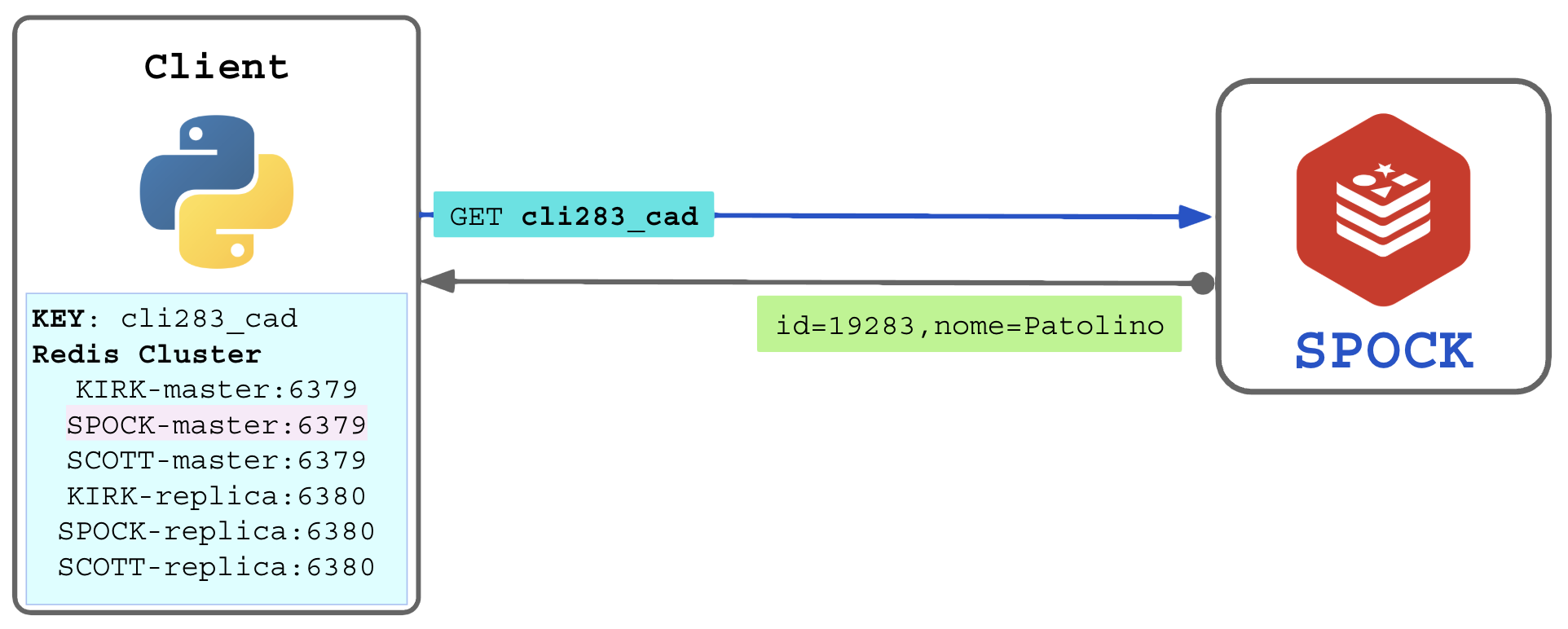
Com a lista de nós no cluster, o cliente passa a calcular o slot-id para descobrir localmente (antes de requisitar) para qual nó deve enviar. O cliente manterá a conexão ativa com todos os nós do cluster (pool de conexões do cliente):
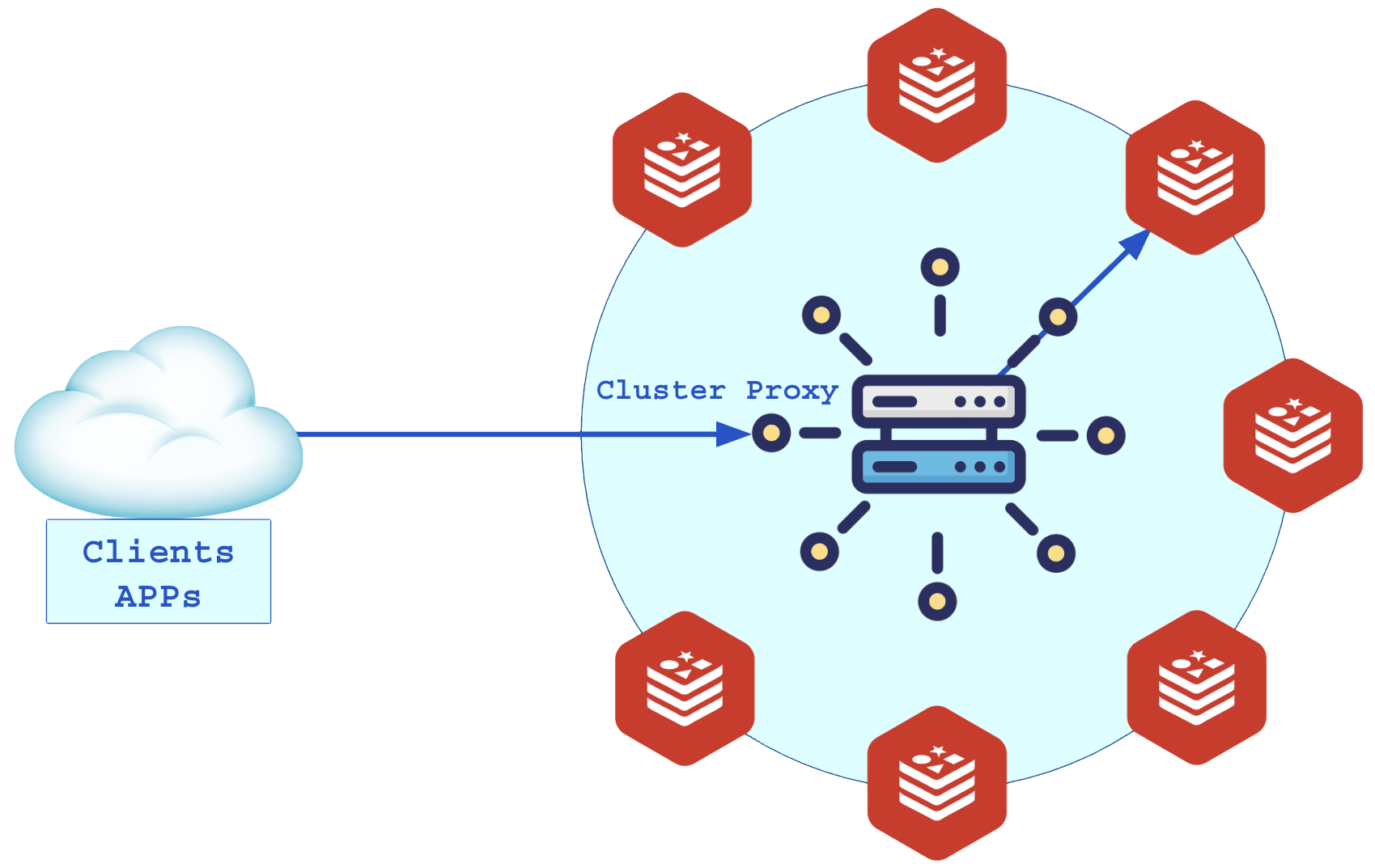
2.8 – Servidor Proxy (deprecated)
O Proxy foi uma solução utilizada antes dos softwares clientes (Redis Client) suportarem o modo Smart Client. O proxy era usado em ambiente de larga escala para simplificar o acesso a um único IP e porta, e o proxy abstraia o balanceamento calculando os slots e direcionando para o nó adequado. Ele também ajudava a fornecer um acesso público centralizado em um nome de DNS (redis.minhaempresa.com).
Ao receber a conexão do cliente o proxy repassa as requisições corretamente aos nós do cluster:
2.9 – Servidor Anycast
O conceito de Anycast (qualquer um recebe a transmissão, quem estiver mais perto de preferencia) difere do conhecido Unicast (a transmissão tem um destinatário específico).
Todos já estão familiarizados com o Unicast: cada servidor na rede possui sem próprio endereço IP, seja na rede local ou em toda a Internet (IPv4 público / IPv6 global).
O Anycast, menos famoso, consiste em todos os servidores terem o mesmo IP. O medo do tal “conflito de IP” é eliminado pois esse endereço fica em uma interface privada de cada servidor (normalmente a interface Loopback – lo, mesma interface do ip 127.0.0.1 / ::1).
Isso nos permite criar uma aplicação anycast.
Essa técnica consiste em aplicar o mesmo endereço IP na interface Loopback de todos os servidores de aplicações.
O cliente (aplicação cliente Redis) se conecta ao IP de Anycast, que naturalmente conduz os pacotes à interface lo do servidor onde a aplicação está sendo executada.
Procedimentos a serem realizados em todos os servidores de aplicações:
- Em é adicionado o IPv4 10.255.255.255 e IPv6 2001:db8::10:255:255:255 na interface loopback lo;
- O Proxy é instalado e executado para receber as conexões dos clientes;
- O software de proxy atende os clientes no endereço Anycast;
- As conexões recebidas são encaminhadas para os endereços Unicast dos servidores Redis do cluster.
Criando interface loopback no Debian:
# Loopback Anycast
(
echo 'auto lo:1';
echo 'iface lo:1 inet static';
echo ' address 10.202.255.255/32';
) > /etc/network/interfaces.d/loopback1;
# Loopback Unicast (ip proprio individual)
(
echo 'auto lo:2';
echo 'iface lo:2 inet6 static';
echo ' post-up ip -4 addr add 10.202.255.101/32 dev lo:2 || true';
) > /etc/network/interfaces.d/loopback2;
# Ativar interfaces no sistema:
ifup lo:1;
ifup lo:2;
As aplicações podem então ser guiadas a se conectarem no IP Anycast. Ao mover o subir a aplicação em qualquer servidor ela se conectará instantaneamente ao Cluster Redis com latência de microsegundos (<1us, 1ms=1000us, 1s=1000ms).
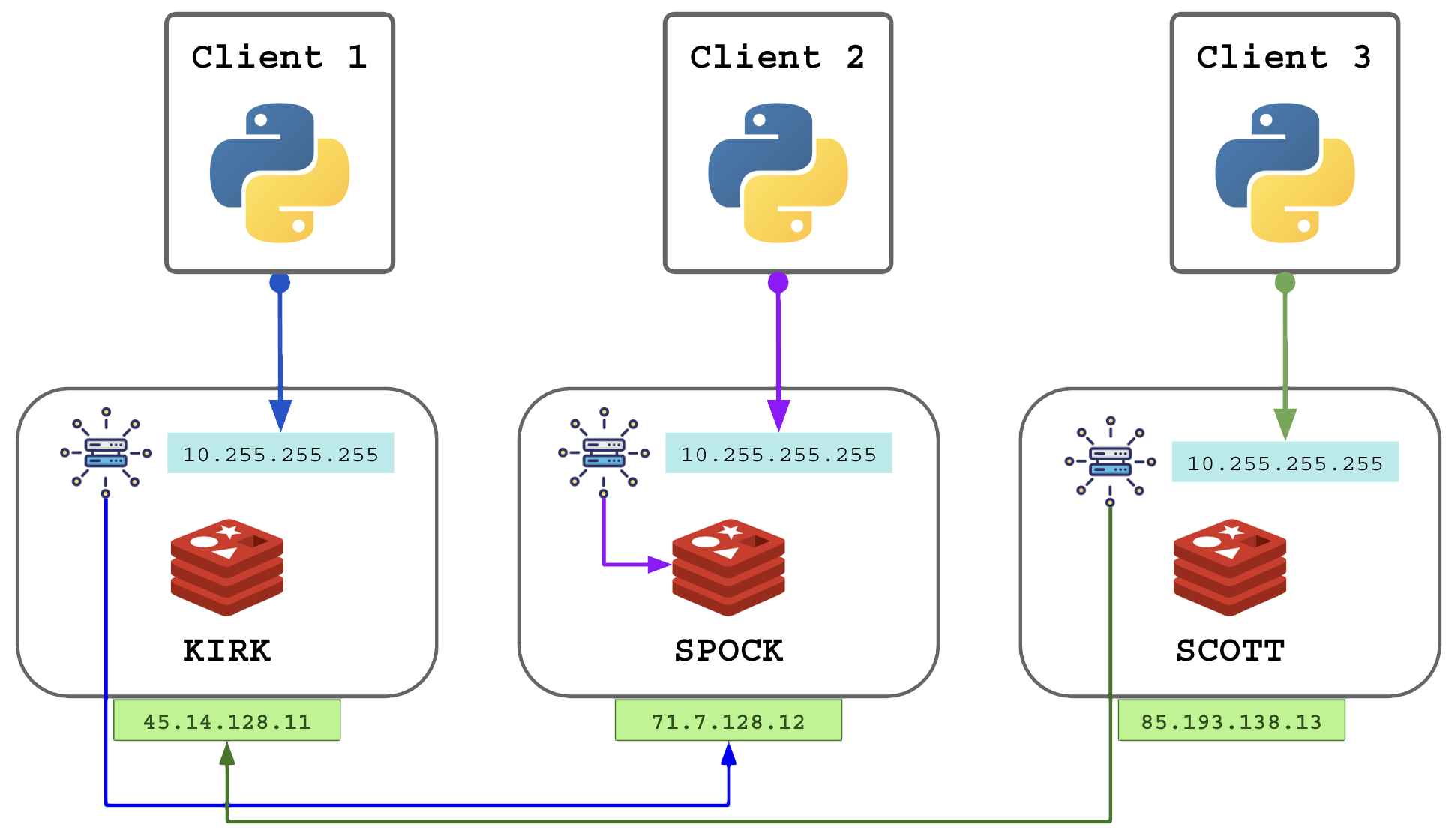
O uso adequado em rede local privada na região dos servidores:
Configurações necessárias nos nós:
- bind 10.255.255.X 10.255.255.255: escutar requisições no IP Unycast e Anycast, opcionalmente no endereço de LAN (10.200.0.X);
- cluster-announce-ip 10.255.255.X: anunciar aos clientes apenas o IP Unicast;
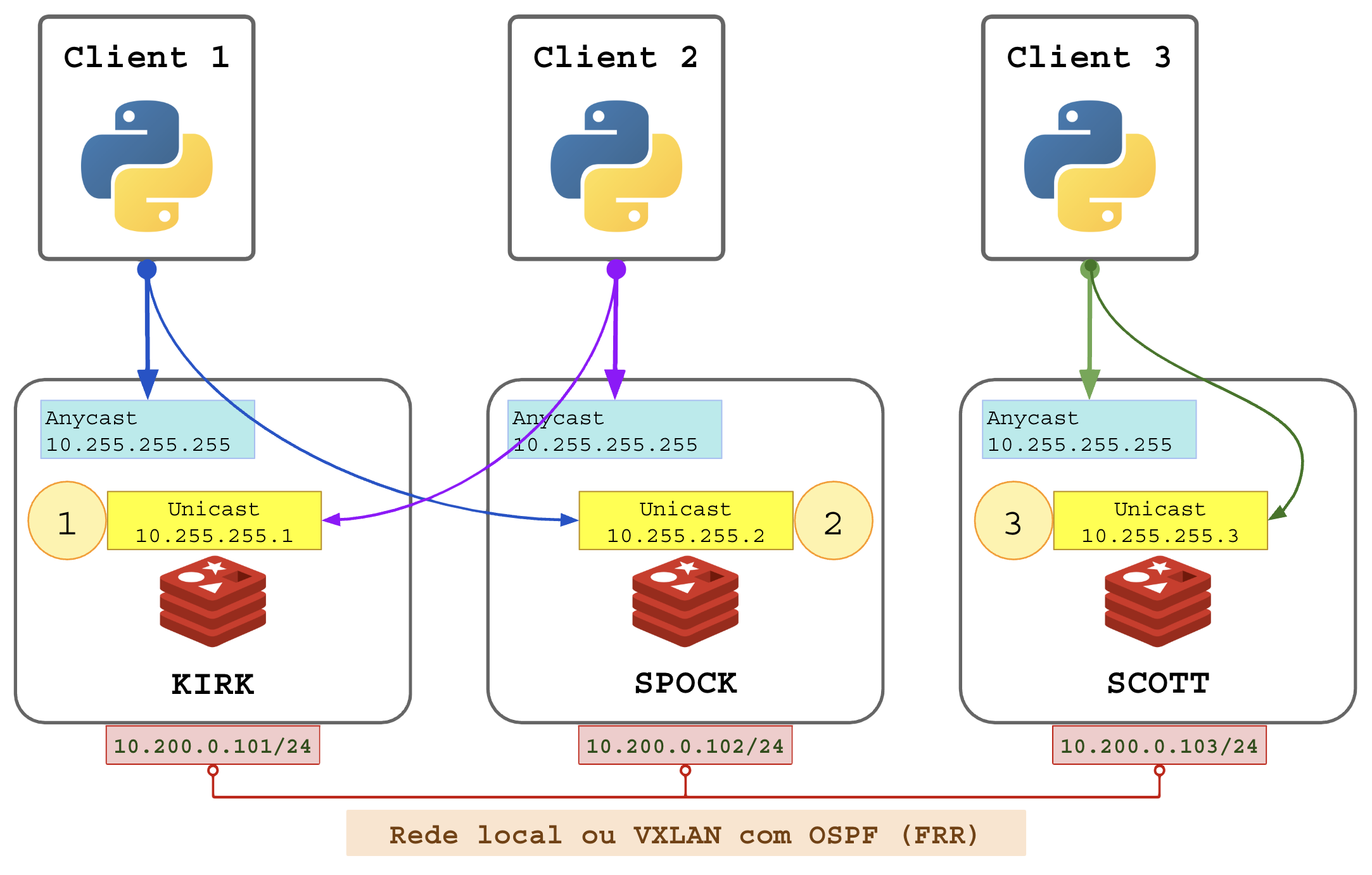
2.10 – Servidor Anycast móvel
Um nível mais eficiente e um pouco mais complexo dessa implementação consiste em mover o nó junto com seu IP Anycast e Unycast para diferentes servidores:
- Ao carregar o nó, adiciona o IP Unicast e Anycast;
- Ao ser desligado ou movido retira os IPs do servidor abandonado.
Para que o IP seja alcançado pelos servidores de aplicações é necessário o uso de protocolos de roteamento (software FRR, protocolo OSPF, BGP ou BABEL).
Se os servidores não estiverem na mesma rede local será necessário configurar túneis de VPNs entre eles (VXLAN, GRE, Wireguard, etc). Procedimentos:
- Instalar o FRR (free range routing);
- Configurar um protocolo de roteamento: OSPF, BABEL ou BGP, recomendo OSPF (OSPv2 para endereços IPv4, OSPFv3 para endereços IPv6);
- Configurar o serviço de adjacência em tempo real usando BFD (parte do FRR);
- Configurar o protocolo (OSPF) para redistribuir apenas os IPs desejados, no caso, o IP de loopback Anycast;
- Garantir a adjacência (reconhecimento entre servidores);
Tutorial de FRR e exemplos de configuração:
2.11 – Problema de Split Brain
O “Split Brain” é um problema que pode ocorrer quando um cluster é dividido por uma falha de rede e cada parte se assume como independente (brain=cérebro), quebrando um cluster (split=dividir) em dois clusters independentes que agora não compartilham novas atualizações entre si, cada parte acredita ser a parte que sobreviveu.
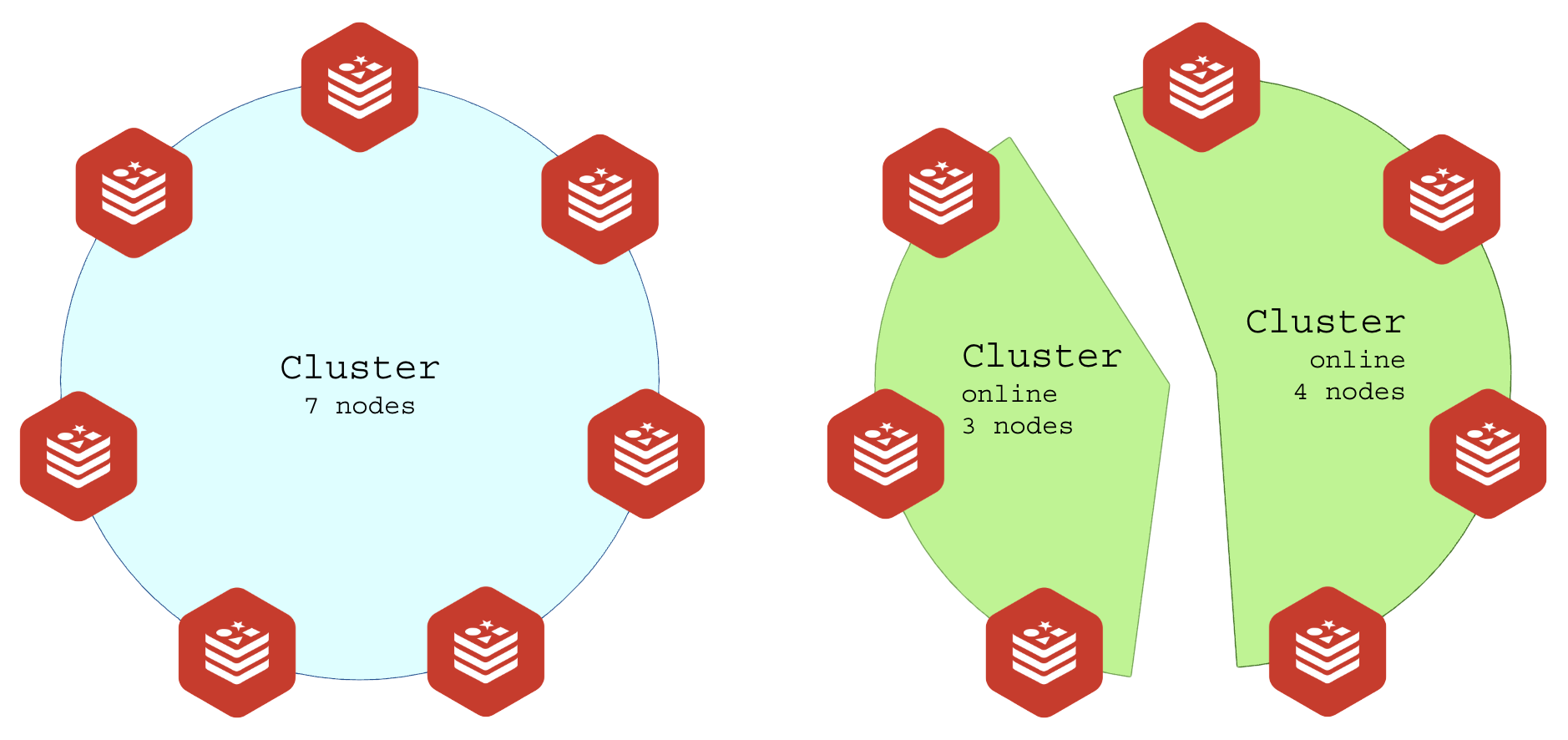
Soluções para o split-brain
- Redundância de rede: Garantir algum caminho de backup, por pior que seja (VPN, SDWAN), para manter a comunicação entre as partes;
- Quorum: definir o números de nós que formam o cluster e colocar um número impar de nós na região resiliente e um número menor de nós na região sensível;
- Cluster com 7 nós;
- Região A: 4 nós;
- Região B: 3 nós;
- Quorum mínimo de 4 (metade + resto da divisão ou simples 50% + 1);
- Quando romper entre as regiões, a região com 3 nós não formam quorum e ficam 100% offline, a região A continua funcionando;
Quorum para isolar parte funcional (online) da parte morta (offline):
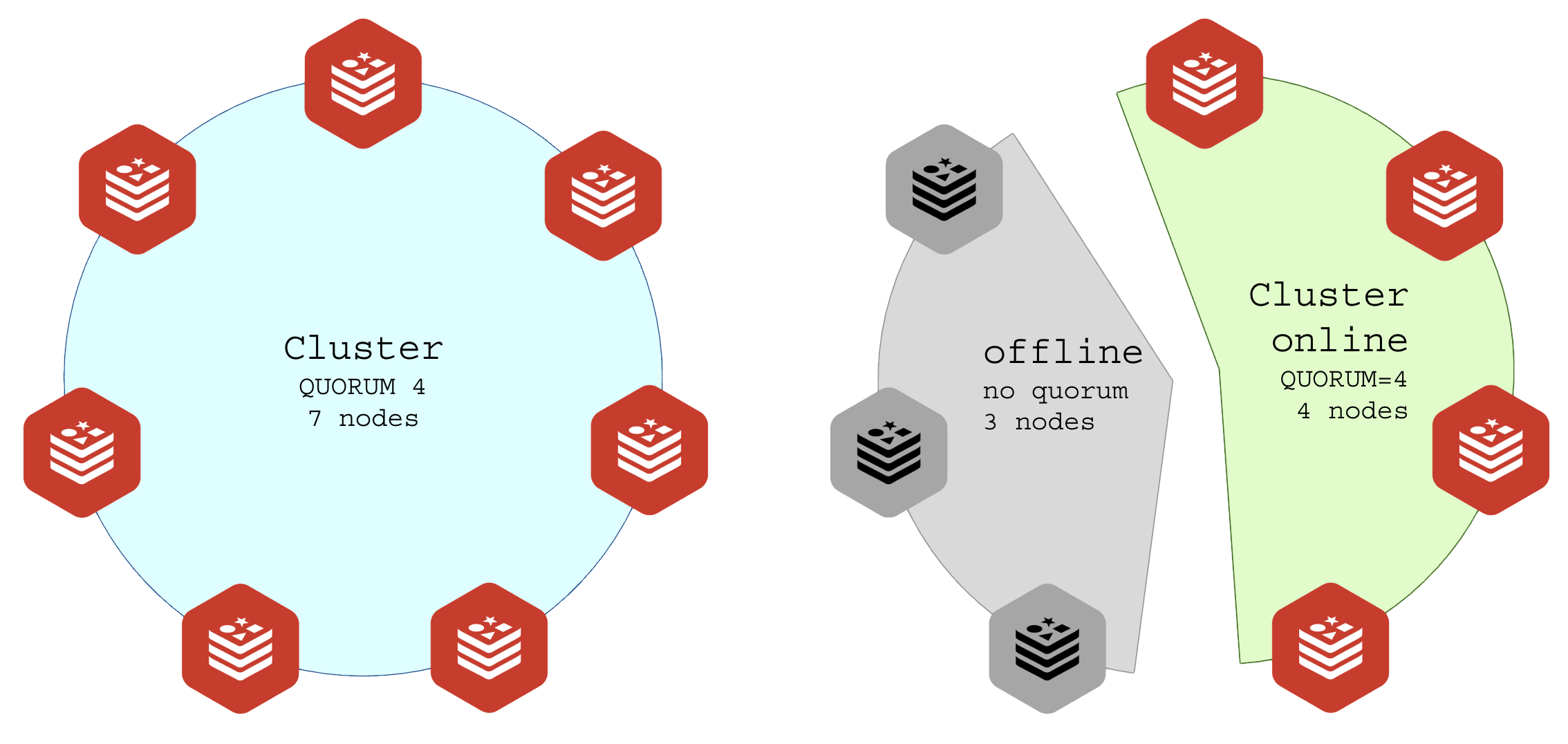
Split Brain nem sempre é um problema. Algumas aplicações podem funcionar muito bem mesmo com o cluster divido. Um software que distribuia trabalhos para workers por meio do Redis podem não se importar com a integridade do cluster desde que o trabalho seja feito e entregue, exemplos:
- Conversor: pegar um arquivo em uma API, processar, devolver pronto em outra API.
- Cache de servidores DNS em Redis;
Proposital ou não considere o split brain como o ponto crítico do projeto.
2.12 – Protocolo GOSSIP
Os nós do cluster se comunicam usando Gossip Protocol.
O Gossip pode atuar em diferentes modos:
- Completo: Cada nó precisa se comunicar com todos os outros (ad-hoc, full-mesh), todos os nós detectam o vizinho que parar de responder;
- Amostragem: Cada nó se comunica aleatoriamente com uma parte do cluster (10%). Isso garante que pelo menos um nó descobrirá um nó vizinho com problemas e comunicará a todos os outros (descoberta por amostragem, update por broadcast).
O Cluster Redis usa o método amostragem.
A porta do Gossip é +10000 portas acima do Redis (Redis na porta 6379, Gossip na porta 16379). A porta pode ser definida manualmente no parâmetro cluster-port.
Cada nó troca informações com outros nós periodicamente:
- Estado dos nós:
- ONLINE;
- PFAIL (possibly fail);
- FAIL;
- Mapeamento de slots;
- Informações de réplicas;
Mensagens trocadas:
- PING/PONG: Heartbeat para verificar se nós estão vivos
- MEET: Adicionar novo nó ao cluster;
- FAIL: Declarar que um nó falhou;
Detalhes do ambiente do protocolo Gossip:
- Um nó se conecta com todos os demais:
- Formula: C = ( (N – 1) * N) /2, C=conexões, N=número de nós.
- Divide-se por 2 visto que A conectar em B e B conectar em A é redundante, basta uma conexão acontecer para que a segunda não seja necessária. Ou A=>B, ou B=>A;
- Com 10 nós, cada nó mantém conexão com outros 9, assim: 10 x 9 = 90/2 = 45;
- Com 100 nós, cada nó mantém conexão com outros 99, assim: (100 x 99)/2 = 9.900/2 = 4.500;
- Com 1.000: (1.000 x 999)/2 = 999.000/2 = 499.500 conexões (ESTRESSANTE);
- Com 16.384 nós: (16.384 x 16.383)/2 = 268.419.072 = 134.209.536 conexões (INVIÁVEL).
- Mensagem entre nós: o nó mantém bitmap de slots (3 KB) onde os bits representam quais slots cada nó possui;
- Cada nó não envia mensagem para TODOS os outros constantemente;
- A cada segundo, cada nó:
- Envia PING para 10 nós aleatórios (padrão);
- Responde PONG quando recebe PING;
- Pode enviar mensagens extras (FAIL, UPDATE, etc.);
- Bitmap enviado em cada mensagem PING/PONG;
- Para 100 nós, 200 KB serão trocadas por segundo (cada nó enviando 2KB);
- O consumo de banda será de 1.6 Mb (200 kbytes * 8 bits);
- Timers: cada membro possui os cronômetros de timeout e ping para monitorar o cluster.
- O tempo entre mensagens e a ausência de nodes determina sua remoção do cluster;
Para um cluster hipotético com 100 nós, teremos o seguinte consumo de rede:
- Frequência: 10 PINGs/s (configuração padrão);
- Tamanho: 3.088 bytes por PING;
- Cálculo: 10 x 3.088 = 30.880 bytes/s;
- Convertendo: 30.880 bytes/s x 8 bits = 247.040 bits/s = ~247 Kb/s;
- Cada nó recebe 10 PINGs/s de outros nós (estatisticamente, dos 99 outros nós);
- Receberá aproximadamente: 10 PINGs/seg
- Responderá: 10 PONGs/seg
- Tamanho PONG: ~3.088 bytes
- Convertendo: 10 x 3.088 = 30.880 bytes/seg = ~247 Kbps;
- Quando detecta falhas ou mudanças:
- ~5-10 mensagens/seg extras (estimativa);
- Tamanho: ~1.000 bytes cada
- Convertendo: 10 × 1.000 = 10.000 bytes/seg = ~80 Kbps;
- Consumo por nó de 574 Kbit/s:
- 247 Kbps (PING);
- 247 Kbps (PONG);
- 80 Kbps (FAIL/UPDATE);
- Consumo agregado por nó (envio e recebimento) de 1.1 Mbit/s
- UPLOAD: ~574 Kbps;
- DOWNLOAD: ~574 Kbps;
Nota: a rede é medida e monitorada em bits por segundo enquanto que dados são representados em bytes, 1 bytes = 8 bits.
2.13 – Limite máximo
O limite prático para colocar em produção é de até 300 nós.
O limite teórico documentado pelo Redis é de até 1.000 nós em um mesmo Cluster.
O limite máximo praticável é de 5.000 nós ( (5.000 × 4.999) / 2 = 12.497.500 conexões).
O Linux possui limites internos que dificultarão exceder valores realistas:
- File Descriptors: soft limit padrão 1.024, hard limit padrão: 4.096, máximo configurável: 1.048.576 (1 milhão);
- Conntrack: limite de conexões do kernel de 262.144 (262 mil);
- IRQ: interrupções de processamento causadas por mensagens no baramento PCI vindo da interface de rede para os núcleos gastariam mais que o próprio Redis até esgotar o tempo da CPU;
Embora existam formas de exceder esses limites (sysctl tuning, XDP/DPDK, TCP Offload, Mellanox dataplane offload), não é muito viável ir por esse caminho.
Sites de jogos e sistemas de mensagens fazem uso de sistemas como Redis e preferem resolver isso com mais hardware paralelo e clusters segmentados (namespace).
Quantidades de nós operacionais no Cluster Redis:
- Mínimo: 3;
- Ideal: 6;
- Máximo recomendado: 300;
- Teto prático: 5.000;
- Teto absoluto (numeros máximo de shad-slots): 16.384;
2.14 – Projetando a quantidade de nós no cluster
Nem muito, nem pouco. O ideal é saber quantas requisições por segundo você precisa fornecer aos aplicativos clientes do seu Cluster.
Faça os testes de performance (capítulo 4) para saber quantas requisições por segundo cada servidor é capaz de prover por núcleo e então estime quantos nós MASTER você vai precisar.
Exemplo: aplicação exige 10 milhões de requisições por segundo – 10 Mreq/s:
- Cada instância garante 20 mil req/s (mínimo 20 req/s, máximo 40 req/s) por núcleo;
- Considerando o valor seguro garantido serão necessários 500 instâncias:
- 10.000.000 / 20.000 = 500;
- Considerando o valor máximo medido serão necessários 250 instâncias:
- 10.000.000 / 40.000 = 250;
- Sem overcommit, você precisará contratar 250 núcleos de CPU;
- Com 2x overcommit você precisará de 128 núcleos;
- Com 4x overcommit você precisará de 64 núcleos;
Abusar do overcommit pode fazer seu sistema apresentar lentidão em horário de pico. Monitore a latência do seu cluster (capítulo X) para aumentar a capacidade de hardware antes de entrar em crise!
Para implementar as réplicas você precisará:
- Dobro de memória RAM utilizada (se está usando 5G, você precisará de pelo menos 10G no total);
- Mais CPU: se você opera com 20% de operações de escrita, então a réplica será onerada somente durante esses updates, logo, 20% a mais de CPUs.
2.15 – Clusters paralelos
Criar um cluster para tudo na sua empresa pode não ser produtivo. Se você precisa de um cluster para 8 mil sistemas integrados para e-commerce, crie outro cluster para seu sistema de logs e monitoramento.
3 – Laboratórios para testes
Vou apresentar algumas topologias para implementação de um cluster para estudos e aprendizado.
3.1 – Ambiente single-host
O mínimo para montar um cluster são 6 instâncias: 3 masters + 3 réplicas = 6 nós;
Você pode, para aprender, rodar todas elas no mesmo servidor (Unit do SystemD ou Container em Docker) e matar instancias para ver como seu mini-cluster reage.
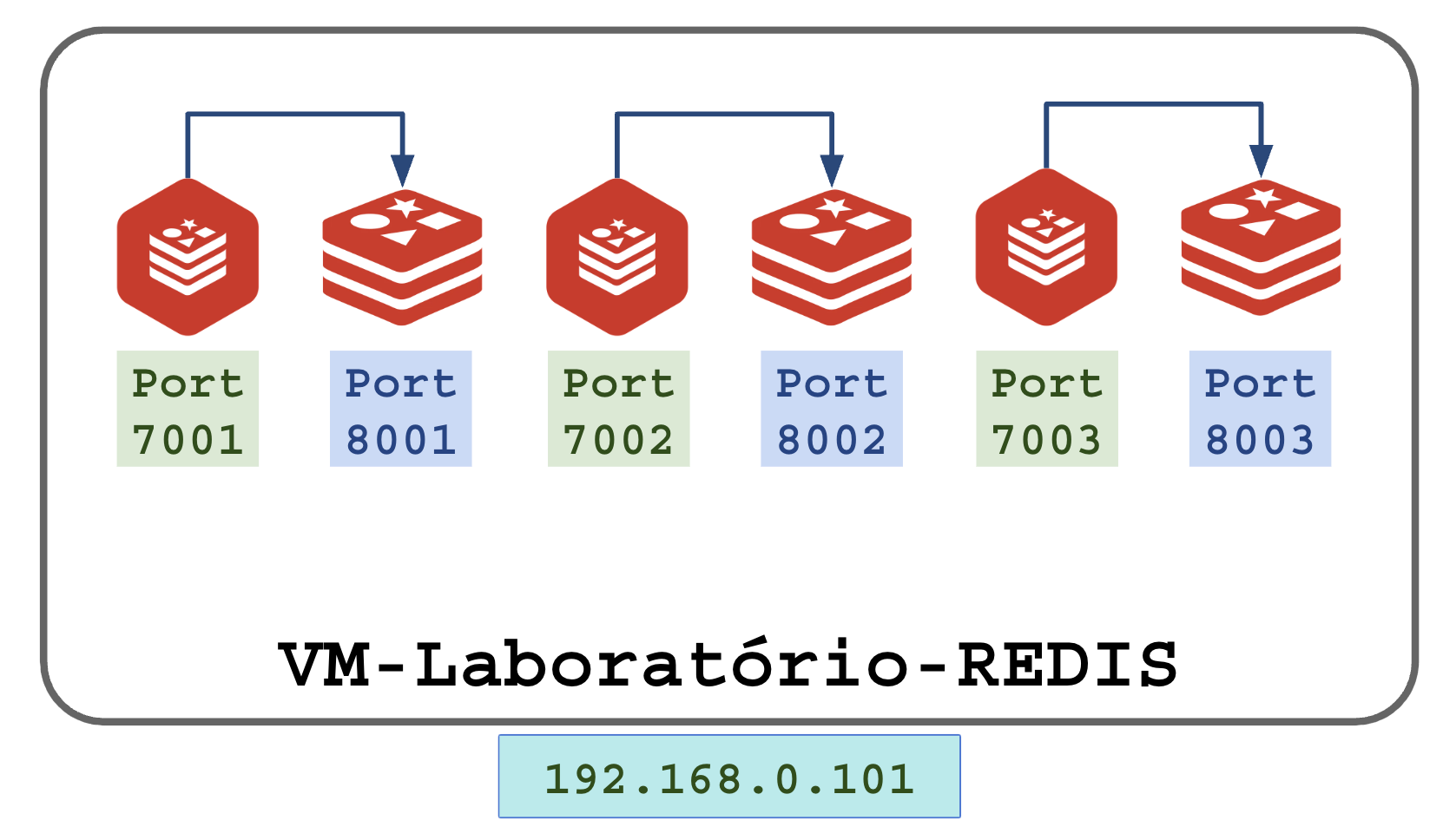
3.2 – Ambiente multi-host
Para produção o ideal é ir distribuindo as instâncias em diferentes servidores (VMs, VPSs, containers, …), sem hospedar nenhuma instância no mesmo servidor.
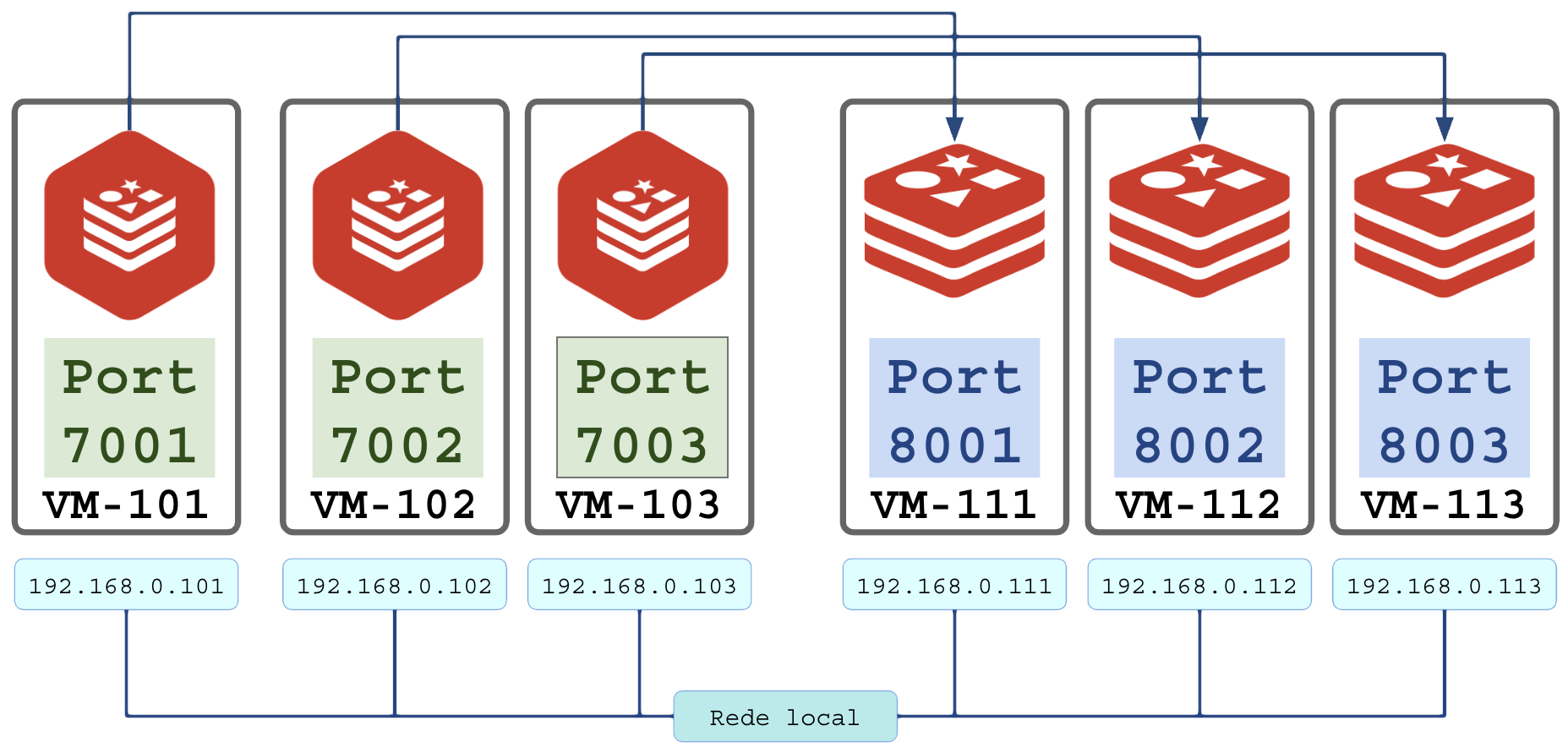
Se preferir rodar encima de Docker Swarm, seja muito claro sobre as restrições para impedir que um MASTER e sua REPLICA rodem no mesmo nó do Swarm.
3.3 – Ambiente cloud distribuido
ALERTA: Muito cuidado em ambientes de nuvem, os datacenters cobram pelo consumo de recursos e nesse caso a rede pode ser o maior problema (terabytes por mês).
Configuração PERIGOSA com 5 nós, 3 no Brasil, 2 nos EUA (risco de split brain, lag e latência):
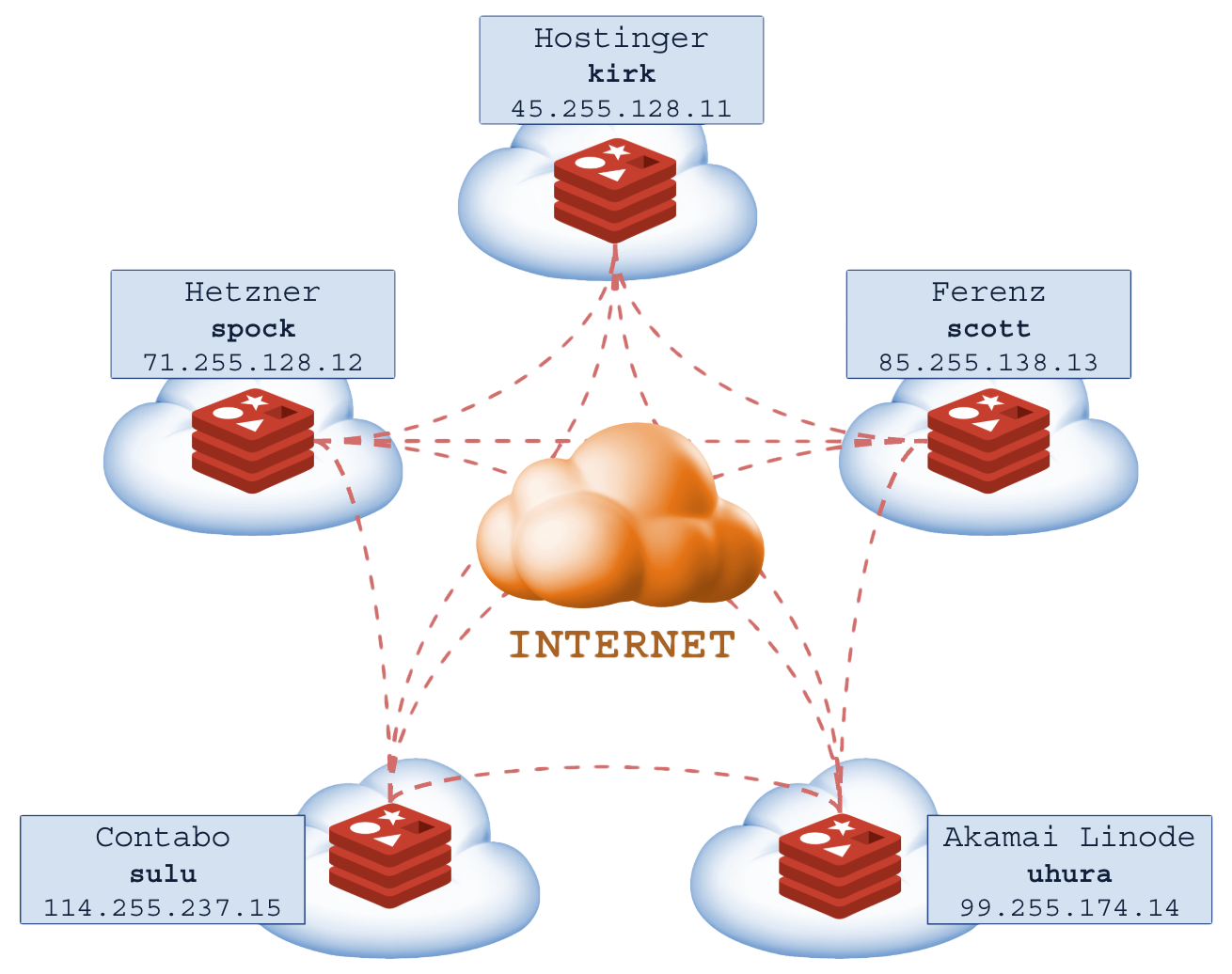
Você deve propositalmente subir 2 ou mais instâncias no mesmo servidor/VPS para elevar o número de nós em uma região para atingir o quorum caso deseje que o cluster funcione em uma parte sem permitir o Split Brain em outra, se isso for desejável.
3.4 – Ambiente cloud regional
A configuração em nuvem mais consistente é montando um cluster por região.
Teremos dois clusters mais fortes, resilientes e com baixa latência:

4 – Montando um Cluster Redis
Vamos preparar os arquivos e programas para usar em diferentes laboratórios. Cada passo é independente e poderá ser verificado para avançar devagar.
4.1 – Instalar Redis
Optei por rodar o Redis direto no HOST, se você desejar seguir pelo Docker, as imagens oficiais estão em https://hub.docker.com/_/redis (versão atual 8.0.2 no HOST, 8.2.3 no Docker Hub).
Instalando Redis no HOST (Debian)
# Instalar pacotes:
apt-get -y install redis;
apt-get -y install redis-server;
apt-get -y install redis-tools ;
# Ativar o REDIS durante o boot do Linux:
systemctl enable redis-server;
# Ativar o serviço:
systemctl start redis-server;
# Conferir status do serviço:
systemctl status redis-server;
# Backup da configuracao original:
RCONF=/etc/redis/redis.conf;
RBCKF=/etc/redis/orig-redis.conf;
[ -f $RBCKF ] || cp -ra $RCONF $RBCKF;
# Conferir versão:
# - Servidor:
redis-server -v;
# Redis server v=8.0.2 sha=00000000:0 malloc=jemalloc-5.3.0 bits=64
# build=3951f4e1c0288395
# - Cliente:
redis-cli -v;
# redis-cli 8.0.2
# Conferir configuracao original:
cat /etc/redis/redis.conf | egrep -v '(^#|^$)';
Caminhos dos programas e arquivos:
- Diretório de configurações: /etc/redis/
- Diretório de dados (RDB/AOF): /var/lib/redis/
- Unit SystemD: /lib/systemd/system/redis-server.service
- LogRotate: /etc/logrotate.d/redis-server
- Variáveis de ambiente: /etc/default/redis-server
- Logs: /var/log/redis/redis-server.log
Procedimentos de sanidade do ambiente (opcionais, ajudam a evitar erros):
# Garantir ambiente sanatizado
# Arquivos:
touch /var/lib/redis/dump.rdb;
# Diretorios:
mkdir -p /etc/redis;
mkdir -p /run/redis;
mkdir -p /var/lib/redis;
mkdir -p /var/log/redis;
mkdir -p /var/run/redis;
# Propriedade
chown -R redis:redis /etc/redis;
chown -R redis:redis /run/redis;
chown -R redis:redis /var/lib/redis;
chown -R redis:redis /var/log/redis;
chown -R redis:redis /var/run/redis;
chown redis:redis /var/lib/redis/dump.rdb;
# Permissoes
chmod 0660 /var/lib/redis/dump.rdb;
4.2 – Teste da instância padrão
Os testes na instância padrão ajudam a ter como referência as capacidades naturais do Redis em seu servidor antes de quaisquer ajustes.
Tome nota dos testes iniciais antes de montar o Cluster:
# Testes de capacidade (loopback test)
# 1 - Testes basicos do Redis
# 1.1 - Use 20 parallel clients, for a total of 100k requests:
redis-benchmark -h 127.0.0.1 -p 6379 -n 100000 -c 20;
# Summary:
# throughput summary: 44762.76 requests per second
# latency summary (msec):
# avg min p50 p95 p99 max
# 0.240 0.088 0.239 0.271 0.423 1.455
# 1.2 - Fill 127.0.0.1:6379 with about 1 million keys only using the SET test:
redis-benchmark -t set -n 1000000 -r 100000000;
# Summary:
# throughput summary: 46251.33 requests per second
# latency summary (msec):
# avg min p50 p95 p99 max
# 0.563 0.176 0.559 0.687 0.879 4.247
# 1.3 - Benchmark 127.0.0.1:6379 for a few commands producing CSV output:
redis-benchmark -t ping,set,get -n 100000 --csv;
# 1.4 - Benchmark a specific command line:
redis-benchmark -r 10000 -n 10000 eval 'return redis.call("ping")' 0;
# Summary:
# throughput summary: 46511.63 requests per second
# latency summary (msec):
# avg min p50 p95 p99 max
# 0.564 0.160 0.551 0.639 0.887 2.519
# 1.5 - Fill a list with 10000 random elements:
redis-benchmark -r 10000 -n 10000 lpush mylist __rand_int__;
# Summary:
# throughput summary: 43290.04 requests per second
# latency summary (msec):
# avg min p50 p95 p99 max
# 0.596 0.152 0.575 0.703 0.839 2.327
# 2.0 - Teste realista:
# - 20 mil requisicoes
# - fazer 1.000 requisoes em paralelo
# - criar chaves com valores de 1024 bytes
# - 8 threads de CPU em paralelo
# - pipilene de 8 requisicoes em serie
# - 6 digitos de precisao no resultado
redis-benchmark \
-h 127.0.0.1 -p 6379 \
-n 20000 -c 1000 \
-d 1024 \
--threads 8 \
-P 8 \
--precision 6;
# Summary:
# throughput summary: 78125.00 requests per second
# latency summary (msec):
# avg min p50 p95 p99 max
# 26.382 2.024 28.655 34.999 48.239 61.807
É comum que a capacidade fique entre 20 mil e 80 mil requisições por segundo, é um valor aceitável para a instância single-thread.
Com tudo testado e funcionando, não precisaremos da instância padrão para o cluster, você pode desativá-la se preferir. Recomendo desativar pois você pode por engano acessá-la e se confundir, usando a instância padrão em vez do cluster.
# Parar e desativar instância padrão do Redis no HOST
systemctl stop redis-server;
systemctl disable redis-server;
4.2 – Modelos de configurações
Vamos rodar várias instâncias do Redis no mesmo servidor, logo, cada uma será um servidor no SystemD. Ele nos ajudará a garantir o funcionamento do serviço, reiniciando-o automaticamente a isolando o processo (semelhante ao isolamento do Docker).
Cada serviço tem seu nome (redis-server-xyz) configuração (redis-xyz.conf).
O arquivo /etc/redis/template-service.conf contêm as palavras _RDPORT, _RDPASS, _RDPORT, _RDSRV que serão trocadas pelos valores do serviço a ser criado::
# Criar template de UNIT no SystemD
(
echo;
echo "[Unit]";
echo "Description=Redis Advanced key-value store (_RDPORT)";
echo "After=network.target";
echo "Documentation=http://redis.io/documentation, man:redis-server(1)";
echo;
echo "[Service]";
echo "Type=notify";
echo "User=redis";
echo "Group=redis";
echo "ExecStart=_RDSRV _RDCFG --supervised systemd --daemonize no";
echo "ExecStop=/usr/bin/redis-cli -p _RDPORT -a _RDPASS shutdown";
echo "PIDFile=/run/redis/redis-_RDPORT.pid";
echo "Restart=always";
echo "TimeoutStopSec=0";
echo "RuntimeDirectory=redis";
echo "RuntimeDirectoryMode=2755";
echo "UMask=007";
echo "PrivateTmp=true";
echo "LimitNOFILE=65535";
echo "PrivateDevices=true";
echo "ProtectHome=true";
echo "ProtectSystem=strict";
echo "ReadWritePaths=-/run/redis";
echo "ReadWritePaths=-/var/lib/redis";
echo "ReadWritePaths=-/var/log/redis";
echo "ReadWritePaths=-/var/run/redis";
echo "CapabilityBoundingSet=";
echo "LockPersonality=true";
echo "MemoryDenyWriteExecute=true";
echo "NoNewPrivileges=true";
echo "PrivateUsers=true";
echo "ProtectClock=true";
echo "ProtectControlGroups=true";
echo "ProtectHostname=true";
echo "ProtectKernelLogs=true";
echo "ProtectKernelModules=true";
echo "ProtectKernelTunables=true";
echo "ProtectProc=invisible";
echo "RemoveIPC=true";
echo "RestrictAddressFamilies=AF_INET AF_INET6 AF_UNIX";
echo "RestrictNamespaces=true";
echo "RestrictRealtime=true";
echo "RestrictSUIDSGID=true";
echo "SystemCallArchitectures=native";
echo "SystemCallFilter=@system-service";
echo "SystemCallFilter=~ @privileged @resources";
echo "ReadWriteDirectories=-/etc/redis";
echo "NoExecPaths=/";
echo "ExecPaths=/usr/bin/redis-server /usr/lib /lib";
echo;
echo "[Install]";
echo "WantedBy=multi-user.target";
echo "Alias=redis-server-_RDPORT.service";
echo;
) > /etc/redis/template-service.conf;
O arquivo /etc/redis/template-redis.conf contêm as palavras _RDPORT, _RDPASS, _RDADDR, _RDMEM que também serão trocadas pelos valores do serviço:
# Criar template de Redis
(
echo;
echo "# Geral";
echo "port _RDPORT";
echo "bind _RDADDR";
echo "protected-mode no";
echo "daemonize yes";
echo "pidfile /var/run/redis/redis-_RDPORT.pid";
echo "logfile /var/log/redis/redis-_RDPORT.log";
echo "dir /var/lib/redis/_RDPORT";
echo "appendonly no";
echo;
echo "# Cluster";
echo "cluster-enabled yes";
echo "cluster-config-file nodes-_RDPORT.conf";
echo "cluster-node-timeout 5000";
echo "cluster-require-full-coverage no";
echo "cluster-replica-validity-factor 10";
echo;
echo "# Uso de memória";
echo "maxmemory _RDMEM";
echo "maxmemory-policy allkeys-lru";
echo;
echo "# Segurança";
echo "requirepass _RDPASS";
echo "masterauth _RDPASS";
echo;
echo "# Limites";
echo "maxclients 4096";
echo "tcp-backlog 4096";
echo "timeout 0";
echo "tcp-keepalive 30";
echo;
echo "# Segurança";
echo "rename-command FLUSHDB \"\"";
echo "rename-command FLUSHALL \"\"";
echo "rename-command CONFIG \"CONFIG__RDPORT\"";
echo;
) > /etc/redis/template-cluster-redis.conf;
4.3 – Criar serviços Redis
Essa é a parte que todas as instâncias são criadas.
Vamos adotar a topologia master-only:
- 8 serviços Redis MASTER-only;
- Escutar em todos os IPs do servidor (0.0.0.0);
- Portas de 7001 a 7008;
- 2 GB de RAM por serviço;
- Senha de acesso: REDtulipa;
- Portas Gossip (automáticas): 17001 a 17008;

Setup do serviço:
# Caminho dos templates:
TEMPLATE_SERVICE="/etc/redis/template-service.conf";
TEMPLATE_REDIS="/etc/redis/template-cluster-redis.conf";
# Funcao para criar serviço e configuração:
setup_redis_service(){
xbin="$1"; # comando redis-server
xaddr="$2"; # ip de escuta
xport="$3"; # porta de escuta
xpwd="$4"; # senha
xmem="$5"; # limite de ram
# Arquivos da instancia
SERVICE_UNIT="/lib/systemd/system/redis-server-$xport.service";
REDIS_CONFIG="/etc/redis/redis-server-$xport.conf";
# Gerar config de servico systemd
cat "$TEMPLATE_SERVICE" \
| sed "s#_RDSRV#$xbin#g" \
| sed "s#_RDADDR#$xaddr#g" \
| sed "s#_RDPORT#$xport#g" \
| sed "s#_RDPASS#$xpwd#g" \
| sed "s#_RDMEM#$xmem#g" \
| sed "s#_RDCFG#$REDIS_CONFIG#g" \
> $SERVICE_UNIT;
# Gerar config do redis-server
cat "$TEMPLATE_REDIS" \
| sed "s#_RDSRV#$xbin#g" \
| sed "s#_RDADDR#$xaddr#g" \
| sed "s#_RDPORT#$xport#g" \
| sed "s#_RDPASS#$xpwd#g" \
| sed "s#_RDMEM#$xmem#g" \
> $REDIS_CONFIG;
# Preparar diretorios do servico
mkdir -p "/var/lib/redis/$xport";
chown redis:redis "/var/lib/redis/$xport";
};
run_redis_service(){
xport="$1"; # porta de escuta, usado no nome do servico
xsvcname="redis-server-$xport";
systemctl enable $xsvcname;
systemctl start $xsvcname;
};
# Criar servicos:
setup_redis_service /usr/bin/redis-server 0.0.0.0 7001 REDtulipa 2G;
setup_redis_service /usr/bin/redis-server 0.0.0.0 7002 REDtulipa 2G;
setup_redis_service /usr/bin/redis-server 0.0.0.0 7003 REDtulipa 2G;
setup_redis_service /usr/bin/redis-server 0.0.0.0 7004 REDtulipa 2G;
setup_redis_service /usr/bin/redis-server 0.0.0.0 7005 REDtulipa 2G;
setup_redis_service /usr/bin/redis-server 0.0.0.0 7006 REDtulipa 2G;
setup_redis_service /usr/bin/redis-server 0.0.0.0 7007 REDtulipa 2G;
setup_redis_service /usr/bin/redis-server 0.0.0.0 7008 REDtulipa 2G;
# Atualizar banco de dados do SystemD:
systemctl daemon-reload;
# Ativar e iniciar servicos:
run_redis_service 7001;
run_redis_service 7002;
run_redis_service 7003;
run_redis_service 7004;
run_redis_service 7005;
run_redis_service 7006;
run_redis_service 7007;
run_redis_service 7008;
Conferindo serviços em execução:
# Verificar processos do Redis:
ps ax | egrep redis-server;
# 28546 ? Ssl 0:00 /usr/bin/redis-server 0.0.0.0:7001 [cluster]
# 28622 ? Ssl 0:00 /usr/bin/redis-server 0.0.0.0:7002 [cluster]
# 28665 ? Ssl 0:00 /usr/bin/redis-server 0.0.0.0:7003 [cluster]
# 28709 ? Ssl 0:00 /usr/bin/redis-server 0.0.0.0:7004 [cluster]
# 28755 ? Ssl 0:00 /usr/bin/redis-server 0.0.0.0:7005 [cluster]
# 28801 ? Ssl 0:00 /usr/bin/redis-server 0.0.0.0:7006 [cluster]
# 28847 ? Ssl 0:00 /usr/bin/redis-server 0.0.0.0:7007 [cluster]
# 28894 ? Ssl 0:00 /usr/bin/redis-server 0.0.0.0:7008 [cluster]
# Status no SystemD
systemctl status redis-server-7001.service --no-pager | head -n 5;
systemctl status redis-server-7002.service --no-pager | head -n 5;
systemctl status redis-server-7003.service --no-pager | head -n 5;
systemctl status redis-server-7004.service --no-pager | head -n 5;
systemctl status redis-server-7005.service --no-pager | head -n 5;
systemctl status redis-server-7006.service --no-pager | head -n 5;
systemctl status redis-server-7007.service --no-pager | head -n 5;
systemctl status redis-server-7008.service --no-pager | head -n 5;
4.4 – Criando o cluster
Temos os serviços rodando, mas não temos Cluster. É necessário que os serviços sejam comunicados da existência de seus vizinhos e realizem o particionamento de slots seguido do monitoramento Gossip.
# Criar cluster com 8 masters (sem réplicas)
redis-cli \
-a REDtulipa \
--cluster create \
127.0.0.1:7001 \
127.0.0.1:7002 \
127.0.0.1:7003 \
127.0.0.1:7004 \
127.0.0.1:7005 \
127.0.0.1:7006 \
127.0.0.1:7007 \
127.0.0.1:7008 \
--cluster-replicas 0 \
--cluster-yes;
# >>> Performing hash slots allocation on 8 nodes...
# Master[0] -> Slots 0 - 2047
# Master[1] -> Slots 2048 - 4095
# Master[2] -> Slots 4096 - 6143
# Master[3] -> Slots 6144 - 8191
# Master[4] -> Slots 8192 - 10239
# Master[5] -> Slots 10240 - 12287
# Master[6] -> Slots 12288 - 14335
# Master[7] -> Slots 14336 - 16383
# ...
# >>> Nodes configuration updated
# >>> Assign a different config epoch to each node
# >>> Sending CLUSTER MEET messages to join the cluster
# Waiting for the cluster to join
# .
# [OK] All nodes agree about slots configuration.
# >>> Check for open slots...
# >>> Check slots coverage...
# [OK] All 16384 slots covered.
Cluster formado!
Conferindo informações do cluster:
# Verificar informações do cluster:
redis-cli -c -p 7001 -a REDtulipa cluster info;
# cluster_state:ok
# cluster_slots_assigned:16384
# cluster_slots_ok:16384
# cluster_slots_pfail:0
# cluster_slots_fail:0
# cluster_known_nodes:8
# cluster_size:8
# cluster_current_epoch:8
# cluster_my_epoch:1
# cluster_stats_messages_ping_sent:578
# cluster_stats_messages_pong_sent:570
# cluster_stats_messages_sent:1148
# cluster_stats_messages_ping_received:563
# cluster_stats_messages_pong_received:578
# cluster_stats_messages_meet_received:7
# cluster_stats_messages_received:1148
# total_cluster_links_buffer_limit_exceeded:0
# Ver nós do cluster:
redis-cli -c -p 7001 -a REDtulipa cluster nodes;
# ... 127.0.0.1:7002@17002 master - 0 1763001703000 2 connected 2048-4095
# ... 127.0.0.1:7007@17007 master - 0 1763001703990 7 connected 12288-14335
# ... 127.0.0.1:7005@17005 master - 0 1763001702000 5 connected 8192-10239
# ... 127.0.0.1:7003@17003 master - 0 1763001702984 3 connected 4096-6143
# ... 127.0.0.1:7001@17001 myself,master - 0 0 1 connected 0-2047
# ... 127.0.0.1:7006@17006 master - 0 1763001702000 6 connected 10240-12287
# ... 127.0.0.1:7008@17008 master - 0 1763001702000 8 connected 14336-16383
# ... 127.0.0.1:7004@17004 master - 0 1763001703587 4 connected 6144-8191
# Verificar slots distribuídos:
redis-cli -c -p 7001 -a REDtulipa cluster slots;
# Testar conectividade em todos os nós
for port in {7001..7008}; do
echo "# Porta ${port}: $(redis-cli -p ${port} -a REDtulipa ping 2>/dev/null)";
done;
# Verificar uso de memória:
for port in {7001..7008}; do
echo -n "# Redis - Porta ${port} - ";
redis-cli -p ${port} -a REDtulipa info memory 2>/dev/null \
| grep used_memory_human;
done 2>/dev/null;
# Verificar número de chaves em cada nó:
for port in {7001..7008}; do
echo "Porta ${port}: $(redis-cli -p ${port} -a REDtulipa dbsize 2>/dev/null)";
done;
# Inserir dados de teste:
for i in {1..100}; do
redis-cli -c -p 7001 -a REDtulipa SET "teste:key:${i}" "valor${i}" 1>/dev/null;
done;
# Verificar distribuição:
echo "Distribuicao de chaves:";
redis-cli -c -p 7001 -a REDtulipa --cluster info 127.0.0.1:7001 2>/dev/null;
# Rebalancear slots:
redis-cli -c -p 7001 -a REDtulipa --cluster rebalance 127.0.0.1:7001;
# Ver logs de um nó específico:
tail -f /var/log/redis/redis-7001.log;
# Ver logs de todos os nós:
tail -f /var/log/redis/redis-*.log;
Testando capacidade básica do cluster:
# Testando capacidade do cluster:
redis-benchmark \
-h 127.0.0.1 -p 7001 \
-a REDtulipa \
-c 50 \
-n 100000 \
-t set,get \
--cluster -q;
# SET: 195312.48 requests per second, p50=0.087 msec
# GET: 199600.80 requests per second, p50=0.087 msec
Em operações set/get o cluster atingiu 195 mil requisições por segundo, muito superior às 20 mil requisições da instância simples.
5 – Tuning da instância Redis
Vamos abordar algumas alterações no sistema para beneficiar o Redis.
Configurações recomendadas no Redis para mais performance no uso da CPU e RAM:
maxmemory-samples 3
lazyfree-lazy-eviction yes
lazyfree-lazy-expire yes
lazyfree-lazy-server-del yes
lazyfree-lazy-user-del yes
lazyfree-lazy-user-flush yes
replica-lazy-flush yesmaxmemory-samples: Atua na remoção de chaves ao atingir limite de RAM.
- maxmemory-samples 3: baixo uso de CPU, latência mínima, melhor performance e velocidade;
- maxmemory-samples 5: Amostra 5 chaves, padrão do Redis;
- maxmemory-samples 10: Amostra 10 chaves, mais preciso, maior uso de CPU, latência maior);
- maxmemory-samples 20: Foco apenas em precisão, performance ruim e muito uso de CPU;
Ativar lazyfree-lazy-expire e lazyfree-lazy-eviction: Atua limpando a RAM em segundo plano (outra thread do processo). Garante de 10x a 100x mais performance.
Ativar lazyfree-lazy-server-del remove uma chave cujo valor foi alterado em segundo plano.
Ativar replica-lazy-flush a sincronia e limpeza com a réplica (master-réplica) em background.
Configurações para melhorar performance de I/O (escrita em disco) são necessárias apenas se você utilizar AOF (log de operações) ou RDB (Snapshots da RAM) para salvar as chaves do Redis em arquivos (persistência).
io-threads 8
io-threads-do-reads yes
appendfsync everysec
no-appendfsync-on-rewrite yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mbConfigurar io-threads permite que o Redis paralelize a escrita em disco, descarregando o trabalho para o sistema operacional com mais rapidez. Configure em 25% da quantidade de núcleos do sistema (8 io-threads para 32 núcleos de CPU).
A instrução appendfsync acionar o sync do S.O., obrigando o sistema de arquivos a gravar efetivamente os dados no disco (mover do cache de escrita atrasada para o HD/SSD/NVME). O valor “always” mantem o sincronismo constante (mais lento), mas garante dados mais consistentes em caso de parada, enquanto que “everysec” realiza a operação a cada 1 segundo.
Aumentar o limite de file descriptors
Esse recurso permite extender a capacidade do Redis para abrir conexões e alocar memória com mais rapidez. Você tambem pode adicionar “LimitNOFILE=65535” na configuração do serviço no SystemD.
# Expandir soft-limit e hard-limit do Redis
(
echo;
echo '# Redis Limits';
echo 'redis soft nofile 65535';
echo 'redis hard nofile 65535';
echo 'redis soft nproc 65535';
echo 'redis hard nproc 65535';
echo;
) > /etc/security/limits.d/71-redis.conf;
Recomendo um estudo profundo do arquivo “/etc/security/limits.conf“.
6 – Tuning do Kernel Linux
Vou abordar uma série de alterações no Linux para privilegiar o Redis.
Desativar SWAP
Por padrão o kernel inicia o uso de SWAP (memória simulada em disco/partição) quando o uso de memória real chega em 40% (swappness=60), o ideal é que isso só aconteça quando a RAM realmente acabar.
# Nao usar SWAP enquanto houver memoria RAM livre
# - Para aplicar durante o boot:
echo "vm.swappiness=0" > /etc/sysctl.d/073-swappiness.conf;
# - Aplicar imediatamente:
sysctl -w "vm.swappiness=0";
# - Reiniciar swap (opcional):
swapoff -a; # Limpar e desligar
swapon -a; # Ligar.
Overcommit de memória
O kernel linux, por padrão (overcommit_memory=0), aceita alocar a quantidade de memória para qualquer programa, desde que seja possível, mas não garantido, que haverá memória quando o programa realmente começar a usá-la, ele decide iso usando métodos heurísticos. Existe a chance do kernel não entregar a memória solicitada.
Ajustando overcommit_memory=1 o kernel simplesmente entrega a quantidade de memória que o programa pedir. Em um servidor com 8G de RAM, se o Redis pedir 80G ele receberá o ponteiro de memória virtual.
Ajustar o overcommit_memory=2 é desaconselhado pois só alocará memória ao processe se puder reservá-la exclusivamente para ele.
Em todos os casos, quando o programa utilizar mais memória virtual do que o total do sistema (memória virtual = memória física + swap), ele será morto com o sinal OOM (out-of-memory).
O melhor valor para o Redis é garantir mais liberalidade do kernel durante alocações:
# Garantia na alocacao de memoria virtual
# - Para aplicar durante o boot:
echo "vm.overcommit_memory = 1" > /etc/sysctl.d/075-overcommit-memory.conf;
# - Aplicar imediatamente:
sysctl -w "vm.overcommit_memory=1";
Huge Pages
Por padrão o kernel aloca a memória virtual em pedaços de 4KB. Isso é bom para aplicações pequenas e pontuais mas é péssimo para sistemas que alocam grandes volumes de memória.
Ativar o HP no kernel permite ter páginas de 2M (huge pages) a 1 G (giant pages). Você pode encontrar uma explicação mais completa em:
Ativar HugePages: em um sistema com 32G de RAM, usar 25% em paginas de 1G (8G, 8 páginas), 50% em páginas de 2M (16G, 4096 páginas);
# Opcoes de hugepages:
HPTHPG="transparent_hugepage=never";
HPDEF1="default_hugepagesz=1G hugepagesz=1G hugepages=16";
HPDEF2="hugepagesz=2M hugepages=4096";
# Gravar na config do GRUB:
GRUBVAR="GRUB_CMDLINE_LINUX";
sed -i "s#^$GRUBVAR=.*#$GRUBVAR=\"$HPTHPG $HPDEF1 $HPDEF2\"#" /etc/default/grub;
# Conferir:
cat /etc/default/grub | grep "$GRUBVAR=";
# Atualizar bootloader:
grub-mkconfig -o /boot/grub/grub.cfg;
# Necessario reiniciar: reboot
Conferir após reboot:
# Conferir configuracao de hugepages:
sysctl -a | grep "hugepages";
# vm.nr_hugepages = 16
# vm.nr_hugepages_mempolicy = 16
# vm.nr_overcommit_hugepages = 0
Transparent Huge Pages
O Transparent Huge Pages (THP) é um recurso do kernel Linux que aloca dinamicamente páginas de memória maiores para melhorar o desempenho, reduzindo a sobrecarga do gerenciamento de páginas menores. Ele funciona consolidando páginas padrão de 4 KB em páginas maiores de 2 MB, o que pode aumentar o desempenho de aplicativos com acesso contíguo à memória. No entanto, o THP pode impactar negativamente aplicativos com padrões de acesso à memória não contíguos, como bancos de dados e Redis, sendo frequentemente recomendado desativá-lo para essas cargas de trabalho específicas.
# Desabilitar THP
(
echo 'w /sys/kernel/mm/transparent_hugepage/enabled - - - - never';
echo 'w /sys/kernel/mm/transparent_hugepage/defrag - - - - never';
) > /etc/tmpfiles.d/disable-thp.conf;
# Aplicar imediatamente:
systemd-tmpfiles --create /etc/tmpfiles.d/disable-thp.conf
Rede acelerada
Os valores padrões do kernel linux não favorecem um grande número de conexões paralelas para um cluster e para muitos clientes conectados ao Redis. Vamos melhorar isso:
# Aumentar capacidades de rede do protocolo TCP
(
echo "net.ipv4.tcp_sack = 1";
echo "net.ipv4.tcp_timestamps = 1";
echo "net.ipv4.tcp_low_latency = 1";
echo "net.ipv4.tcp_max_syn_backlog = 8192";
echo "net.ipv4.tcp_rmem = 4096 87380 67108864";
echo "net.ipv4.tcp_wmem = 4096 65536 67108864";
echo "net.ipv4.tcp_mem = 6672016 6682016 7185248";
echo "net.ipv4.tcp_congestion_control=htcp";
echo "net.ipv4.tcp_mtu_probing=1";
echo "net.ipv4.tcp_moderate_rcvbuf =1";
echo "net.ipv4.tcp_no_metrics_save = 1";
) > /etc/sysctl.d/052-net-tcp-ipv4.conf;
# Liberar mais RAM para aceleração de rede
(
echo "net.core.rmem_default=31457280";
echo "net.core.wmem_default=31457280";
echo "net.core.rmem_max=134217728";
echo "net.core.wmem_max=134217728";
echo "net.core.netdev_max_backlog=250000";
echo "net.core.optmem_max=33554432";
echo "net.core.default_qdisc=fq";
echo "net.core.somaxconn=4096";
) > /etc/sysctl.d/051-net-core.conf;
# Ativar TCP-Fast-Open
(
echo "net.ipv4.tcp_fastopen=3";
) > /etc/sysctl.d/053-tcp-fast-open.conf;
# Ativar TCP-KeepAlive
(
echo "net.ipv4.tcp_keepalive_probes=9";
echo "net.ipv4.tcp_keepalive_intvl=75";
echo "net.ipv4.tcp_keepalive_time=7200";
) > /etc/sysctl.d/054-tcp-keepalive.conf;
# Aplicar imediatamente:
sysctl -q --system 2>/dev/null;
sysctl -q -p 2>/dev/null;
NUMA
NUMA (Non-Uniform Memory Access) é um recurso de hardware e software, requer configuração na BIOS e no sistema operacional. Esse recurso está presente em servidores com mais de 1 processador físico (socket).
O comportamento da BIOS pode ser UMA (Uniform Memory Access), ou Interleave (intercalar). Isso sincroniza o acesso à memória total (unificada) presente nos sockets, o que eleva levemente a latência de acesso a RAM. O sistema operacional não pode fazer nada a respeito disso pois é um SET de hardware.
Quando existem dois sockets em modo NUMA, eles rodam mais independentes com cada socket lidando com seus pentes de memória RAM.
O NUMA no sistema operacional (software) permite que processos rodando nos núcleos do socket 0 (primeira CPU, NUMA Node 0) acessem a memória RAM do socket 1 (segunda CPU, NUMA Node 1) por meio de um link entre os dois sockets. Isso é chamado de acesso remoto e possui performance pior que o acesso local.
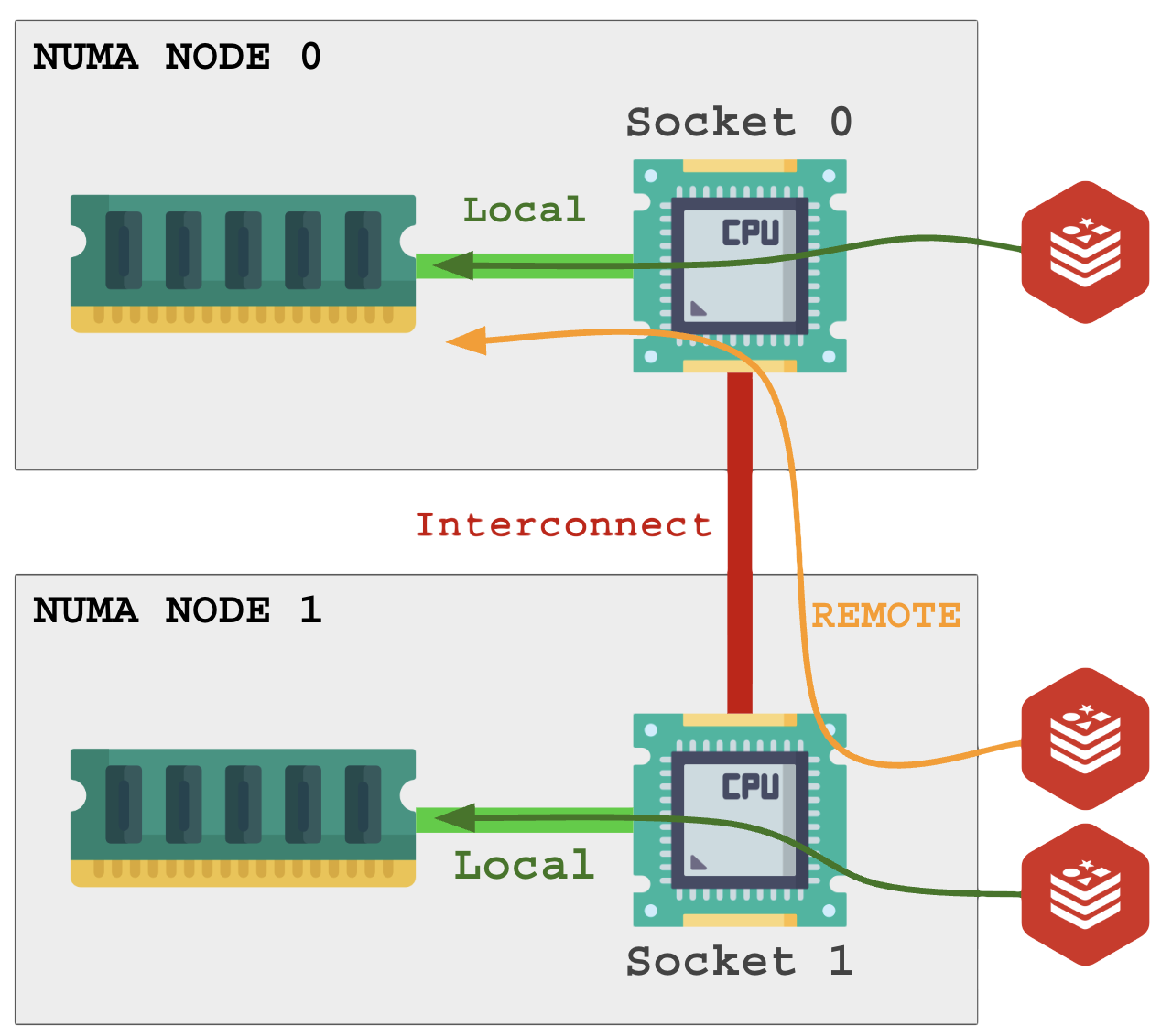
É ideal para o Redis que a memória utilizada seja local. Para garantir isso, cada processo precisa ser restrito a um núcleo específico e proibido de acessar a memória do processador vizinho.
O segundo problema surge quando, em um sistema com 32 GB de RAM onde existem 16 GB em cada socket, um único processo precisa acessar mais do que existe do seu lado.
Visualizando seu ambiente de hardware:
# Instalar pacotes necessários;
apt -y install numactl hwloc util-linux;
# Conferir comandos:
echo "# numactl: $(numactl --version)";
echo "# lstopo.: $(lstopo --version)";
echo "# taskset: $(taskset --version)";
# Conferir se o ambiente possui NUMA (2 sockets nao unificados):
numactl --hardware;
# available: 2 nodes (0-1)
#.
# node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# node 0 size: 16021 MB
# node 0 free: 2913 MB
#.
# node 1 cpus: 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
# node 1 size: 16121 MB
# node 1 free: 3542 MB
# node distances:
#.
# node 0 1
# 0: 10 20
# 1: 20 10
#.
# Visualizar topologia de sockets, nucleos e memorias:
lstopo;
lstopo --of console;
# Ver CPUs por socket
lscpu | grep -E "Socket|Core|Thread|NUMA";
Observe cuidadosamente quais núcleos de CPU estão em cada Numa Node antes de iniciar as restrições.
Para restringir um processo em um núcleo específico, adicione na UNIT de serviço do SystemD com os seguintes parâmetros, leia os parâmetros e comentários com atenção:
[Service]
# Restringir para CPU 1 (segundo núcleo), 16 nucleos = nucleos de 0 a 15
CPUAffinity=1
# Desabilitar balanceamento automático do kernel
CPUSchedulingPolicy=fifo
CPUSchedulingPriority=1
# Exemplos:
# Limitar a varios nucleos: 0-7 (8 primeiros nucleos)
# CPUAffinity=0-7
#
# Limitar aos nucleos impares de 0 a 15, 8 nucleos
# CPUAffinity=1,3,5,7,9,11,13,15
#
# Limitar nas primeiras 4 e ultimas 4 do mesmo socket:
# CPUAffinity=0-3,12-15
A segunda forma é apenas colocar o comando numactl antes do comando redis-server, exemplo:
[Service]
# Executar com numactl
# --physcpubind=1 - Rodar SOMENTE na CPU 1 (segundo nucleo)
# --membind=0 - Usar SOMENTE memória do NUMA NODE 0 (socket 0)
# --localalloc - Alocar memória localmente ao nó
ExecStart=/usr/bin/numactl --physcpubind=1 --membind=0 --localalloc /usr/bin/redis-server /etc/redis/cluster/7001/redis.conf --supervised systemd
# CPU Affinity via systemd (redundante, mas garante)
CPUAffinity=1
# Desabilitar balanceamento automático do kernel
CPUSchedulingPolicy=fifo
CPUSchedulingPriority=1
Após alterar a configuração do serviço, atualize o SystemD e reinicie o serviço:
# Atualizar SystemD:
systemctl daemon-reload;
# Reiniciar servico (exemplo para redis-server na porta 7001):
systemctl "redis-server-7001" stop;
systemctl "redis-server-7001" start;
# Conferir em quais nucleos o servico pode rodar:
taskset -cp $(pgrep -f "redis-server.*7001");
7 – Monitorando o Redis
Extraindo informações sobre a execução:
# Extrair informacoes (use -a "REDtulipa" para informar a senha"):
# Criar comando de base para conectar no Redis Cluster
# - cc = cluster-client
alias redis-cc="redis-cli -h 127.0.0.1 -p 7001 -c -a REDtulipa";
redis-cc --stat;
redis-cc --latency;
redis-cc --latency-history;
redis-cc --latency-dist;
redis-cc --intrinsic-latency 100;
redis-cc --bigkeys;
redis-cc --memkeys;
redis-cc INFO all;
redis-cc INFO stats;
redis-cc INFO memory;
redis-cc INFO replication;
redis-cc CLUSTER info;
redis-cc CLUSTER nodes;
redis-cc CLUSTER slots;
#redis-cc CLUSTER reset;
redis-cc DBSIZE;
# Acompanhar logs de um nó específico:
tail -f /var/log/redis/redis-7001.log;
# Acompanhar logs de todos os nós:
tail -f /var/log/redis/redis-*.log;
8 – Testes de performance
De acordo com a RFC 2544 (Benchmarking Methodology for Network Interconnect Devices), a entidade que faz o teste não deve rodar na mesma entidade que sofre o teste.
Obviamente, se nosso software de teste consome 60% de CPU, sobrará apenas 40% de CPU para o software servidor processar os pedidos, e ele entregará um resultado ruim por culpa do próprio testador!
Vamos ignorar isso e fazer do jeito errado mesmo! Testador e testado no mesmo ambiente.
Os testes na instância padrão ajudam a ter como referência as capacidades naturais do Redis em seu servidor. Tome nota dos testes iniciais antes de montar o Cluster.
# Testes de capacidade
# Criar comando de base para conectar no Redis Cluster
# - bc = benchmark-client
alias redis-bc="redis-benchmark -h 127.0.0.1 -p 7001 --cluster -a REDtulipa";
# 1 - Testes basicos do Redis
# 1.1 - Use 20 parallel clients, for a total of 100k requests:
redis-bc -n 100000 -c 20;
# Summary:
# throughput summary: 44762.76 requests per second
# latency summary (msec):
# avg min p50 p95 p99 max
# 0.240 0.088 0.239 0.271 0.423 1.455
# 1.2 - Fill 127.0.0.1:6379 with about 1 million keys only using the SET test:
redis-bc -t set -n 1000000 -r 100000000;
# Summary:
# throughput summary: 46251.33 requests per second
# latency summary (msec):
# avg min p50 p95 p99 max
# 0.563 0.176 0.559 0.687 0.879 4.247
# 1.3 - Benchmark 127.0.0.1:6379 for a few commands producing CSV output:
redis-bc -t ping,set,get -n 100000 --csv;
# 1.4 - Benchmark a specific command line:
redis-bc -r 10000 -n 10000 eval 'return redis.call("ping")' 0;
# Summary:
# throughput summary: 46511.63 requests per second
# latency summary (msec):
# avg min p50 p95 p99 max
# 0.564 0.160 0.551 0.639 0.887 2.519
# 1.5 - Fill a list with 10000 random elements:
redis-bc -r 10000 -n 10000 lpush mylist __rand_int__;
# Summary:
# throughput summary: 43290.04 requests per second
# latency summary (msec):
# avg min p50 p95 p99 max
# 0.596 0.152 0.575 0.703 0.839 2.327
# 2.0 - Teste realista:
# - 20 mil requisicoes
# - fazer 1.000 requisoes em paralelo
# - criar chaves com valores de 1024 bytes
# - 8 threads de CPU em paralelo
# - pipilene de 8 requisicoes em serie
# - 6 digitos de precisao no resultado
redis-bc \
-n 20000 -c 1000 \
-d 1024 \
--threads 8 \
-P 8 \
--precision 6;
# Summary:
# throughput summary: 78125.00 requests per second
# latency summary (msec):
# avg min p50 p95 p99 max
# 26.382 2.024 28.655 34.999 48.239 61.807
# 3.0 - Teste extremo: armazenando documentos no REDIS
# - 200 documentos por requisicoes
# - fazer 10 requisoes em paralelo
# - criar chaves com valores de 1024000 bytes (1 MB)
# - 16 threads de CPU em paralelo
# - pipilene de 1 requisicao por vez
# - 6 digitos de precisao no resultado
redis-bc \
-n 200 -c 10 \
-d 1024000 \
--threads 8 \
-P 1 \
--precision 6;
9 – Backup e recuperação
É importante fazer o backup de todas as configurações e arquivos para uma recuperação rápida do ambiente. Procedimentos:
9.1 – Backup
# Pasta para guardar backups:
mkdir -p /storage/backup;
# Nome do host
HNAME=$(hostname -f || hostname);
# Data e hora
DTIME=$(date '+%Y-%m-%d-%H%M');
# Nome do arquivo de backup:
BCKFILE="/storage/backup/redis-backup-$HNAME-$DTIME.tgz";
# Extrair informacoes do sistema caso seja
# necessario analisar o backup (casos de caos!)
_exec_and_md(){
echo "## $1"; # titulo
echo "Comando: $1"; # comando
echo '```stdout'; # abrir bloco de informacao
eval "$1" 2>/dev/null; # rodar comando
echo '```'; # fechar bloco de informacao
echo;
};
# Criar arquivo MD com relatorio do sistema:
(
echo '# Linux - Report';
# config linux
_exec_and_md 'hostname';
_exec_and_md 'hostname -f';
_exec_and_md 'cat /etc/hostname';
_exec_and_md 'cat /etc/hosts';
_exec_and_md 'cat /etc/os-release';
_exec_and_md 'cat /etc/machine-id';
_exec_and_md 'cat /etc/passwd';
_exec_and_md 'env';
_exec_and_md 'set';
# process
_exec_and_md 'ps aux';
_exec_and_md 'cat /proc/cpuinfo';
_exec_and_md 'cat /proc/meminfo';
_exec_and_md 'cat /proc/mounts';
_exec_and_md 'lsmod';
# filesystem
_exec_and_md 'fdisk -l';
_exec_and_md 'df';
_exec_and_md 'df -h';
_exec_and_md 'lsblk';
_exec_and_md 'lsblk --output-all -J';
# network
_exec_and_md 'ip -4 addr show';
_exec_and_md 'ip -6 addr show';
_exec_and_md 'ip -4 route show';
_exec_and_md 'ip -6 route show';
_exec_and_md 'nft list ruleset';
# hardware
_exec_and_md 'lscpu';
_exec_and_md 'lspci';
_exec_and_md 'lsirq';
_exec_and_md 'lstopo';
_exec_and_md 'lspci -vvv';
# docker
_exec_and_md 'docker ps -a';
_exec_and_md 'docker image ls';
_exec_and_md 'docker network ls';
) > /etc/REPORT.md;
# Gerar arquivo de backup
# - configurações do systemd
# - configurações do Redis
# - arquivos de dados
tar -cpzvf $BCKFILE \
/etc/REPORT.md \
/etc/redis \
/var/lib/redis \
lib/systemd/system/redis-* \
/etc/logrotate.d/redis-server \
/etc/default/redis-server \
var/log/redis;
O script acima criará o arquivo TGZ contendo tudo que diz respeito ao Redis, adapte-o para fazer backup das demais necessidades dos sistemas que você utiliza no mesmo servidor.
9.2 – Recuperação
A recuperação de backup é uma tarefa crítica, teste-a em ambiente de laboratório antes de recuperar encima de um sistema em produção.
Para recuperar o sistema utilizando backup, siga os procedimentos:
- Instale todos os programas (apt -y install …);
- Extraia o backup na raiz (/) do sistema;
- Reinicie o servidor;
Comandos:
# Arquivo de backup escolho:
RESTORE="/storage/backup/redis-backup-cloud01.tmsoft.com.br-2025-11-19-1150.tgz";
# Descomprimir no /
tar -xvf $RESTORE -C /;
# Reiniciar servidor: reboot
Pode ser necessário registrar novamente os serviços para que eles subam automaticamente após o reboot (systemctl enable …).
O ideal é que seu ambiente seja montado com um script de setup, um script de backup e um script de recuperação, assim você agiliza todo o processo de maneira linear.
Bom…
Terminamos por hoje!
Patrick Brandão, patrickbrandao@gmail.com