
Saudações.
Resolvi criar escrever artigo para apresentar de maneira pontual duas maneiras de criar softwares, passando pelos detalhes técnicos e concluindo com preceitos administrativos.
1 – O que é um Monolito
Em engenharia de software, um software “arquivo completo” é chamado de monolito.
Se um software fosse comparado a uma empresa, o monolito seria um profissional autônomo formado em várias faculdades, sabe tudo sobre o negócio e faz tudo sozinho, tem 18 braços e 32 pernas – uma centopéia!
Um monolito é um estilo de design em que toda a aplicação é construída e implantada como uma única unidade coesa que se torna um único processo em execução.
Um software que faz renderização feita como monolito vai usar CPU, RAM, GPU, DISCO em um único processo no sistema operacional para satisfazer os pedidos de único pedido do usuário. Cada função dentro do software pode chamar (CALL/STACK) outra função diretamente saltando para seu espaço na memória do processo. Isso recebe o nome de “acoplamento forte“.
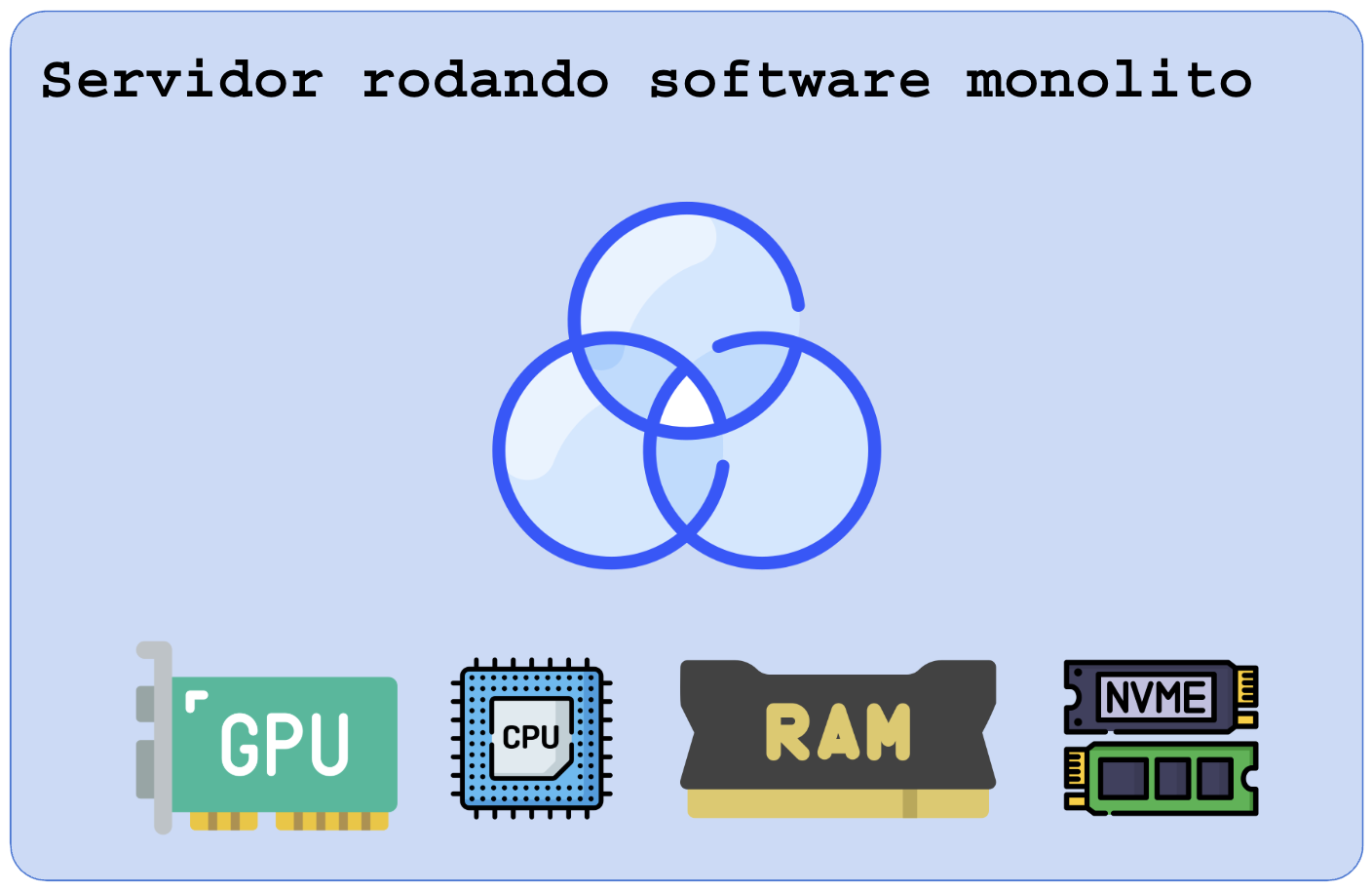
Para permitir que o monolito faça várias tarefas ao mesmo tempo o programador faz chamada de sistemas para abrir threads, cada thread é um braço trabalhando em uma tarefa específica mas ligado ao corpo. Tudo no mesmo PID (process id), todos acessando os mesmos endereços na memória (perigoso).
Para construir sistemas para muitos usuários – milhares a milhões é quase impossível criar como monolito pois não sabemos quanto de hardware cada setor do software vai precisar. Acabaremos por super-dimensionar, gastando mais dinheiro do que precisa ou sub-dimensionar e deixar o sistema em crise de indisponibilidade.
A engenharia de software vai ficando impossível pois uma thread maluca pode quebrar tudo instantaneamente. Procurar bugs é como achar agulha no palheiro.
Para simplificar um monolito gigantesco, cada pedaço do software (funções principais coesas) são separados em serviços independentes. Isso se chama arquitetura de micros-serviços.
2 – O que é a arquitetura de microsserviços
Arquitetura de microsserviços é um estilo de design em que a aplicação é dividida em um conjunto de serviços pequenos, independentes e autônomos, cada um responsável por uma capacidade de negócio específica.
Como cada serviço vira um processo com espaço de memória isolada, como um serviço vai pedir a outro que processe uma informação e devolva o resultado?
Temos as seguintes opções:
- IPC: quando os serviços estão rodando juntos no mesmo sistema operacional e CPU e querem se comunicar sem usar a rede ethernet ou TCP/IP:
- Shared Memory: espaço de memória compartilhada que os processos podem escrever e ler dados juntos;
- Unix Domain Sockets: arquivo virtual de I/O criado por um processo servidor e os processos clientes que abrem o arquivo para se comunicar por ele;
- Pipes e Named Pipes (FIFOs): canais unidirecionais (ou bidirecionais, com dois pipes) para fluxo de bytes entre processos;
- Message Queues (POSIX): filas de mensagens gerenciadas pelo kernel;
- Semaphore e signals: sinais trocados entre processos para disparar procedimentos uns nos outros;
- Pilha TCP/IP: utiliza conexões baseadas em endereço IP;
- Loopback: quandos os processos abrem portas locais no mesmo sistema operacional usando o IP interno do sistema – 127.0.0.1 (IPv4) ou ::1 (IPv6);
- Intranet ou Internet: quando os processos estão rodando em servidores ou containers diferentes e cada processo utiliza um endereço IP, a conexão passa pela rede local e/ou pela Internet;
A pilha TCP/IP é preferida pois permite separar os serviços e espalha-los em vários servidores diferentes.
A solução agora se torna escalável e traz consigo novos desafios.
Qual o padrão de comunicação entre os serviços? Quais as tolerâncias a falhas e latência?
As opções mais utilizadas são:
- API REST: opta-se pelo protocolo HTTP e cada serviço tem sua URL e sua forma de receber pedidos e apresentar respostas, normalmente utilizando métodos HTTP como comandos (GET, POST, PUT, DELETE, PATH) e payload JSON como formato de dados (converter listas, objetos e valores em texto transportável);
- JRPC (JSON – Remote Procedure Call): Utiliza qualquer canal IP (principalmente HTTP) para enviar um JSON pedindo o nome da função desejada e fornecendo seus argumentos, recebendo uma resposta tambem em formato JSON, muito comum como API HTTP JRPC;
- gRPC (Google Remote Procedure Call): É uma versão do Google focada em usar HTTP/2 para transporte e Protocol Buffers (Protobuf) como linguagem de definição de interface binária (formato das mensagens);
- WebSocket: protocolo simples baseado em TCP para troca de dados entre cliente e servidor em tempo real. Tem foco em comunicação binária e em conexões persistentes (jogos online, dashboards, gráficos em tempo real);
- AMQP: principal protocolo de mensageria (alem de MQTT e STOMP) onde os serviços se comunicam por mensagens utilizando um servidor central (broker). É a melhor solução para visibilidade da comunicação entre todos os serviços embora induza maior latência entre pedido e resposta;
- Claim Check Pattern: também chamado de Reference-Based Messaging, é uma forma híbrida de construir a comunicação entre serviços buscando velocidade de acionamento (event notification) e suporte a transação (exclusividade):
- O software remetente (produtor) armazena o payload completo em um data store persistente, como um servidor PostegreSQL e obtém um identificador (ID ou UUID, o “claim check”, como um ticket de bagagem), a coluna “dono” está vazia (NULL);
- Esse identificador é publicado em um canal de mensagens instantâneas como o Redis via canal Pub/Sub (e opcionalmente em uma lista stack para coleta atrasada);
- O consumidor (“C1”) que participa do canal Pub/Sub recebe imediatamente a mensagem do novo pedido e tenta localizar e assumir o registro no banco de dados usando o identificador;
- UPDATE jobs SET dono = “C1” WHERE dono = NULL AND id = 918282;
- SELECT * FROM jobs WHERE dono = “C1” AND id = 918282;
- Quando vários consumidores participam do canal o sistema favorece quem reagir primeiro, sistemas assim podem não balancear bem as tarefas, um servidor próximos ao Redis e PG vão assumir mais tarefas que os outros, alem de outros motivos com largura de banda, capacidade de ciclos por segundo, etc;
- O administrador acaba induzindo atrasos propositais em consumidores bons para deixar consumidores lentos trabalharem um pouco;
Embora existem muita maneiras, podemos classificá-las como dois tipos:
- Point to point (ad-hoc): cada serviço sabe o endereço exato (IP e porta, URL) do serviço que precisa e vai até ele pedir. É o mais simples e portanto o método mais preferido para sistemas pequenos. Depende de balanceadores intermediários para escalar;
- Hub and spoke (bespoke/homegrown): cada sistema tem um ponto central (HUB, mensageria) onde os serviços se conectam para submeter e coletar trabalho. É a maneira mais simples de escalar e investigar as comunicações pois o HUB dá essa visibilidade;
Você tem liberdade criativa para criar seu hibrido.
Um HUB usando WebSocket é valioso em pequenos jogos online.
Um HUB baseado em Claim Check encima de um cluster Redis (Pub/Sub e listas empilhadas) pode ser melhores para grandes jogos online.
Visão geral de um sistema rodando serviços se comunicando pelo RabbitMQ:
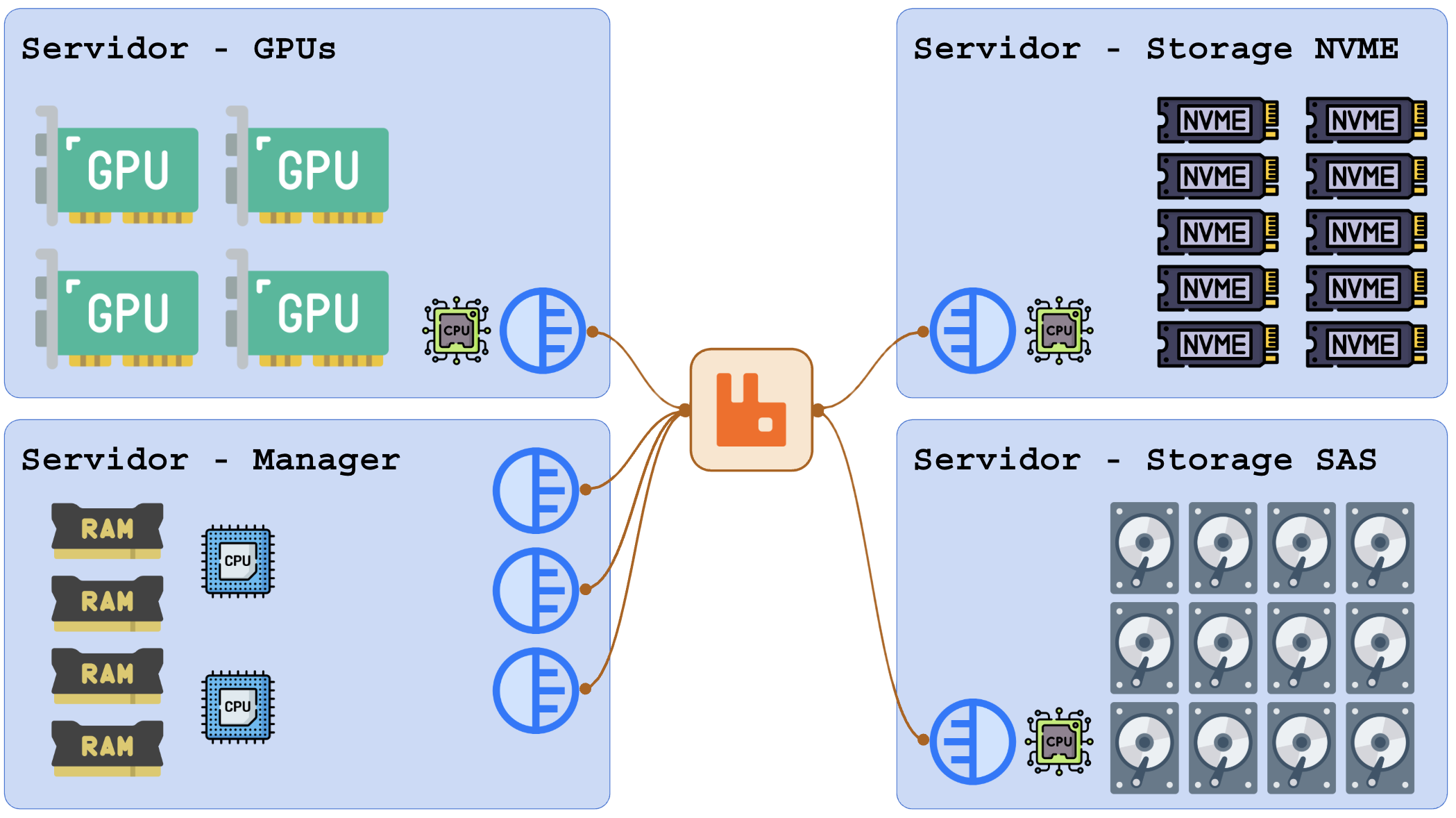
Esse ambiente pode escalar horizontalmente adicionando mais servidores mas com foco em adicionar o tipo que está acabando. Se as GPUs ficarem saturadas você adiciona apenas mais servidores de GPU.
3 – Composable Architecture
Em tradução livre: “arquitetura componível”. É a forma elegante de dizer “não reinvente a roda, use uma roda pronta, barata que encaixe bem”.
É focada em utilizar componentes prontos para colocar o sistema em produção o mais rápido e barato possível.
O principio é montar um sistema compondo peças independentes e intercambiáveis inicialmente baseadas em softwares gratuitos (Redis para cache, Postgres para SQL, Nginx para balanceamento, Traefik para proxy-reverso, Minio para S3, RabbitMQ para mensageria, Prometheus para observabilidade).
O termo “FOSS Stack Composition” ou simplesmente stack composition foca em montar uma stack a partir de projetos de código aberto.
Best-of-Breed Architecture: selecionar a melhor ferramenta disponível para cada função específica, em vez de construir ou usar uma suíte monolítica.
Quando o sistema fica pronto você pode se dar ao trabalho de melhorar as partes (Trocar o Redis pelo Dragonfly, trocar Prometheus por Datadog, migrar de Postgres para Supabase).
Essa arquitetura emerge do dilema comprar (buy) ou construir (build).
Quando seu software precisa lidar com milhares a milhões de uploads de fotos por mês, como você precisa entregar esse serviço funcionando em 8 horas? Você precisa de:
- API para receber e arquivar objetos;
- API para recuperar objetos;
- Tags para identificar objetos de um autor (cliente);
- Gestão de chaves de API com diferentes provilégios;
- Controle de versão: alterar sem perder a versão anterior;
- Deduplicar: impedir que objetos duplicados consumam espaço adicional;
- Snapshot: Backup e restauração com suporte a linha do tempo;
- Distribuição: espalhar por várias regiões para melhorar a latência.
Os pontos a ponderar são:
- Construir (build): Vai demorar até o seu próprio software se tornar maduro e o investimento pode nunca retornar. Cada linha de software é um passivo financeiro, você precisará de capacitação profissional própria ou contratada (consultoria), departamento P&D, suporte é problema, haja manual, anotações, sistema de projetos para não se perder nas tarefas, etc;
- Comprar (buy): Pagar pelo serviço é barato, ativação imediata e cobrança por volume, o suporte é terceirizado e pode escalar com upgrade para planos Premium;
Obviamente se ficarmos pagando por tudo, teremos uma avalanche de pequenas cobranças mensais. Seu diretor financeiro bloqueia uma cobrança de $40 e o DNS da empresa desaparece!
Um software gratuito de código aberto com comunidade ativas é um ótimo alvo. Se você não encontra um sistema 100% perfeito mas achou um que tem 98% do que você precisa e o responsável pelo projeto aceita dinheiro para mudar a direção do barco – pague-o!
Esse problema em software se repete no hardware: comprar (buy) ou alugar (lease).
É por conta das conclusões desses dilemas que tanta gente se pendura encima das empresas:
- CloudFlare;
- Amazon AWS;
- Akamai;
- Microsoft Azure;
- Supabase ou Firebase.
Elas saem do ar e você ouve gritos pra todo lado!
No mundo empresarial a filosofia de “undifferentiated heavy lifting” (termo popularizado pela AWS): você não deveria gastar esforço construindo o que não é o diferencial do seu produto.
“Parabéns! Você reinventou a roda. Pena que ela agora é quadrada.”
Autor desconhecido
Terminamos por hoje!
Patrick Brandão, patrickbrandao@gmail.com