
Saudações. Nesse artigo vamos instalar e usar uma inteligência artificial rodando no nosso próprio servidor local. Teremos nossa IA exclusiva!
Primeiramente, eis o link da minha comunidade sobre IA e automação:
https://chat.whatsapp.com/HrODrRZ1G5kBzV997jSKa6
Em nossa IA local Nele poderemos pedir tudo sem medo de vazamento de dados. Podemos jogar todos os dados de nossos clientes e seus documentos para analise sem perigo de violar a LGPD (lei geral de proteção de dados).
Teremos IA para conversas rápidas, conversas profundas, analise de documentos para tomada de decisões, conversas sem restrições ou lições de moral, geração de código-fonte para desenvolvimento de software, enfim, sua imaginação é o limite!
Ambientes onde você pode rodar uma LLM:
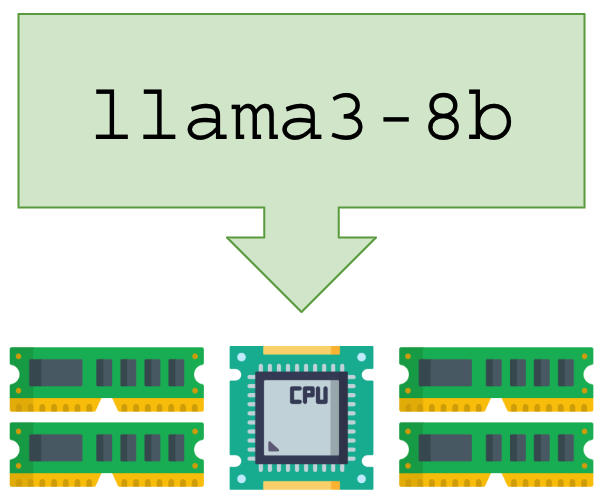 | 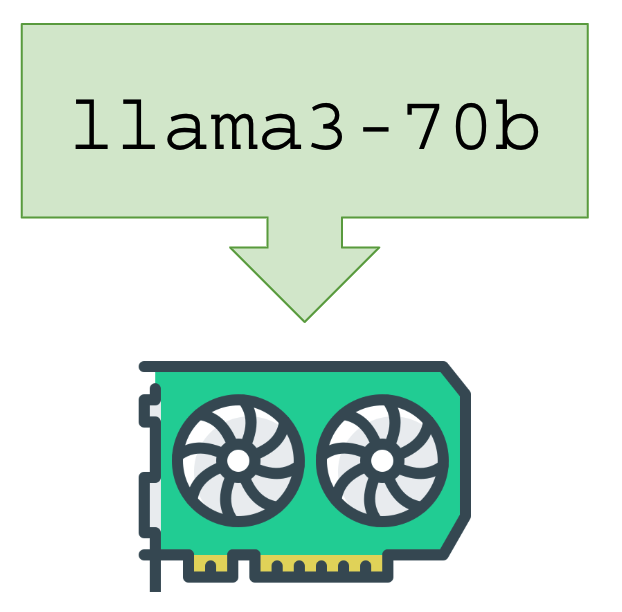 | 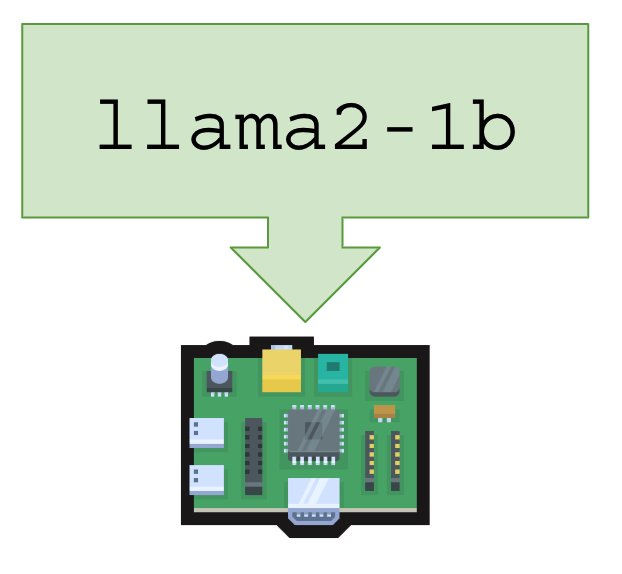 |
| CPU, qualquer notebook, PC ou servidor, incluindo VM e VPS na núvem | PCs, notebooks e servidores equipados com GPU (barramento PCI) | Raspberry PI, Banana PI, Orange PI e pequenos embarcados – CPU ARM64 |
Ambientes híbridos com múltiplas LLMs:
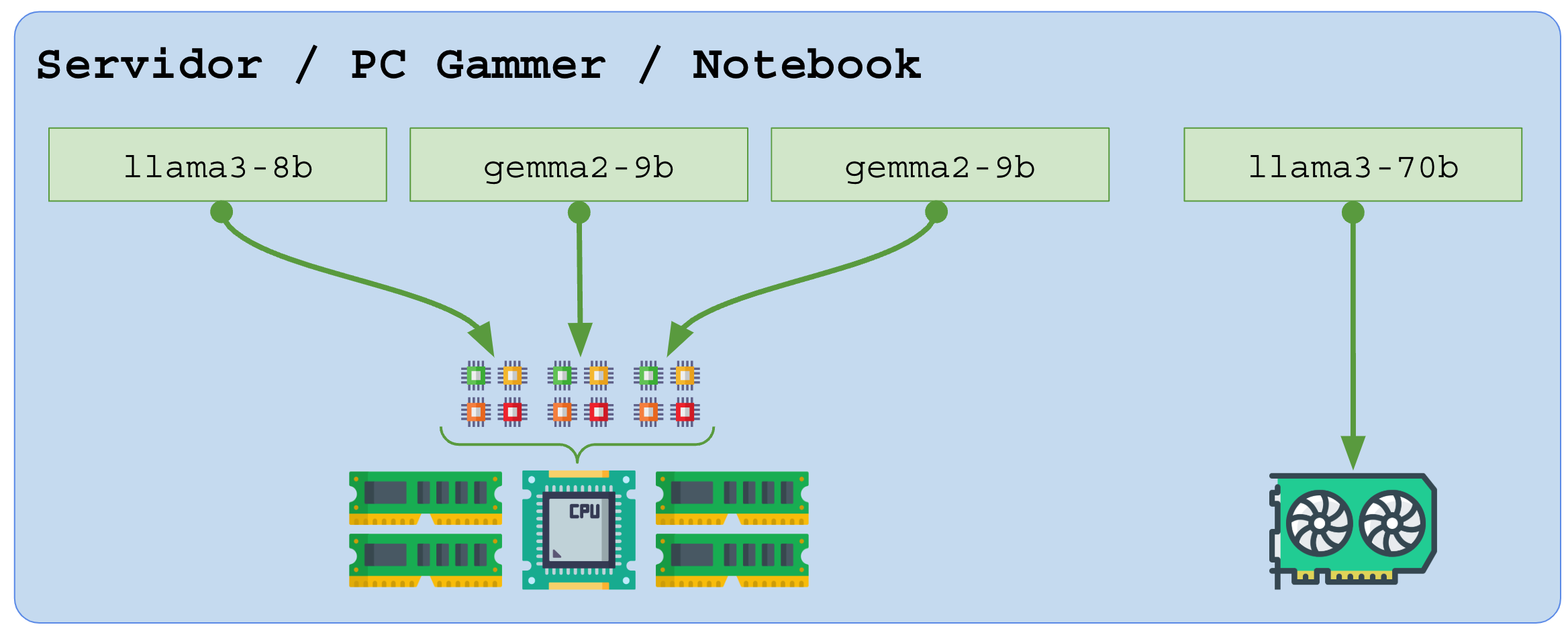
Você também pode adicionar uma LLM de baixo consumo para rodar na CPU para ajudar os sistemas locais, auxiliando em decisões, gerendo respostas, sugestões e relatórios:
Note que LLMs muito pequenas e com baixíssimo consumo podem (e são) adicionadas até mesmo em câmeras de vigilância, APPs de smartphone e brinquedos:
Em breve o uso de LLMs estará em todo lugar, você poderá perguntar ao seu cortador de grama como foi o dia, e ele vai responder “Trabalhei cedo, parei pra recarregar, choveu após o almoço, adicionei minha próxima manutenção na sua agenda, mas tudo está em ordem chefe. Posso te ajudar em algo agora?”.
Requisitos
- Ter uma CPU moderna (últimos 8 anos) com suporte a instruções AVX (Advanced Vector Extensions: AVX, AVX2, AVX512) e FMA (Fused Multiply-Add), mínimo 8 núcleos;
- Ter bastante memória RAM, memória rápida (dual/quad-channel, clock alto, DDR4 ou DDR5), recomendado acima de 32 GB;
- Opcional, porém altamente recomendável, GPU NVIDIA com pelo menos 8 GB de VRAM (RAM da placa de vídeo), recomendado acima de 20 GB;
- Ter pelo menos 120 GB de disco livre para baixar vários modelos, unidades NVME/SSD devem ser preferidas, recomendado pelo menos 2 TB;
- Internet banda-larga para download dos modelos (são grandes, de 3GB a 300GB);
Conhecimentos e procedimentos prévios
- Instalação e uso de Linux;
- Data/hora sincronizada via NTP;
- Ajuste fino no kernel Linux (geral) e ajustes de uso de RAM e memória virtual;
- Instalação e operação de containers em Docker;
Softwares utilizados nesse artigo
- Linux Debian 12;
- Docker para rodar os APPs em containers isolados;
- Container Ollama (gerenciar modelos, com CLI e API REST simples);
- Container Open-Webui (“OI”) – Interface WEB semelhante ao Chat-GPT com controle de usuários;
1 – Introdução ao uso de LLM
Vamos explorar o uso de “text to text” (txt2txt), onde enviamos um texto para um modelo de redes neurais “transformers” que fazem os as analises do texto de entrada e produz tokens (palavras e símbolos) de saída, mantendo a coerência e a coesão do texto de entrada – bons pedidos geram boas respostas.
Neste site você pode ter uma visualização desse processo:
https://poloclub.github.io/transformer-explainer/
O modelo LLaMA “llama” (Large Language Model Meta AI) é disponibilizado gratuitamente em vários tamanhos de parâmetros, normalmente entre 1b (1 bilhão) a 70b (10 bilhões) de parâmetros. Quanto mais parâmetros, maior a precisão entre as relações de palavras, contextos, pensamentos, atenção e maior o conhecimento intrínseco do modelo.
Modelos grandes consomem muita memória (RAM/VRAM) e CPU (threads, CUDA cores, TENSOR cores).
O tamanho do modelo deve ser próximo ao desafio exigido dele, por exemplo:
- Para analisar texto simples e entender o idioma (sujeito, ação, oração, concordância, coerência e coesão), modelos pequenos são eficientes, entre 1b e 8b e facilmente atingem 90% de eficiência;
- Para analisar provas de vestibular, ENEM e concursos, são exigidos modelos maiores treinados em muitos campos de conhecimento, assim 360b ou superior atingiria eficiência próxima a 95%.
Modelos avançados, comerciais, facilmente atingem 2 trilhões de parâmetros (Chat GPT).
Entendendo os parâmetros e tamanho dos modelos
Um modelo de LLM treinado resulta numa quantidade muito grande de valores (bytes), considera-se o número de tokens, dimensões, camadas de atenção, camadas de projeção, camadas de viés, camada de normalização, camada de decodificação, e por último, quando tudo está pronto, a redução da quantização dos parâmetros (compressão).
Um modelo pode ser comprimido, diminuindo o tamanho do parâmetro que relaciona todas as camadas. Uma relação de 32 bits (4 bytes) pode ser reduzida a 4 bits (meio byte), perdendo precisão mas mantendo o peso “parecido”.
Redução do peso: quando você usa PI para calcular a circunferência de uma praça, ter PI=3.14 vai gerar um resultado, usar PI=3.1415926535 vai gerar um resultado mais preciso. Se você cor circular a praça com um cano de cobre, use o valor mais preciso possível, se for com uma corda barata, use o valor mais curto e preguiçoso.
O modelo ollama-3.2-1b (https://ollama.com/library/llama3.2) quantizado em FP32 (Float Point 32 bits = 4 bytes) resultará em 1 bilhão de parâmetros multiplicado por 4 bytes, assim, precisaremos pelo pelo menos 4 GB de RAM/VRAM para carregar o modelo antes de iniciar o processamento dos tokens.
A compressão do modelo ollama-3.2-1b_FP32 para ollama-3.2-1b_INT16 reduziria esse tamanho pela metade, talvez até uma Raspberry PI poderia tentar rodá-la.
Tabela de tamanhos e tipos de compressão:
| Compressão | Parâmetro | Ponto forte | Ponto fraco |
| FP32 | 32 bits – 4 bytes | Precisão máxima | Consumo elevadíssimo |
| FP16 | 16 bits – 2 bytes | Precisão elevada | Consumo moderado |
| BF16 | 16 bits – 2 bytes | Precisão elevada | Consumo moderado |
| INT16 | 16 bits – 2 bytes | Precisão questionável | Consumo moderado |
| INT8 | 8 bits – 1 byte | Precisão baixa | Consumo optimizado |
| INT4 | 4 bits, 0.5 byte | Precisão ruim | Consumo baixíssimo |
| INT2 | 2 bits | Precisão deprimente | Consumo baixíssimo |
| 1 bit | 1 bit | Precisão inexistente | Consumo de IOT |
O consumo de RAM/VRAM e CPU é absurdo, portanto, a largura de banda entre os núcleos e a RAM é vital.
GPUs tem largura próxima a 1 terabytes/s, enquanto que CPU/RAM essa banda raramente excede 60 gigabytes/s. Ve-se a importância da GPU na performance das LLMs.
A escolha da quantização/compressão, tamanho do modelo, velocidade (tokens por segundo) e consumo de recursos vai depender muito do seu objetivo e dinheiro. As vezes é melhor pagar uma IA na nuvem que montar um servidor fraco.
Opções de modelos prontos
As empresas pioneiras no desenvolvimento e treinamento de modelos publicam os arquivos para uso gratuito nos principais sites:
- Huggin Face – https://huggingface.co/ – O maior site com modelos para downloads;
- Ollama – https://ollama.com/ – Ferramenta de gestão de modelos e API REST básica;
- Github – https://github.com – Site de repositórios cheio de imagens prontas (NVIDIA, …);
Principais empresas e seus modelos gratuitos:
| Empresa | Modelo | Site |
Meta | LLama | https://ollama.com/ |
Gemma | https://ai.google.dev/gemma | |
Microsoft | Phi | https://azure.microsoft.com/pt-br/products/phi |
LG | EXAONE | https://www.lgresearch.ai/exaone |
IBM | Granite | https://www.ibm.com/br-pt/granite |
Alibaba | Qwen | https://github.com/QwenLM/Qwen |
Mistral AI | Mistral / Mixtral | https://mistral.ai/ |
2 – Instalando os pre-requisitos
Após instalar o Debian 12 e garantir o funcionamento da Internet (DNS, IPv4 e IPv6), instale os programas na ordem.
Todos os programas abaixo devem ser executados como root (sudo su ou su –).
Atualizando o Debian
Antes de iniciar as instalações, o seu Debian deve estar 100% atualizado e rodando a última versão do Kernel Linux.
Execute os procedimentos abaixo e reinicie se alguma atualização foi aplicada. Após reiniciar, rode novamente, e repita o processo de atualizar e reiniciar até que não haja mais nenhum pacotes para ser instalado.
# Atualizando Debian para últimas versões
apt-get -y update
apt-get -y upgrade
apt-get -y dist-upgrade
apt-get -y autoremove
# Reinicie com o comando: reboot
# Repita os comandos de atualização e reinicie até que não haja
# mais updates para apliar.
# Depois de tudo, reinicie uma última vez!
Instalando Docker
# Instalar curl e wget para baixar o script:
apt-get -y install curl
apt-get -y install wget
# Baixar script instalador oficial:
curl -fsSL get.docker.com -o /tmp/get-docker-com.sh
# Alternativas usando wget:
# wget get.docker.com -O /tmp/get-docker-com.sh
# Alternativa usando busybox wget:
# busybox wget get.docker.com -O /tmp/get-docker-com.sh
# Executar script instalador:
sh /tmp/get-docker-com.sh
Comandos auxiliares e ferramentas
Vamos precisar de algumas ferramentas, instale:
# Instale todas as ferramentas:
apt-get -y install software-properties-common
apt-get -y install apt-transport-https
apt-get -y install ca-certificates
apt-get -y install dirmngr
apt-get -y install dkms
# Ferramentas opcionais mas recomendadas:
apt-get -y install bridge-utils
apt-get -y install iproute2
apt-get -y install tcpdump
apt-get -y install strace
apt-get -y install htop
apt-get -y install mtr
apt-get -y install mc
3 – Tuning
Suporte a IO-MMU
Nota: todas as dicas e configurações abaixo são OPCIONAIS. Pule essa parte se não te interessar mexer nisso.
IO-MMU (Input-Output Memory Management Unit) é componente de hardware presente na CPU que conecta um barramento de I/O compatível com DMA à memória do sistema. Ele mapeia endereços virtuais visíveis ao dispositivo para endereços físicos, permitindo que dispositivos PCI Express (GPUs e NICs) possam ir direto na RAM (passa dentro da CPU mas não passa pelos núcleos, assim não interrompe o SO). Ele é uma especie de BYPASS de alta velocidade (necessário para RDMA e operações de alta velocidade).
- Em processadores Intel: Intel VT-d
- Em processadores AMD: AMD-Vi
Se você está rodando uma máquina virtual que fará uso dedicado de GPU ou NIC (placa de rede), infelizmente nem sempre o IO-MMU e o PCI Passthrough são compatíveis na mesma VM. Você deve preferir um hardware dedicado em vez de uma VM se quiser performance máxima com uso de GPU.
O melhor ambiente para IA é um Linux instalado direto na CPU (BAREMETAL) e segregando o uso por containers.
Conferindo presença de IO-MMU:
# Exemplo 1 (AMD, VM no vmware)
# - Observe que nao há IO-MMU ativo:
# - Esse é um comando extraido de uma VM rodando no VMWARE onde o IO-MMU
# não foi ativado nas propriedades da VM pois há um bypass de PCI junto
dmesg | grep -i iommu
[ 0.546174] iommu: Default domain type: Translated
[ 0.546174] iommu: DMA domain TLB invalidation policy: lazy mode
[ 0.773435] AMD-Vi: AMD IOMMUv2 functionality not available on
this system - This is not a bug.
# Exemplo 2 (INTEL - i9 host - baremetal)
# - Observe que foi detectado 'iommu'
# - Por ser Intel, ignore o alerta do AMD-Vi
# - Observe os enderecos PCI dos equipamentos que tem acesso
# ao IOMMU
dmesg | grep -i iommu
[ 0.034703] DMAR-IR: IOAPIC id 2 under DRHD base 0xfed91000 IOMMU 1
[ 0.261267] pci 0000:00:02.0: DMAR: Skip IOMMU disabling for graphics
[ 0.276853] iommu: Default domain type: Translated
[ 0.276853] iommu: DMA domain TLB invalidation policy: lazy mode
[ 0.306247] DMAR: IOMMU feature fl1gp_support inconsistent
[ 0.306249] DMAR: IOMMU feature dev_iotlb_support inconsistent
[ 0.306653] pci 0000:00:02.0: Adding to iommu group 0
[ 0.306666] pci 0000:00:00.0: Adding to iommu group 1
[ 0.474833] AMD-Vi: AMD IOMMUv2 functionality not available on
this system - This is not a bug.
Para fazer bom uso do IO-MMU, ative-o no boot do Kernel Linux (explicado na parte de tuning do Kernel Linux).
Ajustes de tuning do Kernel Linux
Nota: todas as dicas e configurações abaixo são OPCIONAIS. Pule essa parte se não te interessar mexer nisso.
Devido a alta carga de uso de CPU e RAM, o Kernel Linux deve ser ajustado para esses volumes.
Leia esse artigo para preparar o ambiente para um tuning eficiente:
https://blog.patrickbrandao.com/ajuste-fino-e-tuning-no-kernel-linux/
Ajustes adicionais no BOOT – edite o arquivo /etc/default/grub e preencha a variável GRUB_CMDLINE_LINUX conforme abaixo:
# Ativar HUGEPAGES (HP):
# - Escolha o tamanho da paginacao em HP, exemplos
# 1G a 2MB = default_hugepagesz=2M hugepagesz=2M hugepages=512
# 2G a 2MB = default_hugepagesz=2M hugepagesz=2M hugepages=1024
# 4G a 2MB = default_hugepagesz=2M hugepagesz=2M hugepages=2048
# 8G a 2MB = default_hugepagesz=2M hugepagesz=2M hugepages=4096
# 16G a 2MB = default_hugepagesz=2M hugepagesz=2M hugepages=8192
# 32G a 2MB = default_hugepagesz=2M hugepagesz=2M hugepages=16384
# Ativar io-mmu - se for necessario ativar:
# Em processador Intel: iommu=pt intel_iommu=on
# Em processador AMD..: amd_iommu=on iommu=pt
# Junte as opcoes acima,
# no meu caso eu uso um INTEL com 32G de RAM, então
# vou usar 16G em hugepages.
GRUB_CMDLINE_LINUX="iommu=pt intel_iommu=on default_hugepagesz=2M hugepagesz=2M hugepages=8192"
Após alterar o GRUB, execute:
grub-mkconfig -o /boot/grub/grub.cfg
Reinicie o Linux para que as novas configurações acima entrem em operação antes de continuar.
Ajustes adicionais no SYSCTL:
# Swap apenas quando não houver mais memória RAM
sysctl -w vm.swappiness=0
echo 'vm.swappiness=0' > /etc/sysctl.d/073-swappiness.conf
# Memória compartilhada - usar 50% da RAM total
# - Maximo em bytes de memoria compartilhada, default: até o fim da RAM
# Para o ambiente com 32 G de ram, alocar 16 G
# 16 giga = 16 X (1024 x 1024 x 1024) = 17179869184
sysctl -w kernel.shmmax=17179869184 # 16 GB (ajuste para metade da RAM disponível)
# - Numero de paginas, deve ser o valor acima dividido por 4096
# 17179869184 / 4096 = 4194304
sysctl -w kernel.shmall=4194304 # 4M páginas (para 16 GB com páginas de 4 KB)
# - Colocar config acima para iniciar durante o boot
(
echo 'kernel.shmmax=17179869184'
echo 'kernel.shmall=4194304'
) > /etc/sysctl.d/087-kernel-shared-memory.conf
# Ativar hugePages
# - Paginas de 2M
# - Escolha a quantidade de RAM que pode
# ser alocada em paginas de 2M em vez de paginas de 4k
# Ex.: para 16G = 8192 paginas (17179869184 / 2097152)
# para 32G = 16384 paginas (34359738368 / 2097152)
(
echo 'vm.nr_hugepages=8192'
) > /etc/sysctl.d/088-hugepages.conf
#echo always > /sys/kernel/mm/transparent_hugepage/enabled
# Ativar transparent HP
# - Esse comando ativa no momento (depois que vc ja reiniciou ativando HP)
# - Use o 'systemd-tmpfiles' para tornar a config abaixo ativa durante o boot
echo always > /sys/kernel/mm/transparent_hugepage/enabled
# Numero de mapeamento de memória (mmap), default: 65530
# - Aumentar em 4x
sysctl -w vm.max_map_count=262144
echo 'vm.max_map_count=262144' > /etc/sysctl.d/089-max-map-count.conf
Recomendo reiniciar o Linux após realizar o tuning de SYSCTL.
Ajustes de barramento PCI
Nota: todas as dicas e configurações abaixo são OPCIONAIS. Pule essa parte se não te interessar mexer nisso.
O barramento PCI liga as placas GPU, NIC (placa de rede) e demais periféricos até a CPU.
Esse barramento pode ser configurado para algumas melhorias de performance, 2 principais estão disponíveis: modo performance (recurso depende da BIOS, pode não ser possível alterar pelo Linux), aumento de MPS (MTU de PCI, tambem depende da BIOS).
# Conferindo modo atual de gestão de energia do barramento PCI:
cat /sys/module/pcie_aspm/parameters/policy
# Alterando modo de operação da PCI Express (via controle da BIOS):
# - Colocando em modo economia de energia (default)
# - Erro ao executar o comando pode significar que a BIOS não aceita alterar
echo powersave > /sys/module/pcie_aspm/parameters/policy
# - Colocando em modo performance
# - Erro ao executar o comando pode significar que a BIOS não aceita alterar
echo performance > /sys/module/pcie_aspm/parameters/policy
# Verificar tamanho de segmento transmitido pela PCI (tamanho do pacote)
# - Observe que o tamanho 'MaxPayload' está definido em 256 bytes
lspci -vv | grep -P '^\d|Payload'
01:00.0 VGA compatible controller: NVIDIA Corporation GA106
[GeForce RTX 3060 Lite Hash Rate] (rev a1) (prog-if 00 [VGA controller])
DevCap: MaxPayload 256 bytes, PhantFunc 0, Latency L0s unlimited, L1 <64us
MaxPayload 256 bytes, MaxReadReq 512 bytes
07:00.0 Ethernet controller: Intel Corporation Ethernet Controller X710
DevCap: MaxPayload 2048 bytes, PhantFunc 0, Latency L0s <512ns, L1 <64us
MaxPayload 256 bytes, MaxReadReq 512 bytes
# Procure na BIOS e caminhos como
# - "PCIe Settings" ou "Advanced PCIe Configuration."
# - "MPS" ou "Maximum Payload Size"
# - Coloque nos valores máximos
# - Estude as placas PCI usadas e procure no manual as configurações
# que podem ser alteradas pelo comando 'setpci'
4 – Usando GPU NVIDIA
Se você for rodar o ollama em ambiente puramente CPU, ignore esse capítulo.
Instalando drivers NVIDIA
Os passos abaixo devem ser executados para ambientes com ollama no HOST ou ollama no Docker pois ambos os casos requerem o acesso a GPU para execução remota (remota aqui significa fora da CPU).
Adicionando o repositório da NVIDIA:
# Instalar drivers NVIDIA
# - Obter chave de assinatura do repositorio NVIDIA
curl -fsSL \
https://nvidia.github.io/libnvidia-container/gpgkey | \
gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
# - Obter lista de repositorio:
curl -s -L -o /tmp/nct.list \
"https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list"
# - Alterar lista de repositorio baixada acima para para usar a chave:
cat /tmp/nct.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# - Ativar repositorio experimental:
sed -i -e \
'/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
# - Conferir:
cat /etc/apt/sources.list.d/nvidia-container-toolkit.list
# - Adicionar repositorios 'non-free' e 'non-free-firmeware'
# para baixar pacotes adicionais necessarios:
add-apt-repository -y contrib non-free non-free-firmware
# - Atualizar indice de repositorios:
apt-get -y update
# - Atualizar binarios com base nos novos repositorios:
apt-get -y upgrade
apt-get -y dist-upgrade
# Caso haja updates aplicados, reinicie o Debian e repita os procedimentos
# de update, sempre reiniciando o Linux em caso de updates aplicados.
# Instalar fontes do kernel para compilar driver (feito pelo instalador nvidia)
apt-get -y install linux-headers-$(uname -r);
Uma vez que todos os repositórios e updates estão sincronizados, vamos instalar os pacotes de drivers e bibliotecas da NVIDIA:
# Instalar drivers NVIDIA
# - Firmwares NVIDIA
apt-get -y install firmware-nvidia-gsp
apt-get -y install firmware-nvidia-tesla-gsp
apt-get -y install libnvidia-container-tools
apt-get -y install libnvidia-container1
apt-get -y install nvidia-container-toolkit
apt-get -y install nvidia-container-toolkit-base
apt-get -y install nvidia-container-runtime
apt-get -y install libnvidia-ml1
apt-get -y install nvidia-driver-bin
apt-get -y install nvidia-driver-libs
apt-get -y install nvidia-egl-common
apt-get -y install nvidia-egl-icd
apt-get -y install nvidia-kernel-common
apt-get -y install nvidia-kernel-dkms
apt-get -y install nvidia-kernel-support
apt-get -y install nvidia-modprobe
apt-get -y install nvidia-persistenced
apt-get -y install nvidia-settings
apt-get -y install nvidia-smi
apt-get -y install nvidia-support
apt-get -y install nvidia-suspend-common
apt-get -y install nvidia-vdpau-driver
apt-get -y install nvidia-vulkan-common
apt-get -y install nvidia-vulkan-icd
# - Instalar ferramenta de deteccao de hardware NVIDIA:
# obs.: esse pacote ja puxa todos os pacotes acima
# ao ser instalado
apt-get -y install nvidia-driver
apt-get -y install nvidia-detect
# - Instalar comando par Acompanhar uso de GPU:
apt-get -y install nvtop
# Procedimentos finais, garantir updates
# Obs.: mesma rotina atualiza-reboot
apt-get -y update
apt-get -y upgrade
apt-get -y dist-upgrade
# Reiniciar para que os drivers e o kernel rodem
# sincornizados durante o boot:
reboot
Conferindo deteção da placa de vídeo NVIDIA:
# Conferindo a presenca da GPU NVIDIA:
nvidia-detect
# Exibindo dados de uso, temperatura, etc...:
nvidia-smi
# Extrato de status completo:
nvidia-smi -q
# Extrato de status de performance:
nvidia-smi -q -d PERFORMANCE
# Extrair porcentagem de uso de GPU e VRAM (integre com seu monitoramento)
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv
# Listar frequencias:
nvidia-smi -q -d CLOCK
# Ajustes finos de GPU NVIDIA (tome cuidado):
# - Ajustar FAN (ventuinhas)
# nvidia-smi -pm 1
# nvidia-smi -fan 80 # coloca em 80%
# nvidia-smi -fan 100 # coloca em 100%
# - OverClock
# nvidia-smi -lgc 1200,1800 # clock minimo-maximo de GPU
# nvidia-smi -lmc 1200,1800 # clock minimo-maximo de VRAM
# - Controle de energia
# nvidia-smi -pm 1
# nvidia-smi -pl 200 # Limitar a 200 watts
# NVTOP - Monitorar uso da placa
# - Abra um segundo terminal e execute:
nvtop
# Outra forma de monitorar em tempo real
# - Abra um terceiro terminal e execute
watch -n 0.5 nvidia-smi
watch -n 0.5 nvidia-smi -q -d PERFORMANCE
# - Agregado:
watch -n 0.5 bash -c 'nvidia-smi; nvidia-smi -q -d PERFORMANCE'
Integrar uso de GPU com o Docker:
# Passo final: ativar nvidia-docker:
nvidia-ctk runtime configure --runtime=docker
# Conferir arquivo de driver gpu no docker.json
cat /etc/docker/daemon.json
{
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
}
# Obs.: caso o arquivo /etc/docker/daemon.json não possua
# a entrada "runtimes" voce deverá adicioná-la
# Reiniciar docker para subir com a nova config com o "runtimes" + "nvidia":
systemctl restart docker
5 – Preparando storage dos modelos
Antes de começar, precisamos pontuar alguns detalhes.
O “ollama” não é um modelo de IA, ele é um APP de gestão de modelos e API entre o usuário (você ou algum bot) e a execução do modelo em si.
O modelo de IA LLM deve ser obtido (download) e armazenado localmente.
Como podemos ter ambientes híbridos (somente CPU, CPU e GPU, somente GPU), todos os containers devem armazenar e consultar as imagens no mesmo diretório para evitar a duplicação dos arquivos dos modelos.
Baixa um modelo pode ser algo demorado, muito demorado, se sua Internet for lenta ou seu provedor não for bem conectado aos datacenters dos CDNs (github, PNI das bigtechs).
Vamos armazenar todos os arquivos no mesmo diretório para facilitar a recuperação de backup e evitar a duplicação:
- Diretório base: /storage/ia-models
Cada instalação do ollama, seja instalado no HOST ou instalado em containers, busca as imagens em um desses diretórios abaixo:
- /usr/share/ollama/.ollama/models: diretório padrão da instalação no HOST;
- /root/.ollama/models: diretório padrão dentro do container;
- /var/lib/docker/volumes/ollama/_data/models: diretório padrão no HOST onde o volume do container costuma ser mapeado;
Para evitar as duplicações, vamos conduzir todos esses caminhos para o diretório base oficial em /storage/ia-models
# Diretório principal de armazenamento dos modelos de IA LLM:
mkdir -p /storage/ia-models
# Caso você ja tenha alguma imagem nos caminhos originais, copie-os para
# a base central:
cp -rav /usr/share/ollama/.ollama/models/* /storage/ia-models/
cp -rav /root/.ollama/models/* /storage/ia-models/
cp -rav /var/lib/docker/volumes/ollama/_data/models/* /storage/ia-models/
# Remova todos os diretorios alternativos:
# Obs.: se você ja tem esses caminhos em uso, faça backup primeiro.
# mas se for a primeira vez, rode sem medo.
rm -rf /usr/share/ollama/.ollama/models 2>/dev/null
rm -rf /root/.ollama/models 2>/dev/null
rm -rf /var/lib/docker/volumes/ollama/_data/models 2>/dev/null
# Criar os diretorios vazios:
mkdir -p /usr/share/ollama/.ollama
mkdir -p /root/.ollama
mkdir -p /var/lib/docker/volumes/ollama/_data
# Apontar diretorios para o diretorio central usando link simbólico:
ln -sf /storage/ia-models /usr/share/ollama/.ollama/models
ln -sf /storage/ia-models /root/.ollama/models
ln -sf /storage/ia-models /var/lib/docker/volumes/ollama/_data/models
# Conferindo (todos os comandos abaixo devem retornar: /storage/ia-models)
readlink -f /usr/share/ollama/.ollama/models
readlink -f /root/.ollama/models
readlink -f /var/lib/docker/volumes/ollama/_data/models
Lembre-se de fazer backup da pasta /storage em uma unidade externa ou em um servidor de backups.
6 – Rodando o ollama
O ollama tem como único objetivo:
- Obter as imagens remotamente para você;
- Gerenciar suas imagens e personalizações pontuais;
- Prover uma API REST para interação com a base de dados e com os modelos;
Nada mais, nada menos. Ele não tem interface web bonitinha nem controle de acesso por login e senha, painel etc… isso será abordado no capítulo seguinte (Open-WebUI).
Por conta de sua simplicidade e ausência de autenticação, a porta da API do ollama deve ser protegida, seja por firewall ou abrindo-a apenas para os containers vizinhos.
Iremos abrir a porta do ollama apenas para demonstrar os exemplos desse capítulo. Nos capítulos seguintes não publicaremos mais as portas e deixaremos o controle WEB no Open-WebUI.
A porta TCP da API REST do ollama é 11434
Devido a natureza híbrida das execuções (CPU, GPU ou ambos), vamos testar da seguinte forma:
- Porta externa 11434 apontará para a porta 11434 interna do ollama-cpu
- Porta externa 11435 apontará para a porta 11434 interna do ollama-gpu
Os containers terão sua própria rede no docker chamada “br-ias”.
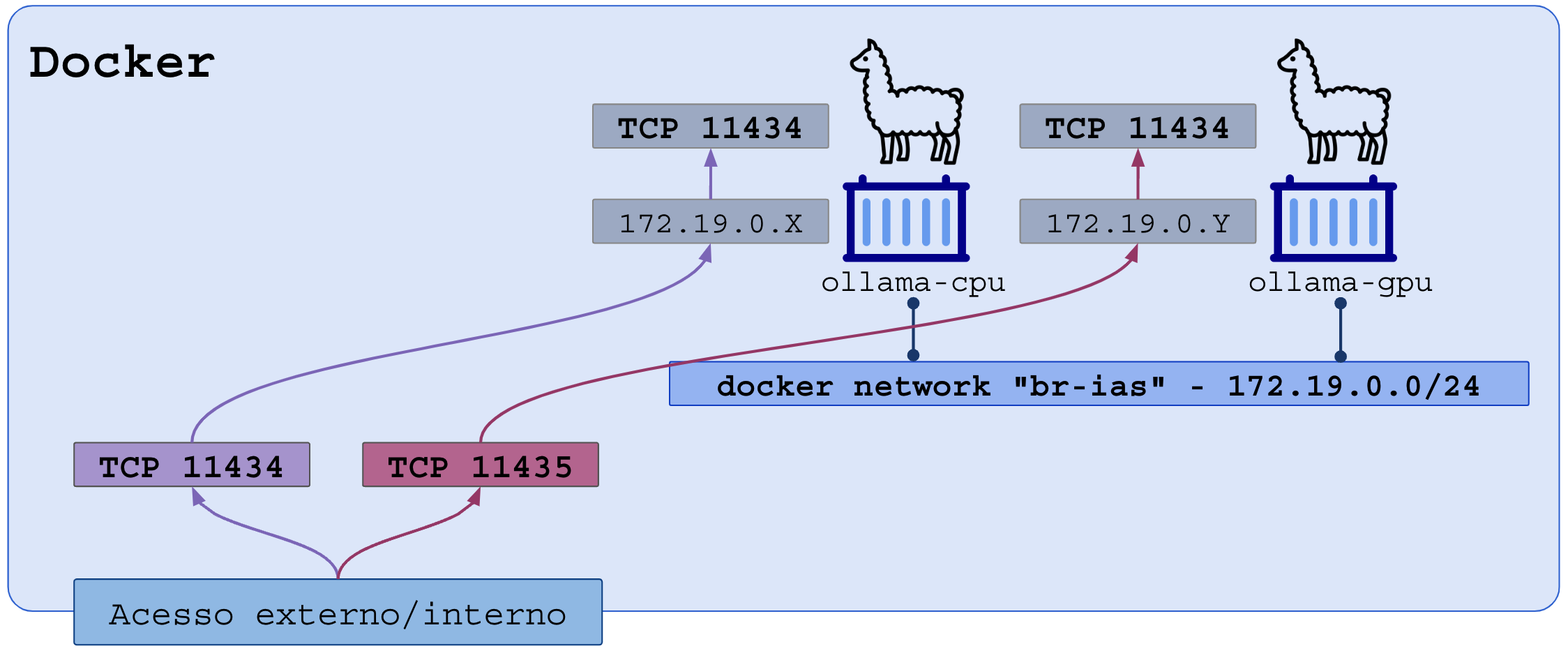
Criando a rede docker:
# Criar rede docker (ipv4 only)
# - atributo 'com.docker.network.bridge.name' define o nome
# da interface bridge no HOST
# - atributo 'com.docker.network.bridge.enable_icc' permite
# que constainers falem entre si, 'Inter Container Connectivity'
# - usaremos apenas ipv4, faixa 172.19.0.x
# - o HOST assume o primeiro ip dessa rede para ser o gateway
# dos containers: 172.19.0.1
docker network create \
-d bridge \
--subnet 172.19.0.0/24 \
-o "com.docker.network.bridge.name"="br-ias" \
-o "com.docker.network.bridge.enable_icc"="true" \
br-ias
Criando o container para rodar LLM na CPU (porta externa 11434):
# Criar container ollama para execuções na CPU
# - argumento 'name' especifica o nome do container para acesso
# dos demais containers na mesma network
# - argumento '-h' especifica o hostname interno do container
# - argumento '-network' especifica a rede
# - argumento '--restart=unless-stopped' informa que o container deve
# rodar novamente em caso de pane, e que so deve parar se
# for explicitamente ordenado
# - argumento '-p' mapeia a porta externa 11434 na porta interna 11434
# - argumento '-v' mapeia a pasta do HOST dentro da pasta do container
# - argumento final 'ollama/ollama' especifica a imagem do container
# a ser usada
docker run -d \
--name ollama-cpu \
-h ollama-cpu.intranet.br \
--network br-ias \
--restart unless-stopped \
\
-p 11434:11434 \
\
-v /storage/ia-models:/root/.ollama/models \
\
ollama/ollama
Criando o container para rodar LLM na GPU NVIDIA (note a porta externa 11435):
# Criar container ollama para execuções na CPU
# - argumento 'name' especifica o nome do container para acesso
# dos demais containers na mesma network
# - argumento '-h' especifica o hostname interno do container
# - argumento '-network' especifica a rede
# - argumento '--restart=unless-stopped' informa que o container deve
# rodar novamente em caso de pane, e que so deve parar se
# for explicitamente ordenado
# - argumento '--gpus=all' disponibiliza as GPUs NVIDIA dentro do container
# - argumento '-p' mapeia a porta externa 11435 na porta interna 11434
# - argumento '-v' mapeia a pasta do HOST dentro da pasta do container
# - argumento final 'ollama/ollama' especifica a imagem do container
# a ser usada
docker run -d \
--name ollama-gpu \
-h ollama-gpu.intranet.br \
--network br-ias \
--restart unless-stopped \
\
--gpus=all \
\
-p 11435:11434 \
\
-v /storage/ia-models:/root/.ollama/models \
\
ollama/ollama
# Caso a etapa de instalação dos drivers e bibliotecas NVIDIA tenham
# sido ignorados ou incompletos, o docker não reconhecerá o argumento
# '--gpus=all'
# - Verificar se o container ollama-gpu esta com acesso funcional
# a placa NVIDIA
docker exec -it ollama-gpu nvidia-smi
# Em caso de erro o retorno é:
# Failed to initialize NVML: Unknown Error
# Em caso de sucesso, mostrará todas as informações das placas
Conferir execução dos containers:
# Conferir containers:
docker ps -a
# Extrair detalhes dos containers:
# - Ollama em CPU:
docker inspect ollama-cpu
# - Ollama em GPU NVIDIA:
docker inspect ollama-gpu
API do ollama
A API HTTP REST do ollama é bem simples. Vou dar exemplos para você praticar e analisar, mas lembre-se que essa API só deve ser usada por aplicativos pontuais que rodam no mesmo HOST ou containers.
Temos vários métodos para testar o acesso à API do ollama:
- Executando CURL no HOST para acesar o ip do container na porta interna;
- Executando CURL em um container na mesma “docker network” dos containers ollama, nesse caso você poderá usar:
- “http://ollama-cpu/” (-name) ou “ollama-cpu.intranet.br” (-h)
- “http://ollama-gpu/” (-name) ou “ollama-gpu.intranet.br” (-h)
- Executar CURL em outro equipamento que tenha acesso ao IP (eth0) do HOST;
# Criar um container na mesma network:
docker run \
-d --name tester \
-h tester \
--network br-ias \
debian:bookworm sleep 999999999
# - Instalando CURL no container de teste
docker exec -it tester bash -c 'apt-get -y update; apt-get -y install curl;'
# Executar de dentro de um container vizinho (tester, criado acima)
# Obs.: o "echo" no final é para quebrar a linha no final do JSON de retorno
# 1 - de dentro do 'tester' acessando ollama-cpu:
docker exec -it tester curl http://ollama-cpu:11434/api/version; echo
# Resposta: {"version":"0.5.4-0-g2ddc32d-dirty"}
# 2 - de dentro do 'tester' acessando ollama-gpu:
docker exec -it tester curl http://ollama-gpu:11434/api/version; echo
# Resposta: {"version":"0.5.4-0-g2ddc32d-dirty"}
# Executando no HOST:
# 1 - descobrir o ip interno do container
docker inspect -f \
'{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' \
ollama-cpu
# Resposta (exemplo): 172.19.0.4
# 2 - disparar curl no IP do container retornado acima (exemplo):
curl http://172.19.0.2:11434/api/version; echo
# Resposta: {"version":"0.5.4-0-g2ddc32d-dirty"}
# De qualquer servidor/client que tenha acesso ao IP do HOST (exemplo):
curl http://ip-do-host-aqui:11434/api/version; echo
Baixando modelos
Você pode baixar um modelo pelo comando dentro do container ou pela API.
# Baixando modelo dentro do container:
# - Baixando o modelo: all-minilm
docker exec -it ollama-cpu ollama pull all-minilm
# Retorno (em tempo real)
#pulling manifest ⠸
#pulling 797b70c4edf8... 17% ███ ▏ 7.7 MB/ 45 MB 2.4 MB/s 15s
#pulling 797b70c4edf8... 44% ███████ ▏ 20 MB/ 45 MB 2.7 MB/s 9s
#pulling 797b70c4edf8... 84% ████████████████ ▏ 38 MB/ 45 MB 2.8 MB/s 2s
#pulling c71d239df917...100% ████████████████████ 11 KB
# Baixando modelo pela API apartir de um container vizinho na mesma rede:
docker exec -it tester \
curl \
http://ollama-cpu:11434/api/pull \
-d '{ "model": "all-minilm", "stream": true }'; echo
# Obtendo um shell dentro do container e baixando varios modelos pequenos:
docker exec -it ollama-cpu bash
# prompt: root@ollama-cpu:/# _
ollama pull all-minilm # 45 MB
ollama pull llama3.2:1b # 1.3 GB
Executando um modelo
Executando um modelo:
- O ollama carregará o modelo no hardware presente (CPU ou GPU), no caso de CPU, ele detectará qual tecnologia de aceleração de vetores sua CPU suporta (AVX, AVX2, AVX512);
- O ollama receberá via shell ou API os tokens e enviará ao modelo;
- O modelo produzirá os tokens a medida que vai processando a entrada.
O processamento de tokens é um passo a passo controlado pelo modelo e produz pedaço a pedaço os resultados.
Como você deseja coletar o resultado?
- Modo stream desativado – “stream”: false – o ollama coletará todos os tokens produzidos mas só te enviará o resultado quando ele estiver completo;
- Modo stream ativado – “stream”: false – o ollama te enviará pedaço a pedaço em tempo real e você verá a digitação em tempo real;
Usaremos o modelo “llama3.2:1b“, ele é relativamente pequeno e produz boas respostas em português.
Exemplos:
# Rodando um modelo via shell: use /bye para sair
docker exec -it ollama-cpu ollama run llama3.2:1b
# Rodando um modelo via API:
docker exec -it ollama-cpu \
curl \
http://127.0.0.1:11434/api/generate \
-d '{ "model": "llama3.2:1b", "stream": true: prompt: "Diga o nome de 5 flores." }'; echo
# Respostas (JSON):
{
"model":"llama3.2:1b",
"created_at":"2025-01-20T05:35:50.252646101Z",
"response":"Aqui estão cinco nomes de flores:\n\n
1. Rose\n
2. Laranja\n
3. Lotus\n
4. Girassol\n
5. Orquídea",
"done":true,
"done_reason":"stop",
"context":
[
128006,9125,128007,271,38766,1303,33025,
2696,25,6790,220,2366,18,271,128009,
128006,882,128007,271,35,16960,297,
17567,409,220,20,9943,417,13,128009,
128006,78191,128007,271,32,47391,57554,
71427,9859,288,409,9943,417,1473,16,
13,16344,198,17,13,445,22026,5697,
198,18,13,61269,198,19,13,48035,
395,337,198,20,13,2582,447,2483,56188
],
"total_duration":785695152,
"load_duration":21961900,
"prompt_eval_count":35,
"prompt_eval_duration":22000000,
"eval_count":37,
"eval_duration":740000000
}
# Obtendo um shell dentro do container e rodando modelo:
docker exec -it ollama-cpu bash
# prompt: root@ollama-cpu:/# _
ollama run llama3.2:1b
# Pedido:
>>> Hoje é aniversário de 3 anos do meu cavalo Pé de Pano.
Crie 1 frase curta para elogiá-lo.
# Respostas:
"Um pé de pura magia, um coração de ouro:
o Pé de Pano é uma verdadeira divindade em minha vida!"
# Para sair
>>> /bye
Outras APIs:
# Vamos encurtar os comandos entrando dentro do container para
# rodar apenas o comando CURL:
docker exec -it ollama-cpu bash
# Instalar CURL dentro do container do ollama
apt-get -y update; apt-get -y install curl;
# APIs e exemplos de uso:
#> GET /api/version - Obter versao do software ollama
# Exemplo:
curl http://localhost:11434/api/version; echo
#> GET /api/tags - Listar nome dos modelos instalados localmente
# Exemplo:
curl http://localhost:11434/api/tags; echo
#> POST /api/show - Obter informacoes detalhadas de um modelo
# Exemplo:
curl http://localhost:11434/api/show -d '{ "model": "llama3.2:1b" }'; echo
#> GET /api/ps - Listar modelos carregados na memoria
# Exemplo:
curl http://localhost:11434/api/ps; echo
# Resposta (vazio, nada na memoria):
{"models":[]}
#> POST /api/pull - obter um modelo (fazer download)
# Exemplo (stream=false nao mostra nada na tela, vai demorar):
curl http://localhost:11434/api/pull \
-d '{ "model": "mistral", "stream": false }'; echo
#> POST /api/generate - Envio de prompts em formato JSON
# Enviar via POST o JSON do pedido de "text completion"
# - model: nome do modelo desejado
# - prompt: texto do pedido
# - stream: true or false, padrao true
# - format: formato da resposta (json)
# Exemplo:
curl http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{ "model": "llama3.2:1b", "prompt": "Responda em idioma PT-BR. Conte uma piada que envolva flores.", "stream": false }'; echo
# Exemplo avancado com todas as opcoes:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "Why is the sky blue?",
"stream": false,
"options": {
"num_keep": 5,
"seed": 42,
"num_predict": 100,
"top_k": 20,
"top_p": 0.9,
"min_p": 0.0,
"typical_p": 0.7,
"repeat_last_n": 33,
"temperature": 0.8,
"repeat_penalty": 1.2,
"presence_penalty": 1.5,
"frequency_penalty": 1.0,
"mirostat": 1,
"mirostat_tau": 0.8,
"mirostat_eta": 0.6,
"penalize_newline": true,
"stop": ["\n", "user:"],
"numa": false,
"num_ctx": 1024,
"num_batch": 2,
"num_gpu": 1,
"main_gpu": 0,
"low_vram": false,
"vocab_only": false,
"use_mmap": true,
"use_mlock": false,
"num_thread": 8
}
}'
#> POST /api/chat
# Envia o contexto completo das conversas (ping-pong continuo) para que
# o modelo responda considerando o que ja foi conversado
# O objeto "messages" deve ter sempre a ultima entrada 'role: user' com a
# pergunta que vc deseja que seja respondida, e as entradas anteriores
# alternando entre 'role: user' e 'role: assistant'
# (assistant = resposta anterior do modelo)
# Exemplo:
curl http://localhost:11434/api/chat -d '{
"model": "llama3.2",
"messages": [
{
"role": "user",
"content": "why is the sky blue?"
},
{
"role": "assistant",
"content": "due to rayleigh scattering."
},
{
"role": "user",
"content": "how is that different than mie scattering?"
}
]
}'
# Voce recebera' a resposta, mas na proxima interacao deve envia-la
# na entrada 'role: assistant' seguida da nova pergunta tipo 'role: user'
Principais modelos para baixar
Leia os comentários e pense bem antes de baixar, ocupa muito espaço em disco e são arquivos enormes.
# Entrar no container do ollama:
docker exec -it ollama-cpu bash
# Listar modelos presentes localmente:
ollama list
# Remover um modelo - exemplo, não execute se vc precisa dele!
ollama rm all-minilm
# Baixar imagem dos modelos
#========================================================================
# Baixando modelos:
ollama pull llama2
ollama pull llama2-uncensored
ollama pull llama3 # < muito bom e rapido, funciona em portugues
ollama pull llama3:70b # < requer pelo menos 34g de ram livre, 64G ideal
ollama pull llama3:70b-text
ollama pull llama3.2
ollama pull llama3.3
ollama pull llama3.3:70b
ollama pull llama3.3
ollama pull llama3:8b
ollama pull phi3
ollama pull phi3:mini
ollama pull phi3:medium
ollama pull phi3:3.8b
ollama pull phi3:14b
ollama pull phi3:medium-128k
ollama pull phi4
ollama pull qwen
ollama pull qwen:0.5b
ollama pull qwen:1.8b
ollama pull qwen:4b
ollama pull qwen:7b
ollama pull qwen:14b
ollama pull qwen:32b
ollama pull qwen:72b
ollama pull qwen:110b
ollama pull qwen2
ollama pull qwen2:0.5b
ollama pull qwen2:1.5b
ollama pull qwen2:7b
ollama pull qwen2:72b
ollama pull qwen2.5
ollama pull qwen2.5:0.5b
ollama pull qwen2.5:1.5b
ollama pull qwen2.5:3b
ollama pull qwen2.5:7b
ollama pull qwen2.5:14b
ollama pull qwen2.5:32b
ollama pull qwen2.5:72b
ollama pull gemma2
ollama pull gemma2:2b
ollama pull gemma2:27b
ollama pull codellama:7b
ollama pull codellama:13b
ollama pull codellama:34b
ollama pull codellama:70b
ollama pull qwen2.5-coder:32b
ollama pull qwen2.5-coder:14b
ollama pull qwen2.5-coder:7b
ollama pull qwen2.5-coder:3b
ollama pull qwen2.5-coder:1.5b
ollama pull qwen2.5-coder:0.5b
ollama pull deepseek-v3:671b
ollama pull deepseek-coder
ollama pull deepseek-coder:1.3b
ollama pull deepseek-coder:33b
ollama pull deepseek-coder:6.7b
ollama pull deepseek-coder-v2
ollama pull deepseek-coder-v2:16b
ollama pull deepseek-coder-v2:236b
ollama pull deepseek-llm
ollama pull deepseek-llm:67b
ollama pull deepseek-llm:7b
ollama pull deepseek-v2
ollama pull deepseek-v2:16b
ollama pull deepseek-v2:236b
ollama pull deepseek-v2.5
ollama pull deepseek-v2.5:236b
ollama pull deepseek-v3
# Novas versoes do deepseek:
ollama pull deepseek-r1
ollama pull deepseek-r1:1.5b
ollama pull deepseek-r1:7b
ollama pull deepseek-r1:8b
ollama pull deepseek-r1:14b
ollama pull deepseek-r1:32b
ollama pull deepseek-r1:70b
ollama pull deepseek-r1:671b
7 – Open-WebUI – Interface web
Embora o ollama já permita um uso bem interessante e prático para integrar com scripts e bots, o Open-WebUI (“OI”) faz um melhor uso dessa API criando muitos recursos de gerenciamento e segurança.
Primeiro vamos encerrar os containers atuais e recriá-los sem a porta exposta para a Internet. Esse passo é recomendável, mas opcional.
Se você fizer questão das portas externas para acesso direto ao ollama, recomendo que implemente um proxy-reverso que acesse as portas do ollama mas só atendam origens específicas (IP de origem ou implementar cabeçalhos de autenticação).
# Rodando ollama sem portas abertas externamente
# 1 - parar containers atuais
docker stop ollama-cpu
docker stop ollama-gpu
# 2 - remover containers atuais
docker rm ollama-cpu
docker rm ollama-gpu
# 3 - subir igual antes, mas sem mapeamento de portas externas
# - CPU
docker run -d \
--name ollama-cpu \
-h ollama-cpu.intranet.br \
--network br-ias \
--restart unless-stopped \
\
-v /storage/ia-models:/root/.ollama/models \
\
ollama/ollama
# - GPU
docker run -d \
--name ollama-gpu \
-h ollama-gpu.intranet.br \
--network br-ias \
--restart unless-stopped \
\
--gpus=all \
\
-v /storage/ia-models:/root/.ollama/models \
\
ollama/ollama
Agora vamos criar um container do Open-WebUI para o ollama-cpu, e outro para o ollama-gpu, e você escolhe se vai usar um, outro ou ambos.
Observe que estamos colocando o OI na mesma rede (docker network) do ollama, isso permite que o nome e os IPs dos containers nessa rede sejam automaticamente mapeados pelo docker e declarado no /etc/hosts de cada contrainer. Assim em vez de apontar para o IP do ollama que é dinâmico, vc pode usar o nome do container (–name) ou o hostname (-h).
O “OI” abre internamente a porta 8080, mas vamos mapear as portas assim:
- Porta externa 3000 apontará para o “OI” CPU usando o ollama CPU;
- Porta externa 3001 apontará para o “OI” GPU usando o ollama GPU;
Observe:
# Criar diretorios para base de dados do OI
mkdir -p /storage/open-webui-cpu
mkdir -p /storage/open-webui-gpu
# Rodar OpenWeb-UI para acessar o ollama-CPU - porta externa http 3000
docker run -d \
-p 3000:8080 \
--name open-webui-cpu \
-h open-webui-cpu.intranet.br \
--restart always \
--network br-ias \
\
-e OLLAMA_BASE_URL=http://ollama-cpu:11434 \
-v /storage/open-webui-cpu:/app/backend/data \
\
ghcr.io/open-webui/open-webui:main
# Rodar OpenWeb-UI para acessar o ollama-GPU - porta externa http 3001
docker run -d \
-p 3001:8080 \
--name open-webui-gpu \
-h open-webui-gpu.intranet.br \
--restart always \
--network br-ias \
\
-e OLLAMA_BASE_URL=http://ollama-gpu:11434 \
-v /storage/open-webui-gpu:/app/backend/data \
\
ghcr.io/open-webui/open-webui:main
Primeiro acesso, cadastre seu nome, email e senha (cadastro interno, não sincroniza com nenhum site externo):
OI – Página inicial – Saudação

OI – Ativar primeiro administrador – Preencha seus dados (nome, email e senha)
OI – Tela inicial de usuário – Pronto pra criar prompts e conversar
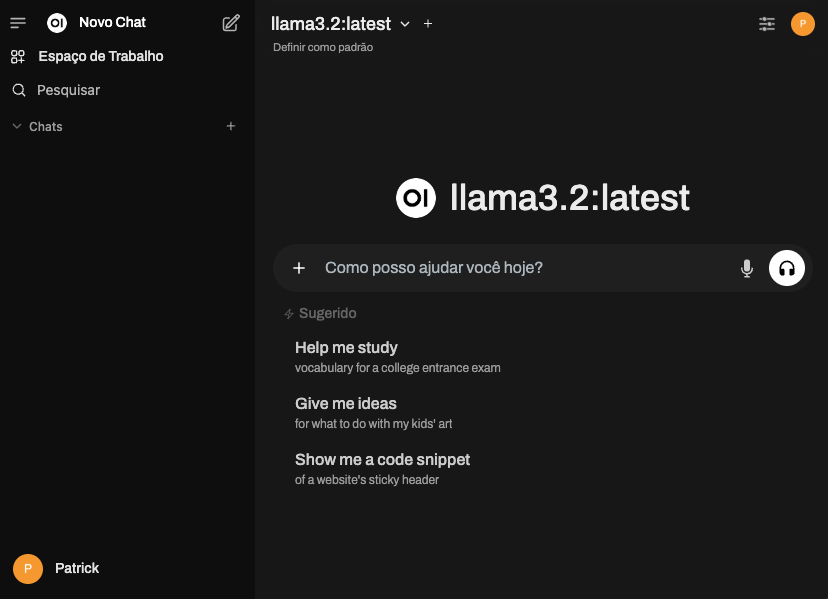
Você ja pode enviar suas perguntas e pedidos para os modelos presentes. Exemplo:
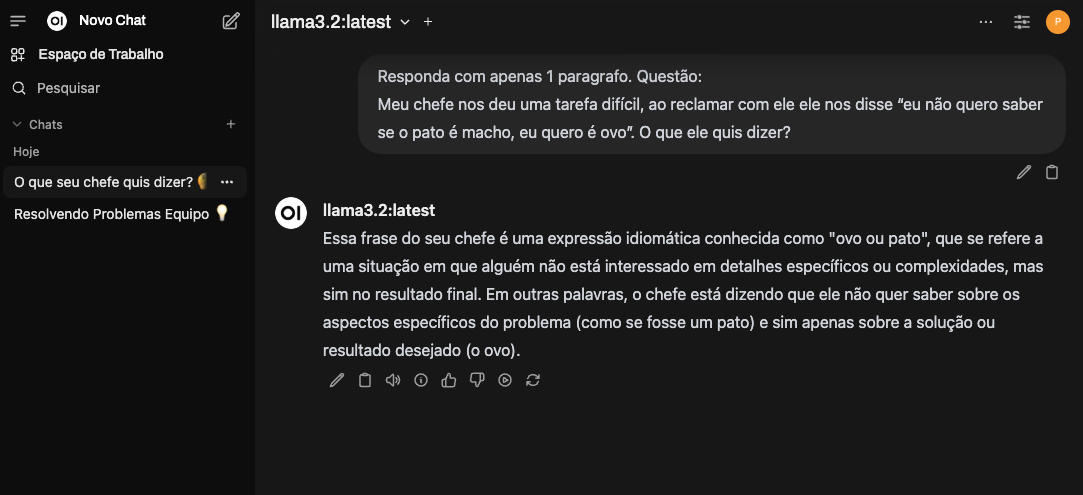
8 – Open-WebUI – Arena de modelos
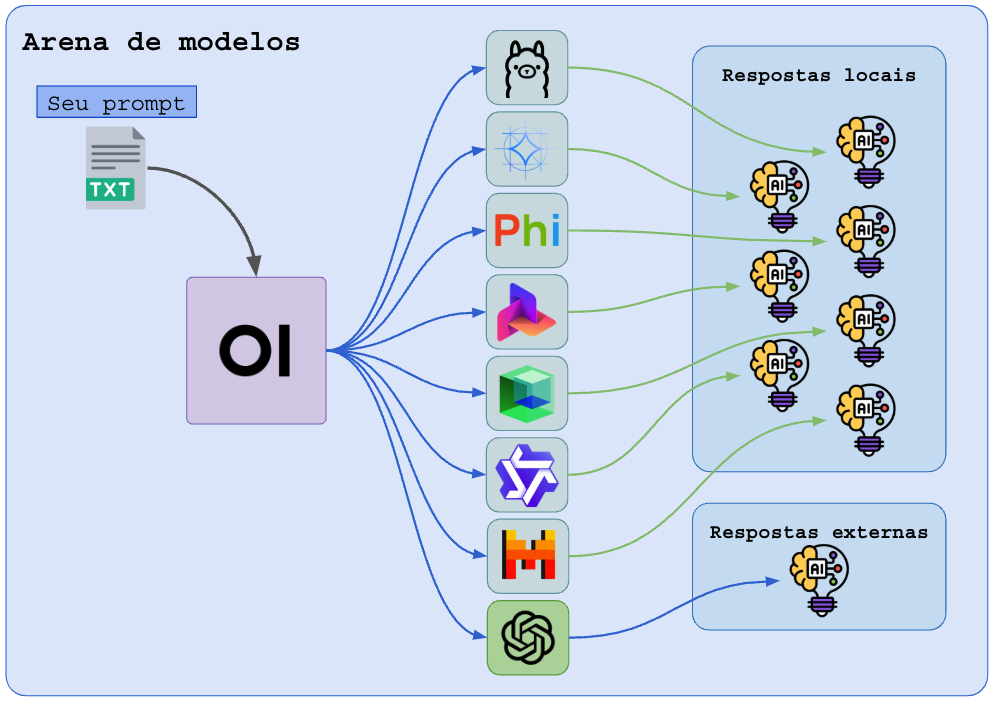
Um dos recursos interessantes para produtividade e para teste de modelos é o modo “Arena”, esse modo permite que você coloque vários modelos no mesmo chat, e confira o que cada um produz de resultado.
No canto superior direito, onde há o modelo escolhido, clique no “+” a frente do nome do modelo para adicionar outros modelos na arena.
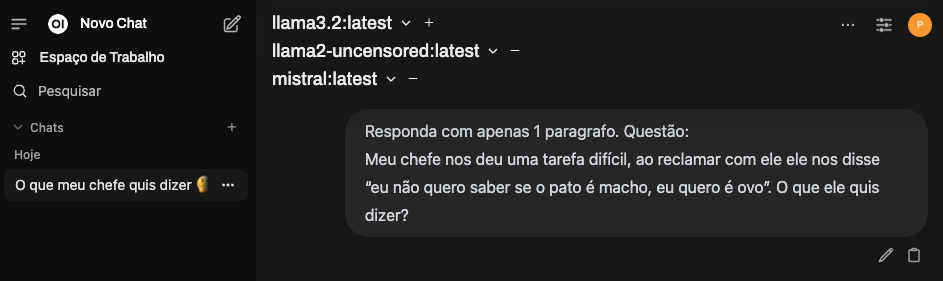
Envie o PROMPT e veja as respostas produzidas por cada modelo:
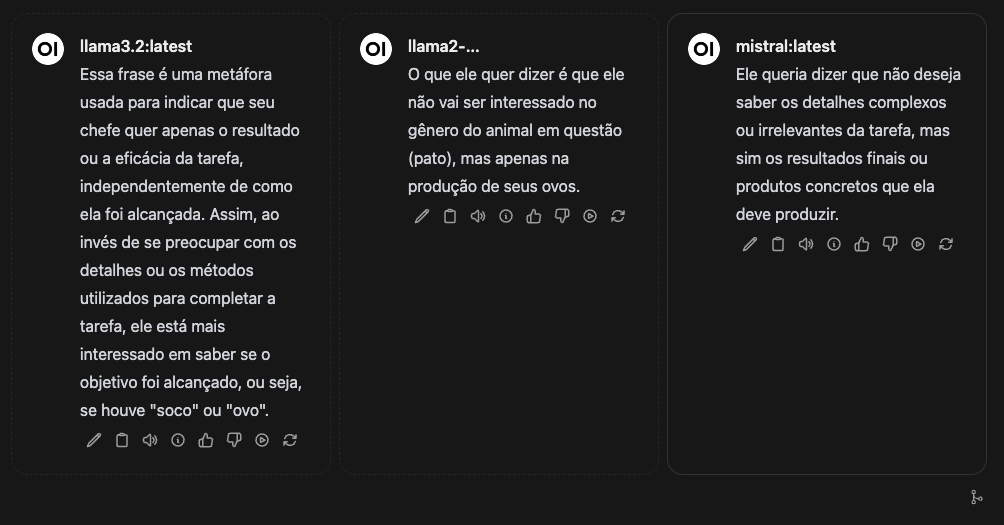
O problema do modo Arena é que os modelos vão sendo carregados, executados e dispensados um a um, e isso demanda muito tempo de carregamento.
Para paralelizar esse processamento, as técnicas são:
- Rodar vários ollama em paralelo (fiz um capítulo sobre isso), assim cada ollama terá seu modelo padrão pre-carregado e pronto pra trabalhar, isso multiplica o consumo de CPU/RAM/GPU/VRAM mas responde muito rápido na sua arena;
- Rodar vários ollama em servidores diferentes, esses acessos devem passar por um proxy-reverso balanceador (toda IA na nuvem roda assim), assim cada pergunta para um modelo será balanceada em uma instância interna diferente;
- Cadastrar as APIs de servidores remotos compartilhados, sejam comerciais ou gratuitos, como OpenAI, etc…
O uso do OI como cliente de modelos remotos pre-carregados permitirá o uso de uma Arena em tempo real fantástica!
9 – Open-WebUI – API autenticada
A grande vantagem de usar o OI é a gestão de chaves de APIs, que lhe permitirá manter o servidor online na Internet mas só processar na IA os pedidos autenticados ou que possuam a chave de API. Com isso você poderá integrar seus bots e workflows com suas IAs próprias.
Se você tem conta no ChatGPT (OpenAI) e demais modelos comerciais, você pode usar o OI como proxy desses serviços para seus funcionários, podendo desativar a conta de um usuário dispensado.
Usando o OI como um proxy de modelos, suas chaves de API direta podem ser trocados pela API do OI.
Clique no ícone do seu usuário (canto superior direito ou canto inferior esquerdo) e vá em “Configurações“.
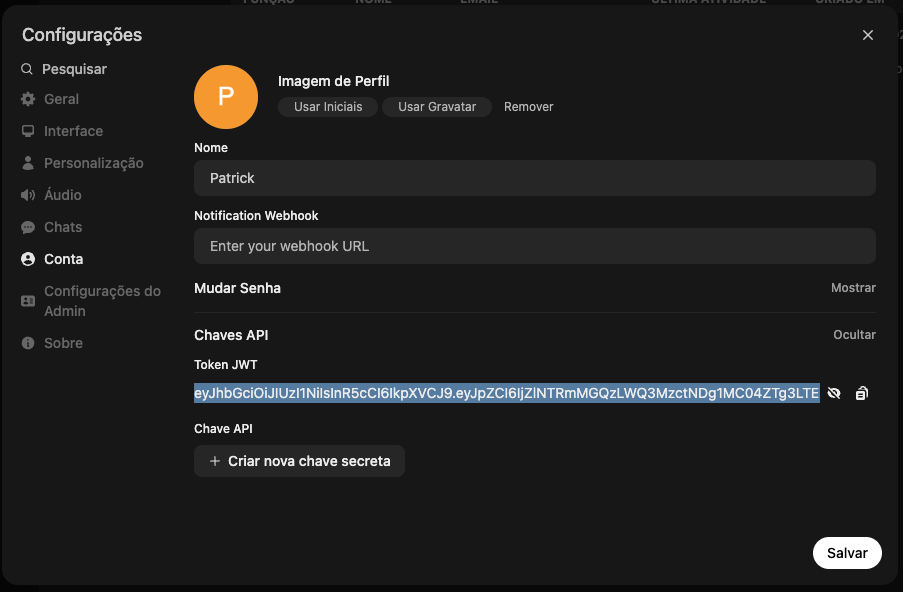
Dentro das configurações do seu usuário, vá no menu “Conta” e encontre “Chaves API”, ao mostrar a chave será exibido um “Token JWT” (JSON Web Token) da sua conta. Copie essa chave. Caso for usar em vários bots e sistemas, crie uma chave para cada um deles.
Usando a API do OI
Vou dar alguns exemplos, mas para mais detalhes da API, consulte a documentação nesses links:
- https://docs.openwebui.com/getting-started/advanced-topics/api-endpoints/
- https://docs.openwebui.com/
Nos testes abaixo, os comandos serão executados em um computador diferente pela rede ou pela Internet (se seu IA-Server possuir IP público/nome de DNS).
Com o Token em mãos, vamos fazer algumas chamadas de teste:
# Variaveis
# --------------------------------------------------------------------------
# Token (não cabe inteiro aqui, mas cole o seu token na variavel abaixo)
TOKEN="eyJhbGciOiJIUz...foThgKmftLr0_a23lyYnXc"
# Endereco do servidor de IA (IP do HOST na rede)
IASERVER="ia.meusite.com"
# Porta do OPEN-WEBUI: 3000=CPU, 3001=GPU
OIPORT="3000"
# Exemplo de chamadas
# --------------------------------------------------------------------------
# Listar modelos:
curl -X GET \
-H "Authorization: Bearer $TOKEN" \
"http://$IASERVER:$OIPORT/api/models"
# Resposta: JSON com a lista de todos os modelos e detalhes
# Gerar conteudo (Chat Completion)
curl -X POST \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
"http://$IASERVER:$OIPORT/api/chat/completions" \
-d '{
"model": "llama3.2:latest",
"messages": [
{
"role": "user",
"content": "É possível colocar um elefante dentro de uma geladeira? Responda apenas sim ou não."
}
]
}'
# Resposta (JSON):
{
"id":"llama3.2:latest-13d14591-498a-43ce-81c9-e2e921197ffa",
"created":1737397918,
"model":"llama3.2:latest",
"choices": [
{
"index":0,
"logprobs":null,
"finish_reason":"stop",
"message": {
"content":"Não.",
"role":"assistant"
}
}
],
"object":"chat.completion"
}
10 – Ollama em CPU – Afinidade
Ao executar o ollama em CPU, podemos rodar múltiplos containers para fazer melhor uso do processador.
Cada instancia em CPU do ollama faz uso de até 8 núcleos, então, em um ambiente com 64 núcleos/threads podemos rodar 8 containers e deixá-los torrando os recursos para prover trabalho balanceado.
# Baixar modelos aos quais os containers serão preferidos em manter:
docker exec -it ollama-cpu ollama pull mistral:latest
docker exec -it ollama-cpu ollama pull llama2-uncensored:latest
# Rede de modelos (repetindo, comando ja abordado):
docker network create \
-d bridge \
--subnet 172.19.0.0/24 \
-o "com.docker.network.bridge.name"="br-ias" \
-o "com.docker.network.bridge.enable_icc"="true" \
br-ias
# Rodar 8 containers em CPU com afinidade (0 a 7).
# - Não mapear portas
# - Fixar IP em 172.19.0.101 para ajudar a configuração do proxy-reverso
docker run -d \
--name ollama-cpu-c00-c07 \
-h ollama-cpu-c00-c07.intranet.br \
--network br-ias --ip=172.19.0.101 \
--restart unless-stopped \
--cpuset-cpus="0-7" \
\
-e OLLAMA_KEEP_ALIVE=990022 \
-v /storage/ia-models:/root/.ollama/models \
\
ollama/ollama
# Rodar 8 containers em CPU com afinidade (8 a 15).
# - Não mapear portas
# - Fixar IP em 172.19.0.102
docker run -d \
--name ollama-cpu-c08-c15 \
-h ollama-cpu-c08-c15.intranet.br \
--network br-ias --ip=172.19.0.102 \
--restart unless-stopped \
--cpuset-cpus="8-15" \
\
-e OLLAMA_KEEP_ALIVE=990022 \
-v /storage/ia-models:/root/.ollama/models \
\
ollama/ollama
Agora vamos pedir para o container “ollama-cpu-c00-c07” somente pedidos para o modelo “mistral:latest“, assim ele ficará sempre carregado e responderá mais rápido a pedidos sequênciais.
Ao container “ollama-cpu-c08-c15” vamos usar somente o modelo “llama2-uncensored:latest“, com o mesmo propósito.
Para testar o paralelismo em CPU dos modelos, abra duas janelas de terminal, em cada janela você rodará o loop de pedidos de um dos modelos, de forma que cada modelo gere saídas ao mesmo tempo que o outro. Como eles estão em grupos diferentes, isso não deve afetar (muito) a performance um do outro. Lembre-se que a banda CPU-RAM ainda é compartilhada.
# Rodar comandos abaixo no HOST
# Instalar comando 'jq' para extrair pedacos de JSON via shell
apt-get -y install jq
# Funcoes para encurtar o uso ollama no terminal
#------------------------------------------------------------------------
# - Pedir ao mistral
_mistral(){
MD="mistral:latest"
JREQT="{ \"model\":\"$MD\",\"prompt\":\"$1\",\"stream\":true}"
echo
curl --no-buffer -X POST \
"http://172.19.0.101:11434/api/generate" \
-H "Content-Type: application/json" \
-d "$JREQT" 2>/dev/null | while read jline; do
#echo "$jline" | jq -r '.response' | tr -d '\n'
jtoken=$(echo "$jline" | jq -r '.response' 2>/dev/null)
echo -n "$jtoken"
done
echo
}
# - Pedir ao llama2-uncensored
_llama2u(){
MD="llama2-uncensored:latest"
JREQT="{ \"model\":\"$MD\",\"prompt\":\"$1\",\"stream\":true}"
echo
curl -X POST \
"http://172.19.0.102:11434/api/generate" \
-H "Content-Type: application/json" \
-d "$JREQT" 2>/dev/null | while read jline; do
jtoken=$(echo "$jline" | jq -r '.response' 2>/dev/null)
echo -n "$jtoken"
done
echo; echo;
}
# Iniciar testes em loop
#------------------------------------------------------------------------
# Terminal 1 - Testes de mistral
# Fazendo múltiplos pedidos ao "mistral:latest"
for i in 1 2 3 4 5 6; do
_mistral "Com apenas 1 frase, conte um fato esquisito"
_mistral "Com apenas 1 frase, conte uma piada de cachorro"
_mistral "Com apenas 1 frase, conte uma mentira famosa"
done
# Terminal 1 - Testes de llama2-uncensored
# Fazendo múltiplos pedidos ao "llama2-uncensored:latest"
for i in 1 2 3 4 5 6; do
_llama2u "Com apenas 1 frase, conte um fato esquisito"
_llama2u "Com apenas 1 frase, conte uma piada de cachorro"
_llama2u "Com apenas 1 frase, conte uma mentira famosa"
done
Conseguiu ter ideias mirabolantes? Compartilhe-as!
Considerações
Espero que o artigo te ajude a iniciar bem com sua IA local. Se possui alguma contribuição por favor me envie: patrickbrandao@gmail.com
Terminamos por hoje, isso deve ter te economizado muito tempo!
Patrick Brandão, patrickbrandao@gmail.com