Saudações.
Vou abordar nesse tutorial várias formas de comprimir e descomprimir arquivos no Linux.
Pré-requisitos (constam em outros artigos aqui do blog):
- Instalação do Linux (Debian);
- Internet no servidor para instalar os programas;
Programas necessários para praticar os exemplos:
# Instalar
apt -y install tar zstd gzip zip unzip lz4 bzip2 xz-utils;
1 – Conceitos e principio
Neste tutorial, uso ‘ficheiro’ para me referir ao arquivo resultante da compactação (archive), diferenciando-o de ‘arquivo’ que são os dados originais.
Quando falamos em comprimir e compactar arquivos, precisamos definir esses dois verbos pontualmente:
- Compactar é colocar os arquivos espalhados juntos no mesmo ficheiro, 10 arquivos de 1MB resultarão em um arquivo ficheiro de 10MB, não há economia do ponto de vista do usuário;
- Comprimir é tentar reduzir o tamanho dos arquivos por meio de dicionários de repetição de conteúdo, assim, 10 arquivos de 1MB que juntos somam 10MB mas se possuem conteúdos repetidos podem ser resumidos em um único ficheiro de 3MB que contem instruções para reconstruir os 10 arquivos originais.
1.1 – Compactação
A compactação ajuda o sistema de arquivos (FS) que normalmente aloca espaço em blocos físicos de 4KB, o que pode ser muito ruim se você criar 1 milhão de arquivos contendo 1 byte cada: você terá 1 MB de espaço útil ao usuário mas causará um prejuízo de 4 GB no sistema de arquivos (4 KB por bloco × 1.000.000 arquivos = 4.000.000 KB = ~4 GB). Compactar esses arquivos em um único arquivo-ficheiro ajuda o sistema de arquivos a economizar blocos.
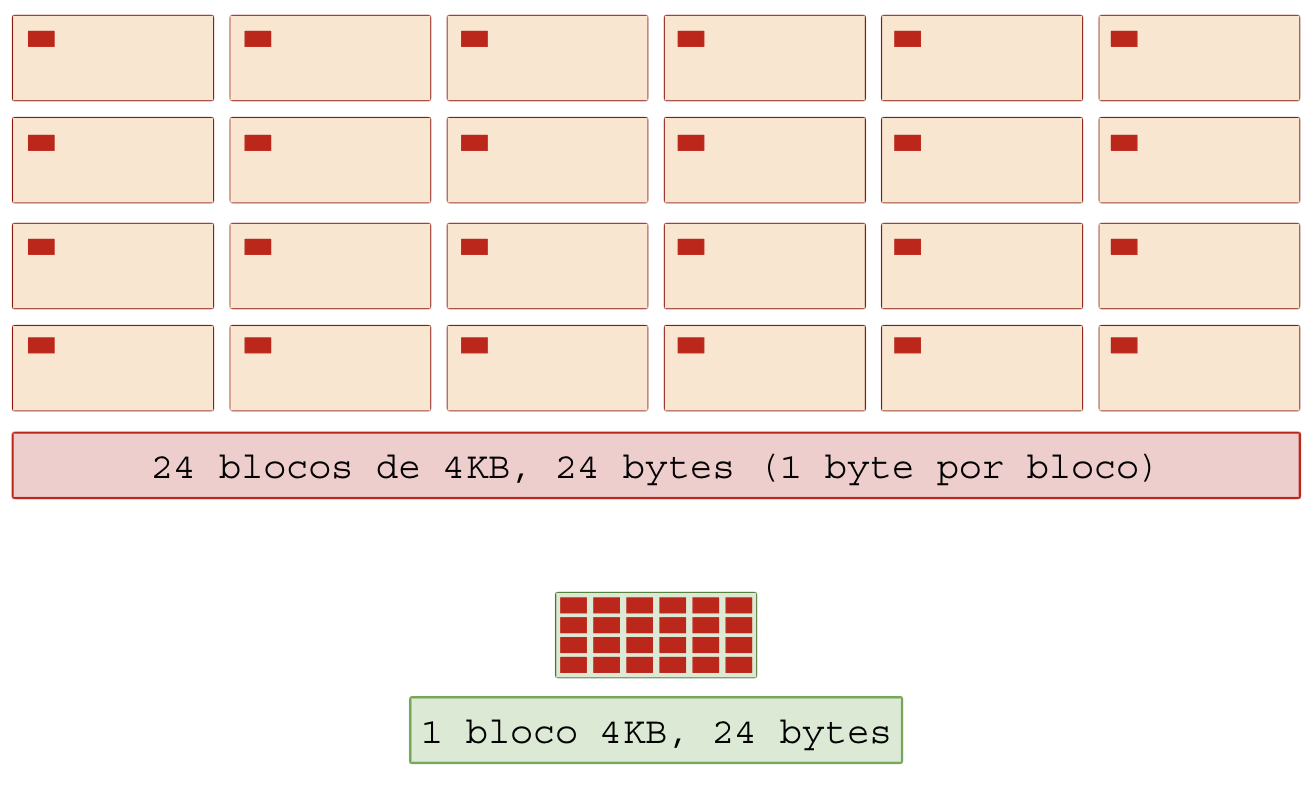
1.2 – Compressão
A compressão por sua vez atua dentro do arquivo que reuniu todos os dados compactados e agora precisa economizar espaço evitando a repetição. Se você gerar 1 milhão de cópias de um arquivo de 1MB, totalizando 1 Terabyte, é melhor anotar a instrução “repita o arquivo-X 1 milhão de vezes” do que realmente alocar todo o espaço com cópias.
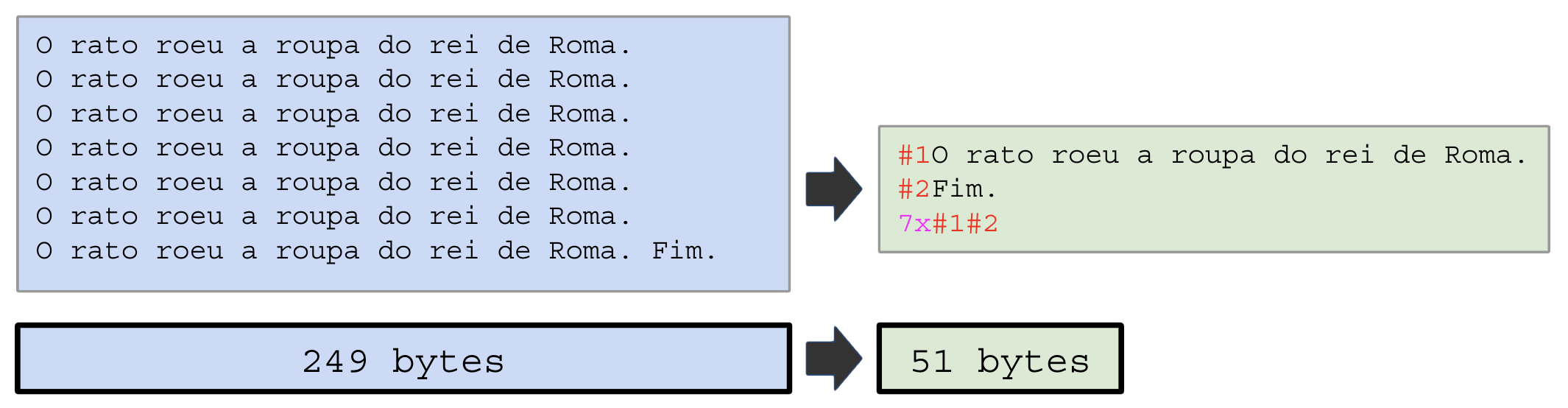
A soma de compactação e compressão ajudam muito a economizar espaço em disco, mas não ajuda a CPU, que precisará percorrer todos os arquivos, mapear o dicionário e criar a representação binária das instruções de remontagem.
1.3 – Compressão com perda
Não vou dar exemplos desse modo mas vale a pena explicar: a compressão com perda é usada em imagens, videos e áudio. O tamanho dos dados é reduzido deletando informação!
A imagem pode ser comprimida reduzindo a quantidade de bits por pixels, o que empobrece a diferença entre as cores, mesclando pixels por interpolação. Isso deixa a imagem um pouco mais borrada e com as bordas quadriculadas e é capaz de reduzir em até 40% o tamanho dos dados sem afetar a qualidade percebida pelo usuário (de longe!).

A compressão de áudio segue a mesma ideia de reduzir a definição do som. A voz fica robotizada e o tom da voz pode mudar drasticamente, isso é muito percebido em ligações 3G/4G pois as operadoras abusam da compressão com perda para reduzir uso da rede.
CODEC (codificador/decodificador) é o nome do algoritmo que faz esse papel.
1.4 – Compressão inteligente
Convolutional Neural Network (CNNs) e Generative Adversarial Network (GAN) podem se aliar para transformar uma imagem ou audio extremamente comprimido com perdas e gerar uma versão de alta qualidade (upscaling), interpolando e “inventando” conteúdo entre os pedaços. Isso permite que imagens HD possam ser escaladas até 8K, esse recurso tem sido implementado em jogos e TVs modernas.
Exemplo: uma foto do seu olho ocupando 2MB (A) pode ser comprimida até ocupar 128KB (B) e então armazenada ou transmitida. Na descompressão, a IA consegue entender o arquivo pequeno, detectar o olho com detalhes (formato, cor, angulo, iluminação) e gerar um olho igual em alta resolução (C). Diferente da primeira imagem que poderia ser usado para leitura biométrica, a imagem regenerada pela IA não consegue prover informações biométricas pois os detalhes são “imaginados”, preenchido com dados do treinamento.

1.5 – Entropia
A entropia mede o grau de ordem e desordem de um meio.
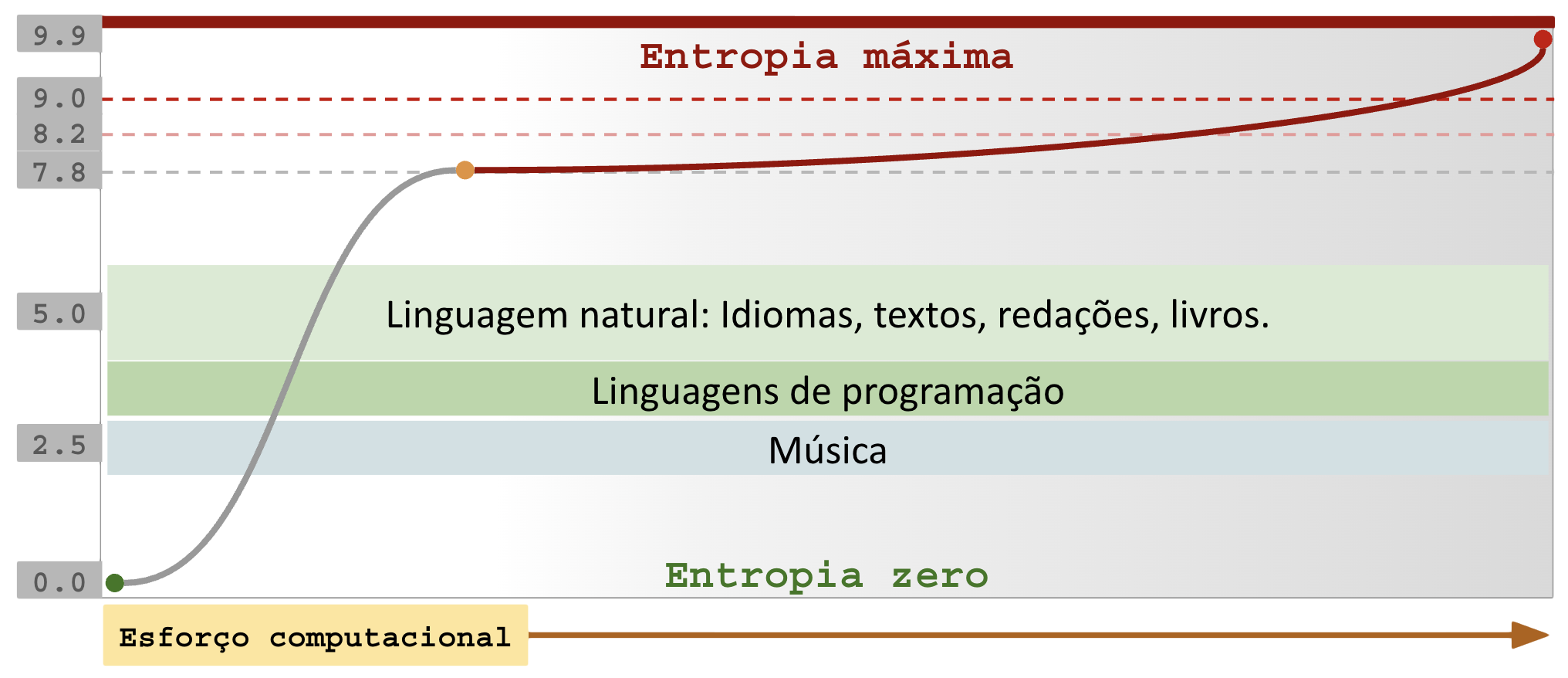
Aplicado a dados digitais, baixa entropia significa que há muitos bytes repetidos em sequência.
Um arquivo de 1GB contendo a letra “A” repetida 1 bilhão de vezes possui ZERO (0.0) entropia, o que significa que poderia se representado em menos de 4 bytes (99.999999% de ganho na compressão).
Um arquivo de 1GB contendo um documento secreto criptografado possui 7.8 de entropia, o que torna extremamente difícil localizar repetições.
Temos a seguinte regra: baixa entropia é bom para compressão, alta entropia é péssimo para compressão pois gasta CPU em vão, por isso imagens e sons apelam para compressão com perdas para reduzir o espaço ocupado.
1.6 – Compressão e criptografia
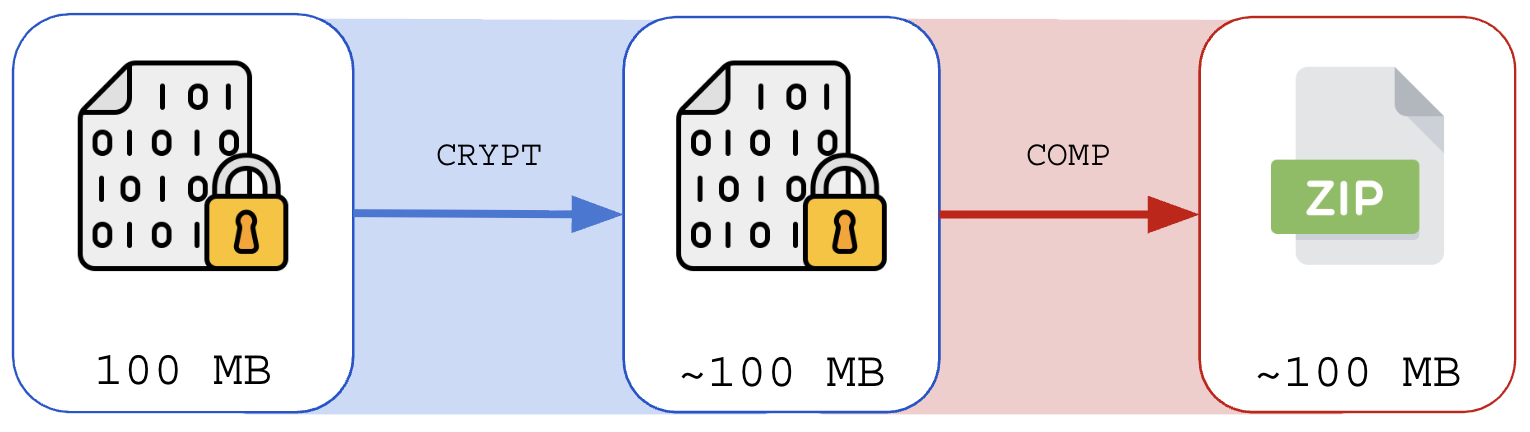
Conteúdo criptografado possui alta entropia, por conta disso a compressão de conteúdo deve ser feita antes do processo de criptografia.
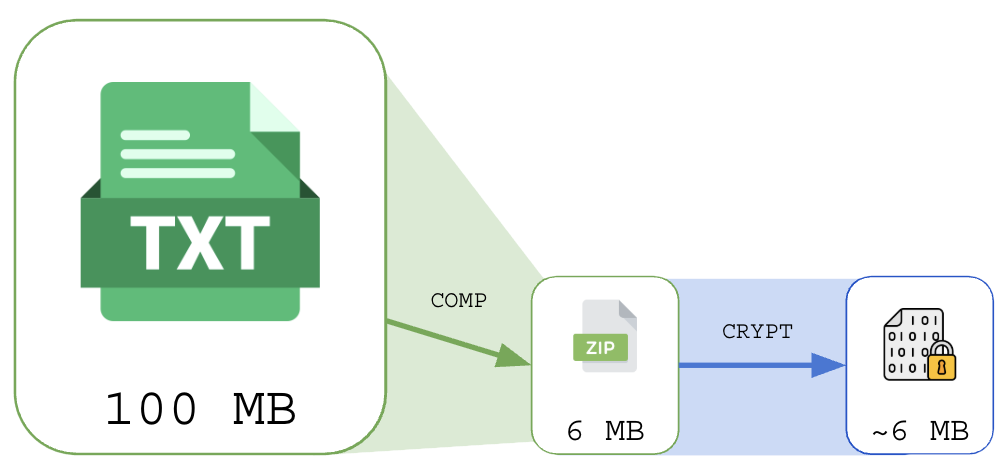
Tentar comprimir um arquivo criptografado é futilidade:
1.7 – Transmissão comprimida
A compressão pode ajudar a economizar largura de banda ao enviar dados pela rede.

Para que isso seja eficiente a compressão deve escolher onde atuar.
- Compressão na camada de aplicação: protocolos como HTTP podem codificar (Encoding) o texto (HTML, CSS, Javascript, JSON) e informar no cabeçalho HTTP da requisição e da respostas os algoritmos suportados. É uma escolha entre largura de banda versus consumo de CPU.
- Otimizar largura de banda: todo conteúdo precisará ser comprimido e o servidor HTTP deve suportar cache de arquivos comprimidos para evitar repetir trabalho, o consumo de CPU para comprimir todos os arquivos e o conteúdo dinâmico precisa ser pensado quando aplicado em larga escala;
- Otimizar CPU: não comprimir e deixar o volume (bytes) e a quantidade de pacotes por segundo (pps) ser um problema da rede.
- Compressão na camada IP: VPNs e alguns protocolos de rede suportam compressão LZO, que comprime quadros e pacotes IP;
- Compressão na camada de enlace: embora mais raro, é constantemente aplicada em enlaces de rádio;
Compressão HTTP:
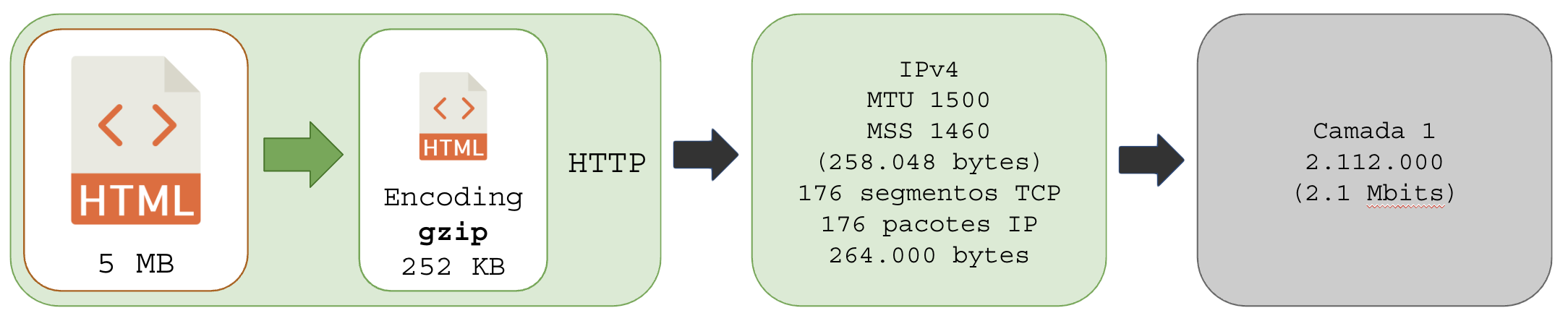
Aplica-se aqui o mesmo conceito da criptografia: se uma camada comprimir as informações (HTTP por exemplo), a entropia dos dados será elevada e a camada de baixo não conseguirá nenhum proveito de compressão, apenas gastando CPU e induzindo latência em buffer em vão.
1.8 – Algoritmos
A eficiência da compressão e compactação depende de como o software faz a compressão, visto que a descompressão é muito simples (basta ler o dicionário de metadados e ir remontando o dado original). Tipos e quanto usar:
- Família ZIP (zip/unzip): Compartilhar com usuários Windows/Mac/Smartphone ou quando precisa de arquivo único com múltiplos arquivos;
- Família GZIP (gzip/gunzip): Uso geral, boa compatibilidade, padrão em servidores web, sendo aos poucos substituidos pelo zstd;
- Família BZIP2 (bzip2/bunzip2): Legado, sendo substituído por xz e zstd;
- XZ/LZMA (xz/unlzma): Arquivamento de longo prazo, distribuição de software, uma vez comprimido ao extremo ele tem utilidade eterna;
- ZSTD (Zstandard): Melhor escolha moderna para a maioria dos casos;
- LZ4: Sistemas em tempo real, rede, rádio, VPN, caches, filesystems;
A escolha está ligada ao propósito e a quantidade de recursos computacionais (CPU e RAM) que serão comprometidos.
Detalhes importantes:
- gzip, bzip2 e zstd: são “stream compressors” — processam dados sequencialmente e não suportam múltiplos arquivos nativamente (por isso usamos
tar); - zip: inclui metadados de diretório, permitindo listar conteúdo sem descomprimir (
unzip -l) - zstd: é o mais moderno e está substituindo os demais tipos em muitas distribuições (kernel Linux, pacotes Arch/Fedora);
1.9 – Uso prático dos algoritmos
Pondere:
- Taxa/Ganho de compressão: espaço economizado em arquivos de baixa entropia;
- Velocidade compressão: importante se você tem pressa para disponibilizar os dados comprimidos para os usuários e sistemas;
- Velocidade para descompressão: importante se você tem pressa em usar os dados descomprimidos para entregar a usuários e sistemas;
- Uso de CPU/RAM: importante se o sistema é dedicado ou compartilhado, ambientes de STORAGE tem CPU dedicada e o importante é extrair o máximo dela, já ambientes compartilhados (Docker, VMs, VPS, ERP, …) a CPU precisa estar pronta para os sistemas e se sua compressão tomar conta da CPU e da RAM tudo vai ficar horrivel e causar efeitos colaterais;
| Sistema | Taxa/ganho de Compressão | Velocidade de compressão | Velocidade de descompressão | CPU/RAM |
|---|---|---|---|---|
| lz4 | 2/10 | 10/10 | 10/10 | Baixo |
| gzip | 6/10 | 8/10 | 8/10 | Baixo |
| zstd | 8/10 | 8/10 | 10/10 | Médio |
| bzip2 | 8/10 | 4/10 | 6/10 | Médio |
| xz | 10/10 | 2/10 | 6/10 | Alto |
Não é uma escolha fácil, é possível perceber que o zstd pontua bem em quase tudo! Para desempatar, decida: o que é mais importante no seu servidor, o que vc não quer estressar, CPU, REDE ou DISCO ?
- Economizar CPU: gzip é o melhor, comprime bem com pouco uso de CPU;
- Economizar Rede: zstd é o melhor para economizar banda e atender rápido;
- Economizar Disco: xz é o melhor para economizar disco, maior ganho de espaço, mas a CPU vai sofrer;
2 – Arquivadores
Arquivadores são programas especializados em compactação, ou seja, apenas agregar os diretórios e arquivos em um único arquivo ficheiro.
Se você comprimir 20 arquivos de 1MB o resultado é um arquivo ficheiro de 20 MB. Só isso!
| Programa | Uso prático |
|---|---|
| tar | Distribuição de software, backups, uso geral, líder do segmento |
| cpio | Usado no disco de RAM (initrd, initramfs) do Linux e pacotes RPM |
| ar | Arquivador oficial dos pacotes de programas do Debian (pacotes .deb) |
| shar | Shell archive, usado na distribuição de email/usenet (legado, histórico) |
| pax | POSIX standard (híbrido tar/cpio), provê portabilidade POSIX |
Dos 5 conhecidos, apenas 3 fazem parte do dia-a-dia: tar, cpio e ar
2.1 – Arquivador TAR
O Tar (tape archived) é um programa que reune arquivos e diretórios em um ficheiro continuo. Ele não é um software originalmente pensado em compactação (apenas juntar arquivos, sem comprimir)!
Seu objetivo inicial era colocar arquivos em sequência para gravação em fitas DAT.
2.1.1 – TAR de compactação SEM compressão
Esse método deve ser usado para fazer um ficheiro de backups de arquivos binários (snapshots de VMs, arquivos criptografados, binários de programas), onde a entropia é alta e não vale a pena gastar tempo tentando comprimir.
Compactação:
# Criar pasta com arquivos a comprimir
mkdir /tmp/pasta01;
# Criar arquivos
# - Arquivo com 10m de zeros:
dd if=/dev/zero of=/tmp/pasta01/zeros-10m.bin bs=10000000 count=1;
# - Arquivo com 10m de dados aleatórios:
dd if=/dev/urandom of=/tmp/pasta01/random-10m.bin bs=10000000 count=1;
# Colocar a pasta em um ficheiro TAR:
tar -cpvf /tmp/ficheiro-01.tar /tmp/pasta01;
# Conferir arquivo:
ls -lah /tmp/ficheiro-01.tar;
# -rw-r--r-- 1 root root 20M Dec 19 20:18 /tmp/ficheiro-01.tar
stat /tmp/ficheiro-01.tar;
# File: /tmp/ficheiro-01.tar
# Size: 20008960 Blocks: 39080 IO Block: 4096 regular file
# Device: 0,33 Inode: 7299836 Links: 1
# Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
# Access: 2025-12-19 20:18:24.964363711 -0300
# Modify: 2025-12-19 20:18:24.980363991 -0300
# Change: 2025-12-19 20:18:24.980363991 -0300
# Birth: 2025-12-19 20:18:24.964363711 -0300
Observe que o arquivo TAR ficou com 20M pois juntou 2 arquivos de 10M cada.
Descompactação do ficheiro TAR:
# Criar pasta para destino dos arquivos:
mkdir /tmp/extraido01;
# Extrair arquivos do ficheiro na pasta destino:
tar -xvf /tmp/ficheiro-01.tar -C /tmp/extraido01;
# Conferindo:
du -hs /tmp/extraido01/;
# 20M /tmp/extraido01/
2.1.2 – TAR de compactação COM compressão gzip (-z)
Vamos usar o GZIP como método de compressão dos arquivos:
# Criar pasta com arquivos a comprimir
mkdir /tmp/pasta02;
# Criar arquivos
# - Arquivo com 10m de zeros:
dd if=/dev/zero of=/tmp/pasta02/zeros-10m.bin bs=10000000 count=1;
# - Arquivo com 10m de dados aleatórios:
dd if=/dev/urandom of=/tmp/pasta02/random-10m.bin bs=10000000 count=1;
# Colocar a pasta em um ficheiro TAR:
tar -cpzvf /tmp/ficheiro-02.tar.gz /tmp/pasta02;
# Conferir arquivo:
ls -lah /tmp/ficheiro-02.tar.gz;
# -rw-r--r-- 1 root root 9.6M Dec 19 20:23 /tmp/ficheiro-02.tar
stat /tmp/ficheiro-02.tar.gz;
# File: /tmp/ficheiro-02.tar.gz
# Size: 10011742 Blocks: 19560 IO Block: 4096 regular file
# Device: 0,33 Inode: 7301500 Links: 1
# Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
# Access: 2025-12-19 20:23:29.893707648 -0300
# Modify: 2025-12-19 20:23:41.337908464 -0300
# Change: 2025-12-19 20:23:41.337908464 -0300
# Birth: 2025-12-19 20:23:29.893707648 -0300
Observe que o TAR reunindo 2 arquivos de 10MB cada resultou num ficheiro de 9.6M, isso se deu porque o arquivo /tmp/pasta02/zeros-10m.bin é de entropia zero e praticamente foi reduzido a poucos bytes, já o arquivo /tmp/pasta02/random-10m.bin é de alta entropia (~7.9) e não teve ganho relevante (apenas 4% de economia).
Descompactação do ficheiro TAR Gzip:
# Criar pasta para destino dos arquivos:
mkdir /tmp/extraido02;
# Extrair arquivos do ficheiro na pasta destino:
tar -xvf /tmp/ficheiro-02.tar -C /tmp/extraido02;
# Conferindo:
du -hs /tmp/extraido02/;
# 20M /tmp/extraido02/
2.1.3 – Argumentos do TAR
Opções e comandos do TAR.
Fluxo na STDOUT (saída padrão):
# Jogando o fluxo TAR na saída (STDOUT) do terminal
# (nao rode, vai bugar seu terminal todo)
tar cf - /tmp/pasta02 | cat;
# Direcionando o fluxo TAR da STDOUT para um arquivo:
# - tem o mesmo efeito de: tar -cpvf /tmp/ficheiro-02.tar /tmp/pasta02;
tar cf - /tmp/pasta02 > /tmp/ficheiro-02.tar;
# Usando o TAR para copiar arquivos de um diretorio para o outro
# mantendo todos os atributos (alternativa ao rsync)
mkdir /tmp/destino03;
tar cf - /tmp/pasta02 | ( cd /tmp/destino03; tar xvf - );
# Conferindo:
find /tmp/destino03/
# /tmp/destino03/
# /tmp/destino03/tmp
# /tmp/destino03/tmp/pasta02
# /tmp/destino03/tmp/pasta02/zeros-10m.bin
# /tmp/destino03/tmp/pasta02/random-10m.bin
2.1.4 – Diferentes combinações de TAR e compressores
Nos exemplos abaixo o TAR produz o fluxo na STDOUT para que o compressor atue de maneira personalizada na compressão, permitindo ganhos de velocidade ou economia:
# Quantidade de núcleos de CPU a utilizar
# NCPUS=4;
NCPUS=$(nproc); # todas as CPUs do sistema
# Diretorio a compactar e comprimir:
DIRECTORY="/tmp/arquivos07";
# Criar diretorio e sub-diretorios:
mkdir -p "$DIRECTORY";
mkdir -p "$DIRECTORY/textos";
mkdir -p "$DIRECTORY/binarios";
mkdir -p "$DIRECTORY/system";
# Popular com arquivos:
echo "Ola mundo" > $DIRECTORY/textos/ola-mundo.txt;
printf 'Hora de tomar cafe.\n%.0s' {1..5000} > $DIRECTORY/textos/cafe.txt;
dd if=/dev/zero of=$DIRECTORY/binarios/zeros bs=1024000 count=1;
dd if=/dev/urandom of=$DIRECTORY/binarios/random bs=1024000 count=1;
cat /etc/os-release > $DIRECTORY/system/os-release;
ps ax > $DIRECTORY/system/ps-ax.txt;
#--------------------------------------------- TAR + XZ = .txz ou .tar.xz
# Tar > XZ, compressao simples
( tar cvf - $DIRECTORY | xz -e -c - > /tmp/package07a.tar.xz; );
# Tar > XZ, compressao máxima
( tar cvf - $DIRECTORY | xz -9 -e -c - > /tmp/package07b.tar.xz; );
# Tar > XZ, compressao máxima usando todos os núcleos do servidor
( tar cvf - $DIRECTORY | xz -T $NCPUS -9 -e -c - > /tmp/package07c.tar.xz; );
#--------------------------------------------- TAR + GZIP = .tar.gz ou .tgz
# Tar > Gzip, compressao simples
( tar cvf - $DIRECTORY | gzip -c > /tmp/package07d.tar.gz; );
# Tar > Gzip, compressao maxima
( tar cvf - $DIRECTORY | gzip -9c > /tmp/package07e.tar.gz; );
#--------------------------------------------- TAR + ZSTD = .tar.zst ou .tzst
# Tar > Zstd, compressao simples
( tar cvf - $DIRECTORY | zstd -T0 -3 - -o /tmp/package07f.tar.zst; );
# Tar > Zstd, compressao moderada
( tar cvf - $DIRECTORY | zstd -T0 -11 - -o /tmp/package07g.tar.zst; );
# Tar > Zstd, compressao extrema/maxima
( tar cvf - $DIRECTORY | zstd -T0 -19 - -o /tmp/package07h.tar.zst; );
#--------------------------------------------- TAR + LZ4 = .tar.lz4 ou .tlz4
# Tar > LZ4, compressao simples
( tar cvf - $DIRECTORY | lz4 - /tmp/package07i.tar.lz4; );
# Tar > LZ4, compressao maxima
( tar cvf - $DIRECTORY | lz4 -9 - /tmp/package07j.tar.lz4; );
Se você aprendeu e praticou, parabéns, você é o mestre do arquivamento.
“I had strings
But now I’m free
There are no strings on me“
Autor: Ultron/Pinocchio
Terminamos por hoje!
Patrick Brandão, patrickbrandao@gmail.com