
Saudações.
Esse tutorial é um guia de homologação de redes de infra e backbone voltado aos administradores de redes.
O objetivo dos procedimentos de homologação é garantir a:
- Qualidade: Analisar a presença de perda de pacotes e flutuações na latência;
- Largura de banda: Atingir 100% da capacidade em bits dos enlaces;
- Qualificação: Garantir que a rede está apta a atender os requisitos técnicos, essa é a última etapa da homologação para garantir a operação comercial da rede;
- Certificação: Garantir que a rede atende as normas necessárias com comprovantes emitidos por equipamentos previamente certificado (quem certifica o certificador?).
O capítulo 1 é especialmente detalhado para que os problemas que pareçam ocultos se tornem óbvios ao conhecer as regras.
Os demais capítulos exploram os procedimentos a serem realizados no caminho até a homologação e certificação.
1 – Princípios de redes de computadores
Quando ligamos vários equipamentos em redes precisamos estar cientes de regras inquestionáveis que nascem da natureza física e matemática que deram origem às redes de computadores.
1.1 – Overhead
A velocidade das tecnologias rede redes são medidas em bits por segundo. Os arquivos, videos, músicas usados pelos usuários são contados em bytes. 1 byte = 8 bits
Velocidades em bits:
| Unidade | Símbolo | Bits | Bytes |
|---|---|---|---|
| Kilobit | Kbit | 1.000 | 125 bytes |
| Megabit | Mbit | 1.000.000 | 125 KB |
| Gigabit | Gbit | 1.000.000.000 | 125 MB |
| Terabit | Tbit | 1.000.000.000.000 | 125 GB |
Volumes em bytes e bits necessários (não considera overhead):
| Unidade | Símbolo | Bytes | Total de bits | Banda |
|---|---|---|---|---|
| Bit | b | 0,125 | 1 bit | — |
| Byte | B | 1 | 8 bits | 8 bit/s |
| Kilobyte | KB | 1.000 | 8.000 bits | 8 Kbit/s |
| Megabyte | MB | 1.000.000 | 8.000.000 bits | 8 Mbit/s |
| Gigabyte | GB | 1.000.000.000 | 8.000.000.000 bits | 8 Gbit/s |
Assim, para transmitir um arquivo de 2 GB (2 gigabyte, 2 bilhões de bytes) são necessários transformá-los em uma sequência pura (RAW bits) de 16 Gbit (16 Gbit, 16 bilhões de bits).
O arquivo será picado em pacotes (packets) e transmitidos em unidades eletrônicas salto a salto chamados quadros (frames).
Existe o consumo de bytes de cabeçalhos para transmitir esses dados, esse consumo é chamado overhead:
- Camada 1 (ethernet): 26 bytes por quadro;
- Camada 2 (ethernet): 14 a 22 bytes por quadro;
- Camada 3 (IP): 20 a 40 bytes por pacote;
- Camada 4 (UDP, TCP): 8 a 20 bytes por segmento;
- Camadas superiores: Blocos de criptografia, negociações, cabeçalhos dos protocolos (HTTP, FTP, SMTP, etc…).
Assim, quando um enlace possui limite de 10 Gbit/s essa velocidade é determinada pela capacidade da camada 1, não da capacidade entregue ao usuário final.
O overhead resultar no consumo na camada 1 de:
- Pacotes jumbo: 9.000 bytes por pacote – 1%;
- Pacotes de internet: 1500 bytes, – +2%;
- Pacotes pequenos (syn, ack, rst, dns): até +34%.
Para transmitir um arquivo de 1 GB (1 gigabyte) são necessários alocar mais de 8 Gbit (8 gigabits).
Aplique a regra ( tamanho_em_bytes X (8+1) = bits_necessários ).
1.2 – Principio do Gargalo
Regra: A largura de banda máxima entre dois pontos é determinado pela menor largura de banda entre todos os enlaces no caminho.
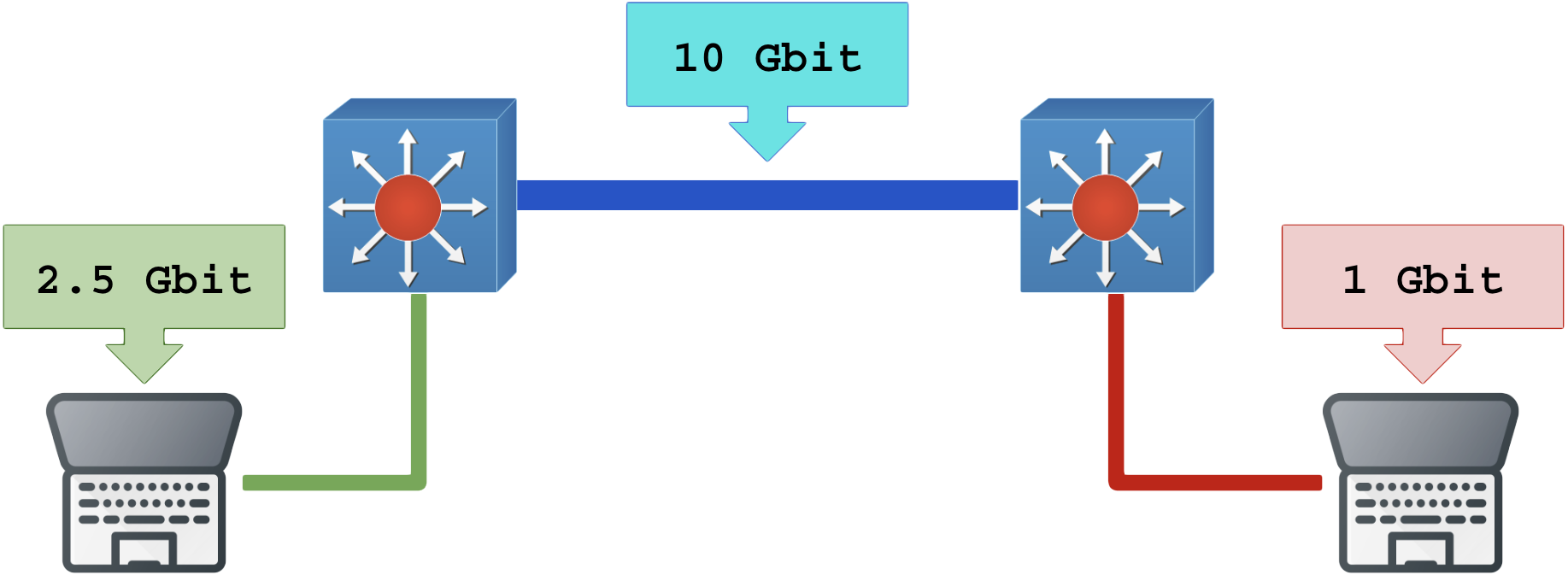
Gargalo físico simples
No exemplo abaixo temos 3 enlaces. A banda máxima mensurada entre os dois computadores (nós) jamais será superior a 1 Gbit pois esse é o menor enlace entre eles.
Gargalo por compartilhamento de caminho
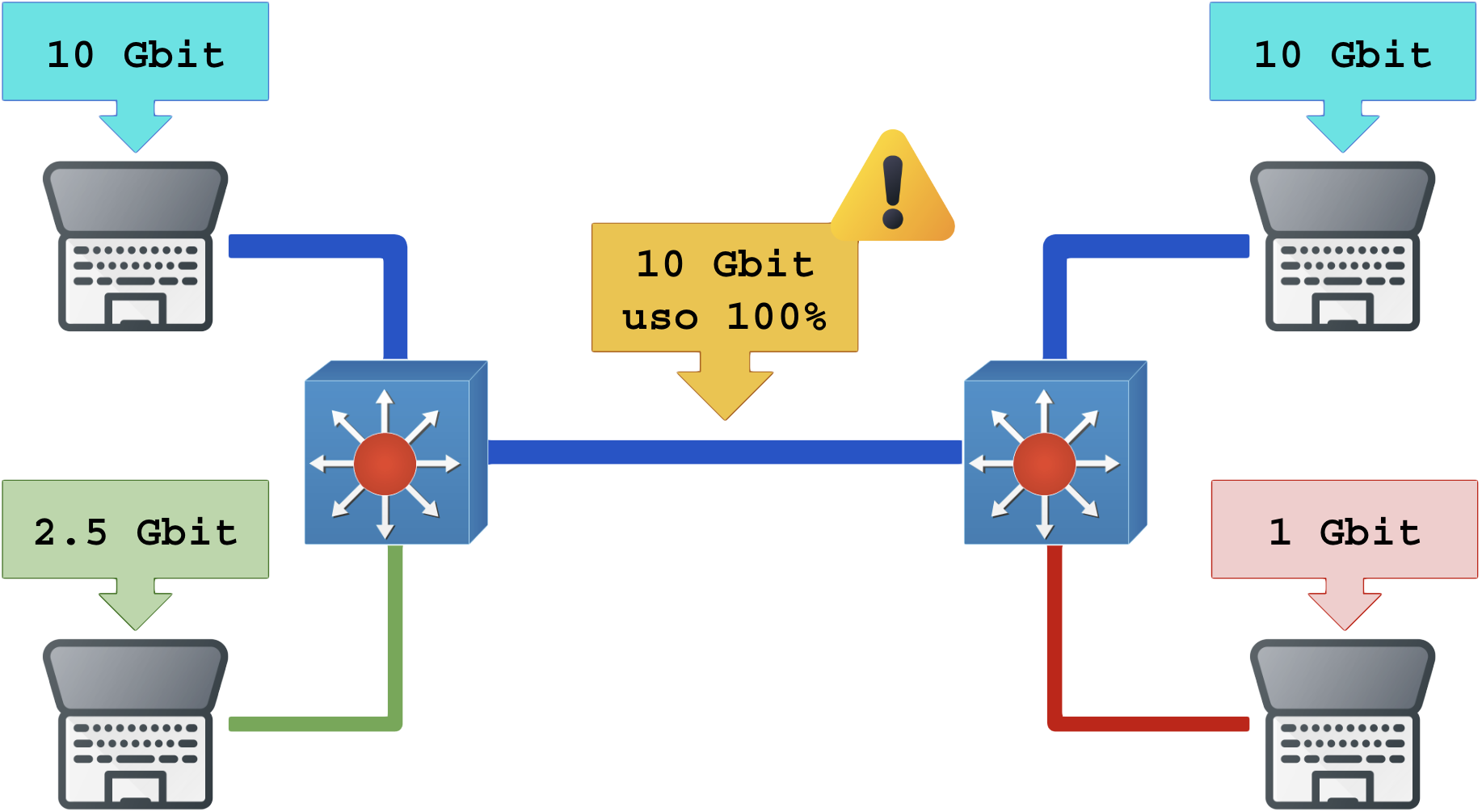
Observe o desenho abaixo: Os dois computadores usando 10 Gbit conseguem consumir 10 Gbit fim-a-fim entre eles (três enlaces de 10 Gb), enquanto que os dois computadores de baixo terão dificuldades de usar a rede pois haverá competição arbitrária por banda visto que todos compartilham um enlace de 10 Gb em comum. Seriam necessários pelo menos 11 Gbit entre os switchs para atender os dois casos com garantia de banda.
1.3 – Rateio e Overcommit
Quando ligamos vários nós em um equipamento que faz uplink para outros, não consideramos garantir nesse uplink a banda total somada.
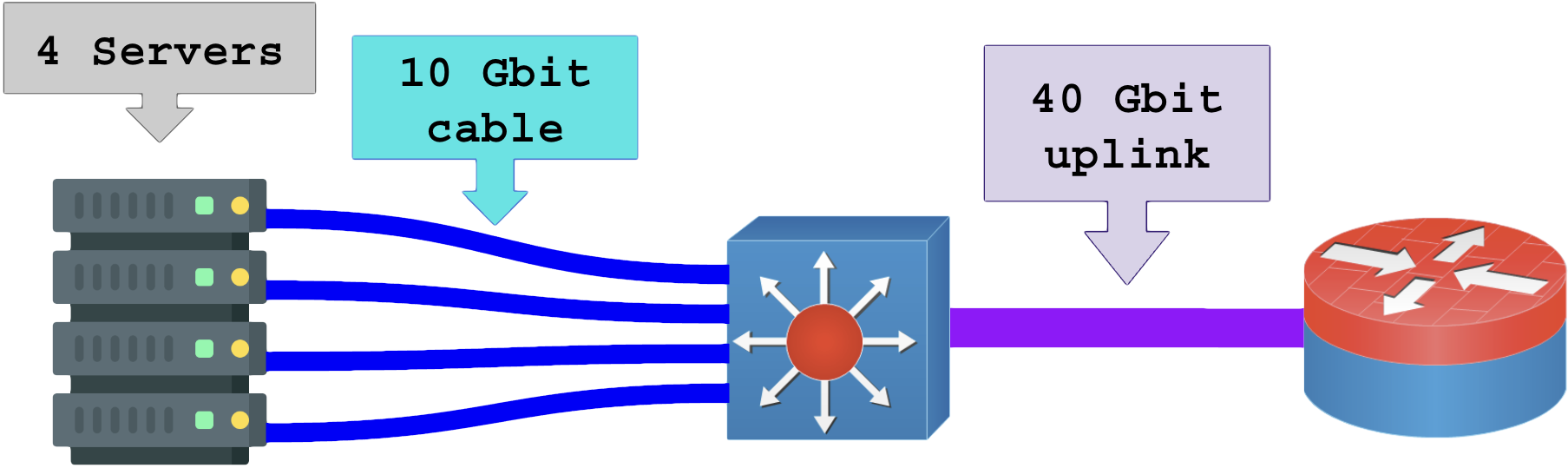
Sem rateio de banda (sem overcommit):
Com rateio de banda (overcommit 2x):
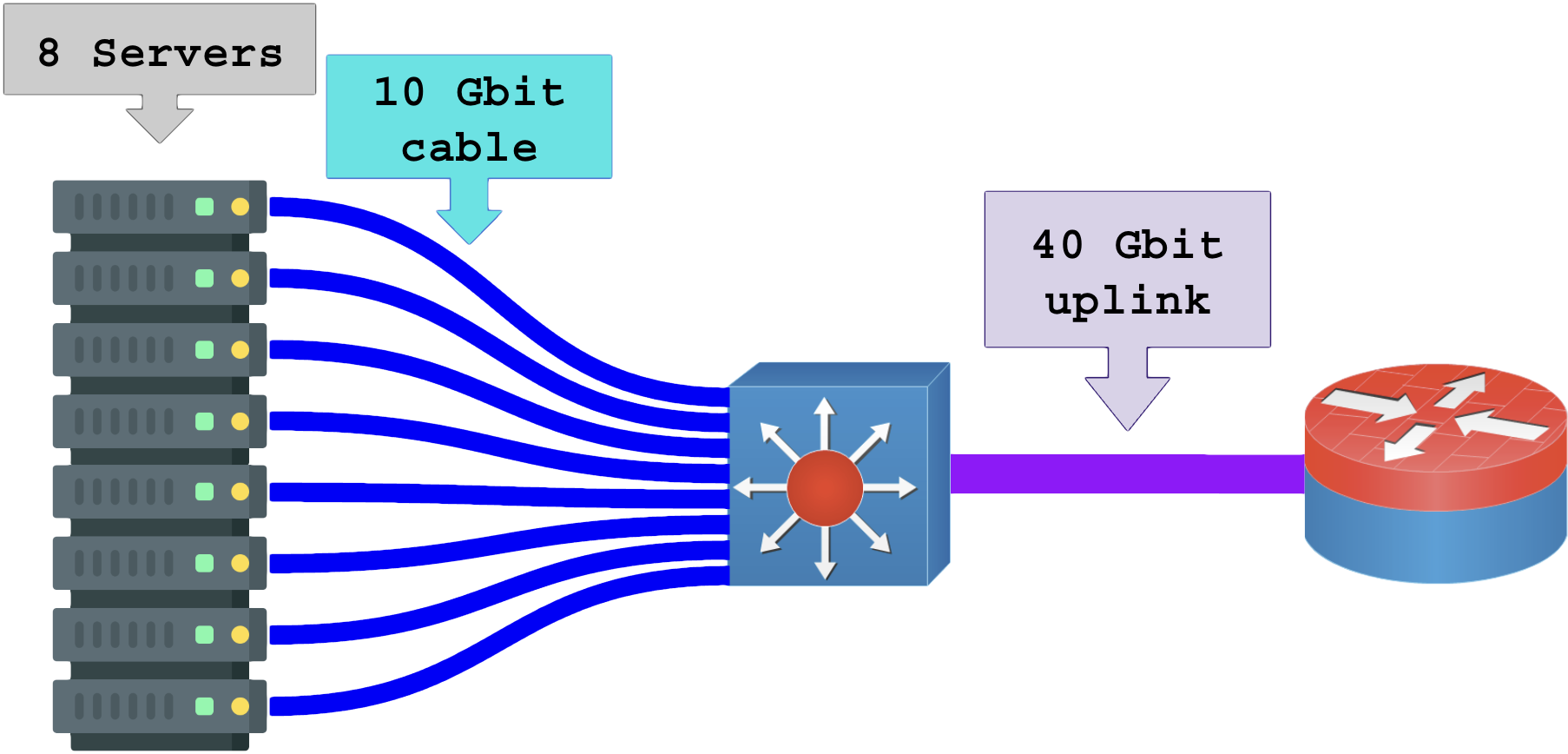
Na figura acima existe rateio de banda. O uplink é incapaz de atender a demanda de todos os servidores ao mesmo tempo. Seriam necessários 80 Gbit de uplink para atender 8 servidores ligados a 10 Gbit cada. A relação entre a soma total necessária (T) e a quantidade disponível (R) determina o overcommit, logo (O=T/R), overcommit 2x.
O mundo real não suporta prover meios de transportes capazes de suportar toda a demanda em tempo real, estradas, rodovias, aeroportos, redes de Internet, datacenters consideram a média de uso real para calcular a largura de uplink. Exemplos:
- Em 2015 a média de consumo por usuário de Internet era de 900 Kbit/s, um provedor de Internet com 10.000 (dez mil) clientes precisava ter de conexão real com a internet apenas 9.000.000 kbit (9 Gbit/s) para atender esses clientes;
- Em 2025 a média de consumo por usuário era de 2.200 Kbit/s (2 Mbit), logo, o mesmo provedor de 10 mil clientes precisaria ter pelo menos 22.000.000 Kbit/s (22 Gbit);
Uma operadora que vender links para outro provedores não poderá fazer o mesmo cálculo de overcommit, por isso o valor do Mbit é mais caro quando o overcommit não é possível sem afetar o SLA.
A pergunta que surge é:
Quando a Internet fica ruim, como provar que a culpa é do fornecedor quando ele está fazendo overcommit?
Rede de operadora condenada por overcommit acumulado:
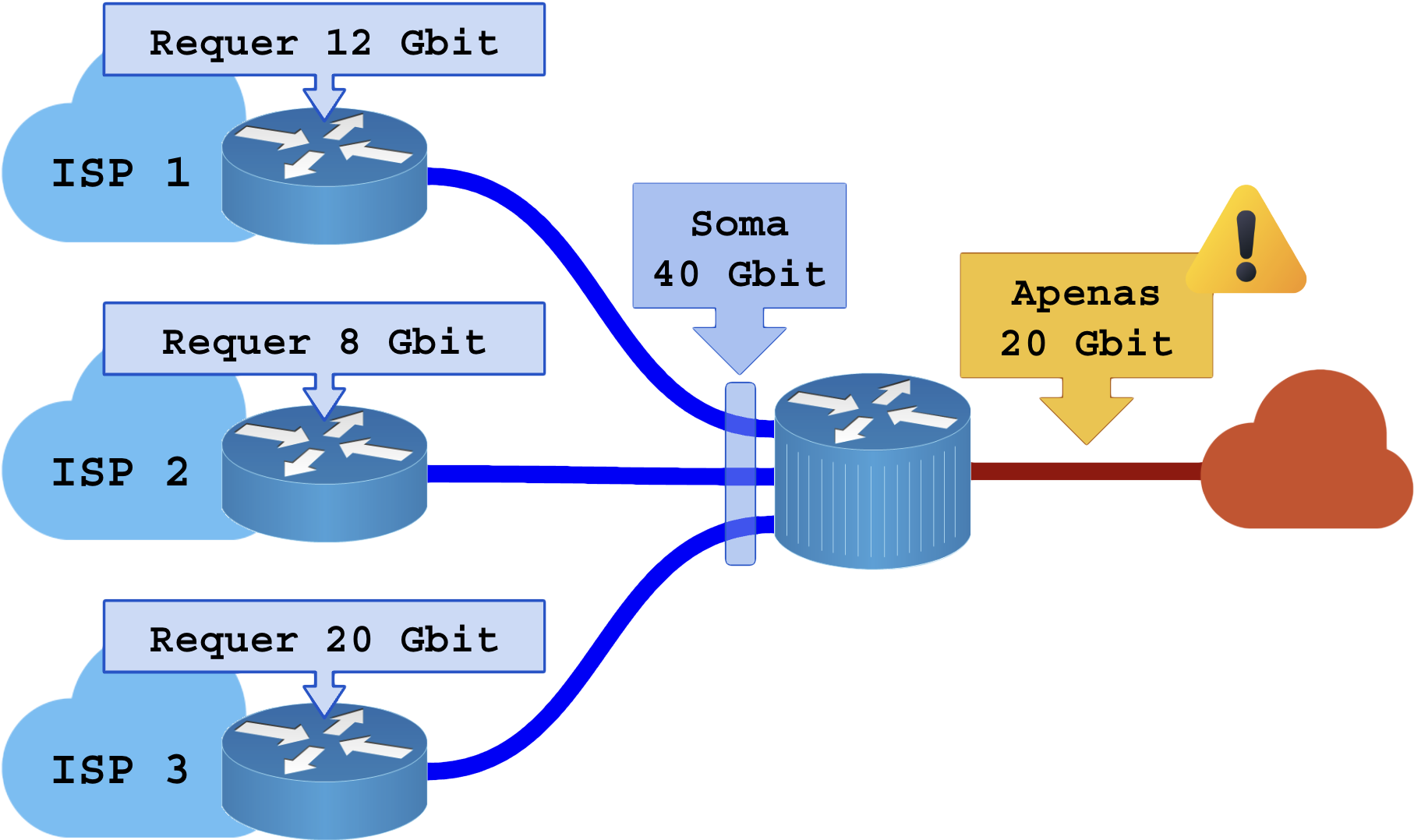
1.4 – Overcommit distribuído
A entrega dos recursos contratados é possível somando várias fontes de dados mas jamais por uma única fonte isolada.
Esse é o problema que deu origem ao termo IP PURO entre os provedores de Internet.
Observe o diagrama:
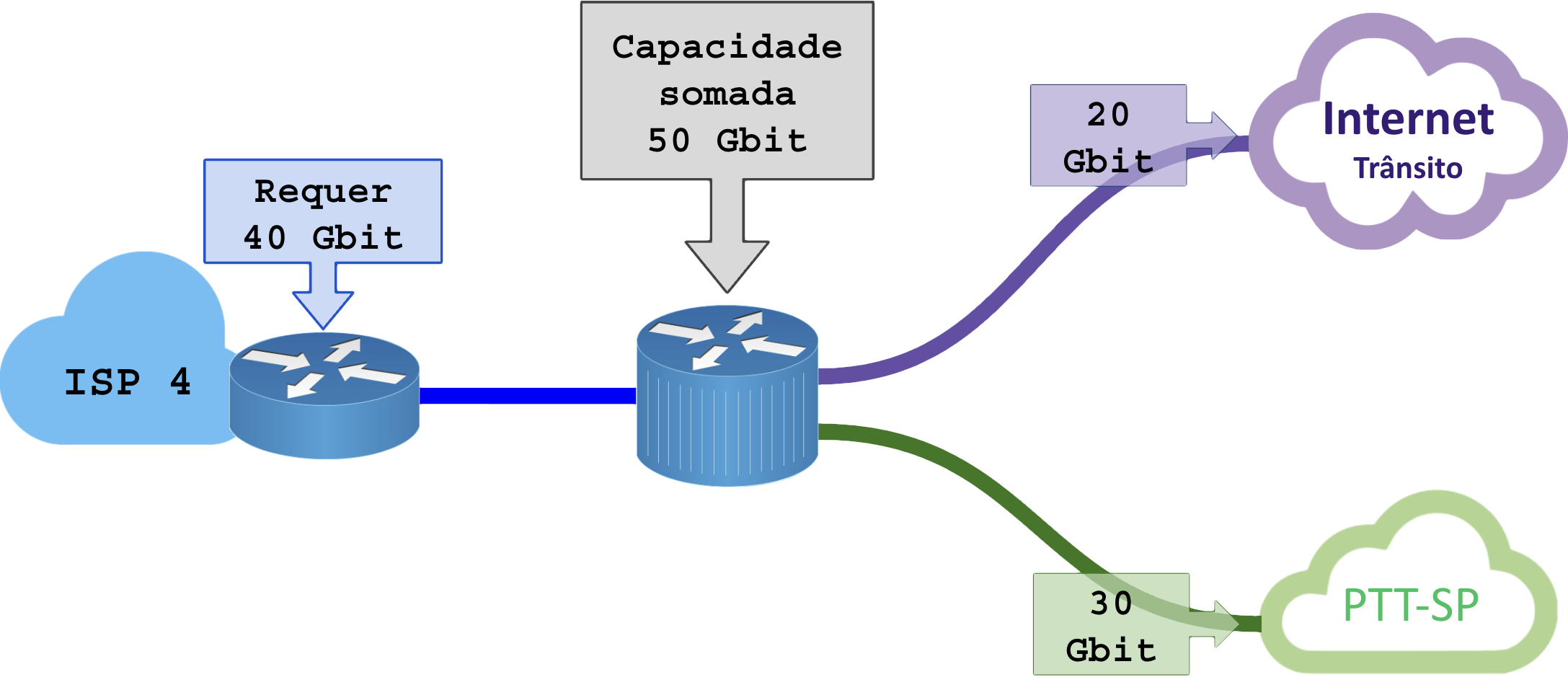
O fornecedor no meio tem capacidade (50 Gbit) para atender o cliente, considerando a engenharia de BGP para consumir mais o “PTT-SP” do que o “Trânsito BGP“.
Se a engenharia BGP falhar ou se o cliente pedir “quero apenas IP PURO”, ou seja, ser anunciado somente para o trânsito, não será possível entregar toda a banda contratada. Observe:
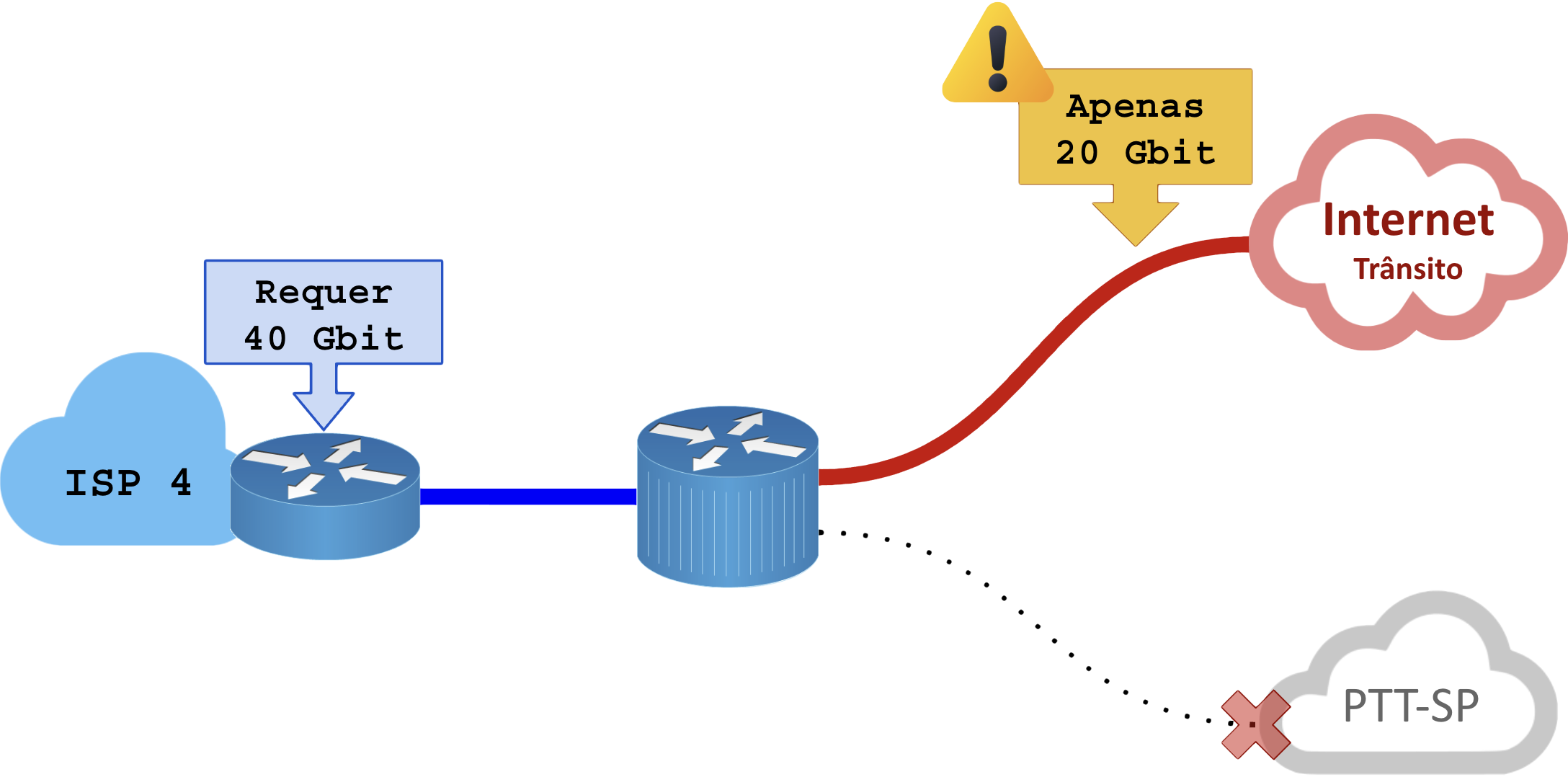
É financeiramente inviável para a operadora contratar a mesma capacidade de banda exclusiva vendida ao ISP cliente (40 Gbit) em todas as fontes de dados (40Gb livres no trânsito e 40Gb livres no PTT-SP).
1.5 – Perda de pacotes
Regra: A perda de pacote entre dois nós dependem da perda de pacote em todos os elementos pelo caminho.
Os elementos são:
- Camada 1 (física): Cabos com interferências, reflexões, sinal fraco, depreciação dos sensores de TX, corrupção dos emissores no TX, superaquecimento;
- Camada 2 (ethernet): Buffers cheios por excesso de banda (overcommit ou gargalo), QoS discriminando tráfego e sobrecarga do chip;
- Camada 3 (IP e roteamento): Filtros de firewall, flow-spec, incapacidade de rotear todos os pacotes em tempo real.
Observe:
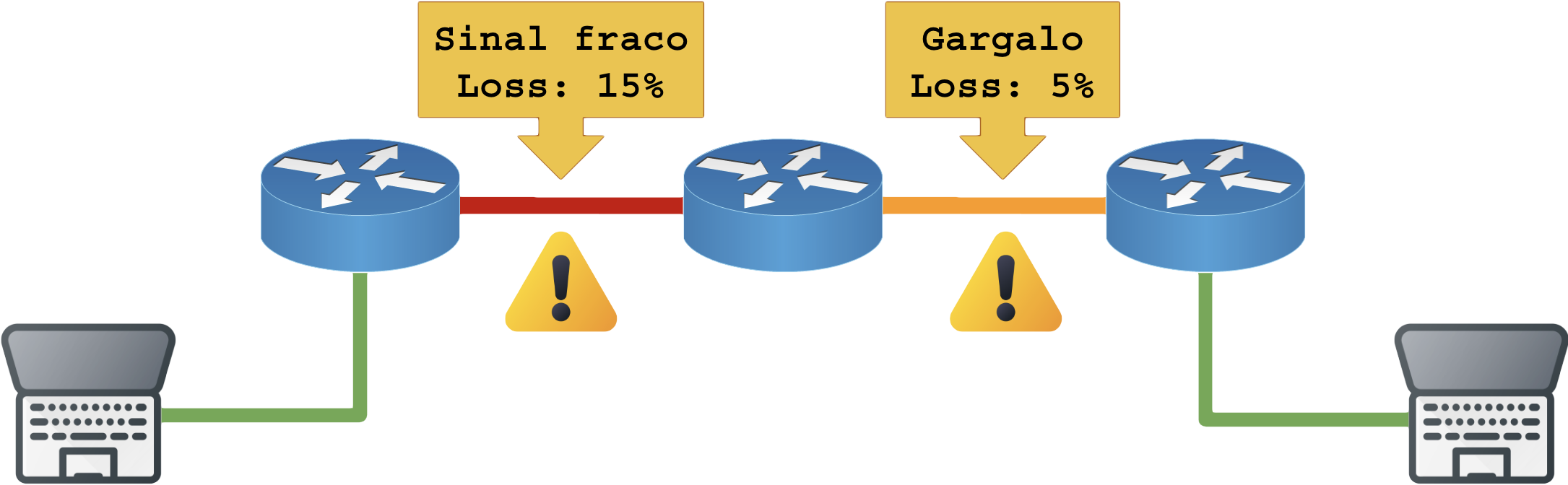
1.6 – Dispersão do fluxo
Regra: Quando vários fluxos competem pelo mesma passagem os pacotes do fluxo são distribuídos pelos slots de tempo disponíveis na camada 1.
Esse fenômeno acontece quando há muito overcommit ou muitos enlaces de frequência baixa (4 enlaces de 10Gb agregados são piores que um único enlace de 40 Gb).
Isso pode ser observado pelo aumento da diferença de tempo entre a recepção de cada pacote.
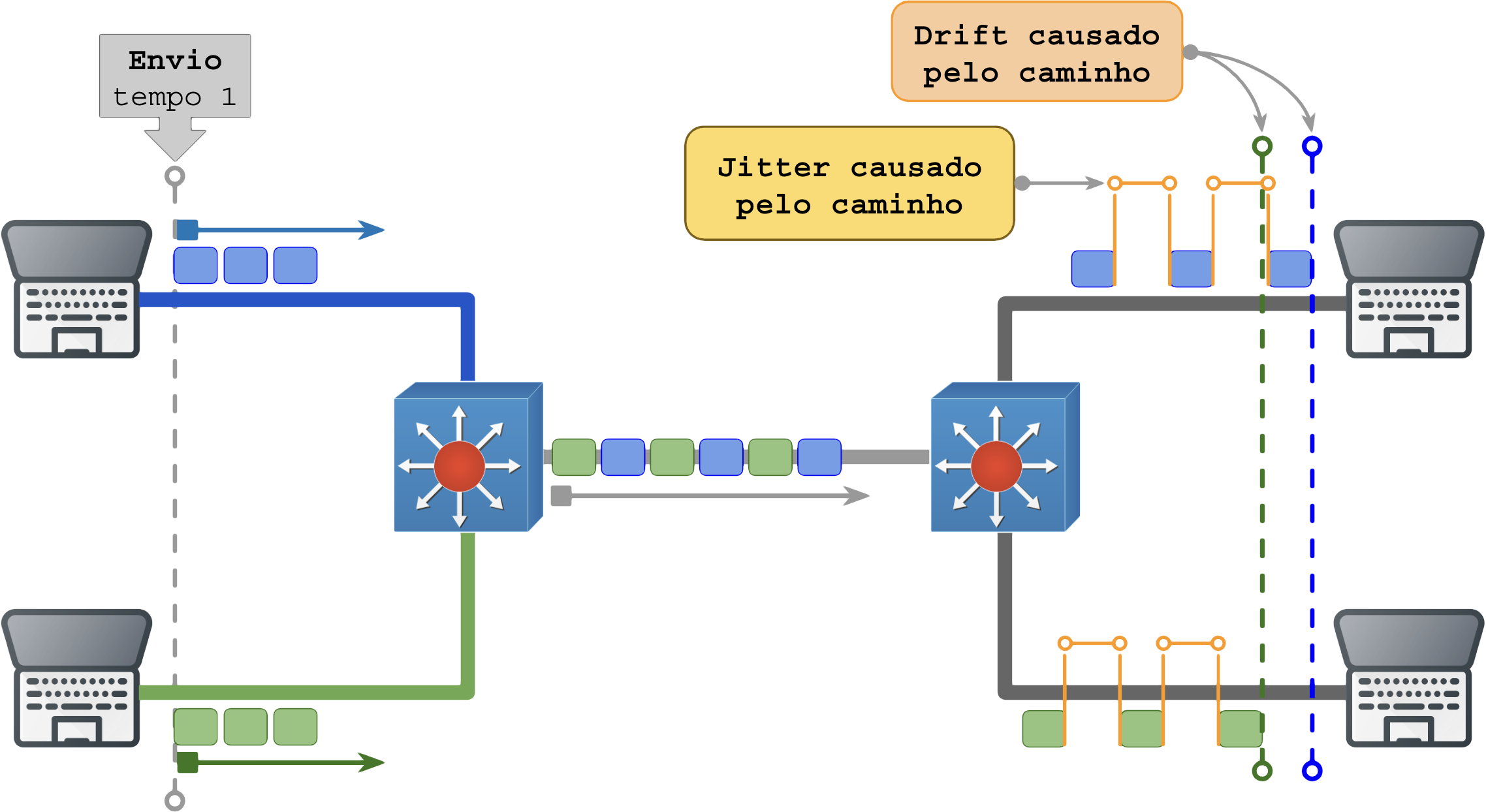
É um problema muito difícil de detectar pois requer registrar o tempo preciso (abaixo de microssegundo) em que o pacote é enviado (T1) e marcar o tempo preciso em que ele é recebido (T2) e comparar ambos.
Quando os equipamentos no caminho aplicam diferentes algoritmos de enfileiramento no buffer o padrão de atraso pode ser diferente e mais difícil de detectar, observe o diagrama abaixo:
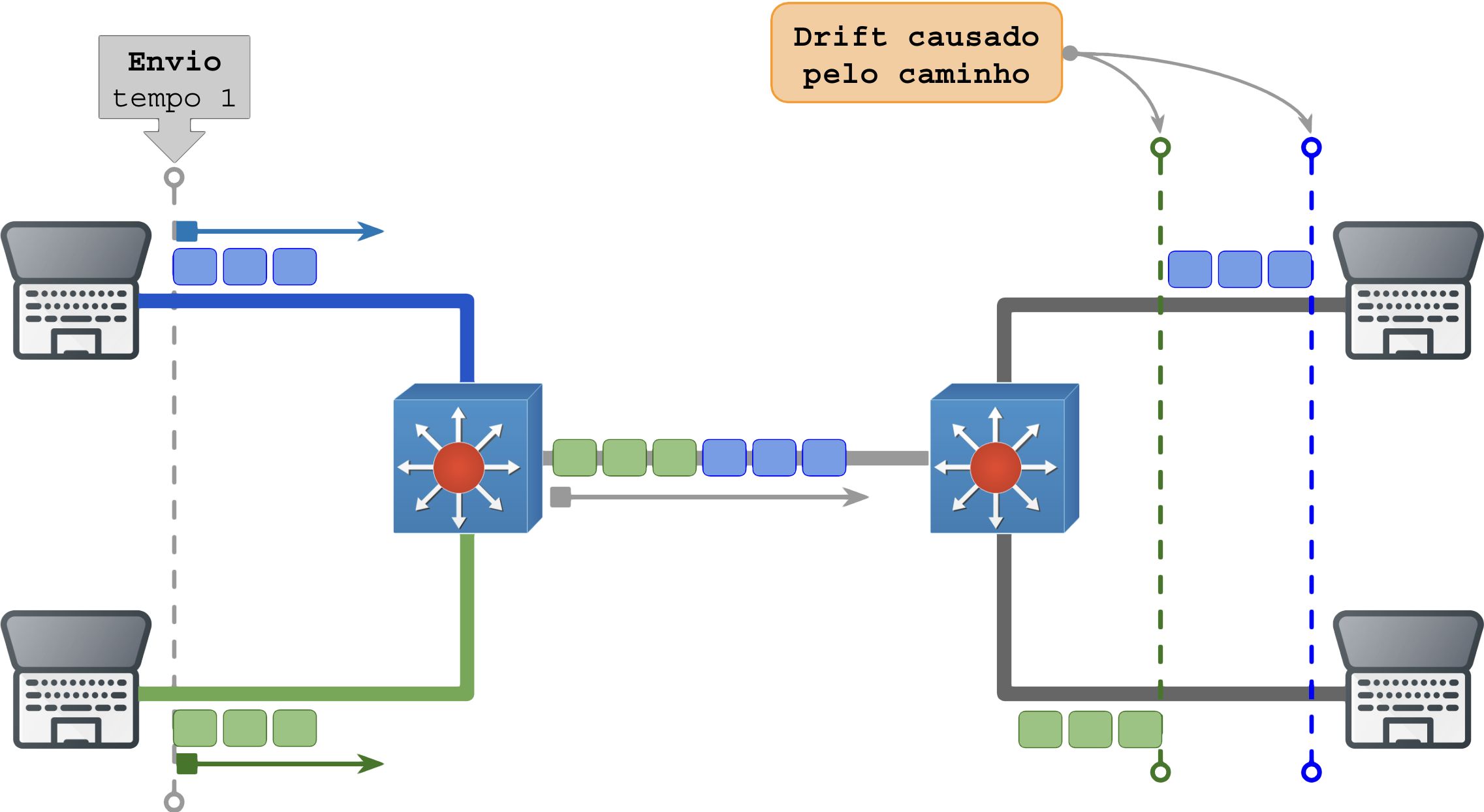
A dispersão do fluxo só pode ser resolvida com redução do overcommit, upgrade do uplink ou QoS.
1.7 – Micro-gargalos
Regra: A velocidade máxima de transmissão na camada 1 é determinada pela frequência com que um único quadro pode ser transmitido e não pela velocidade total no intervalo macro de 1 segundo.
Essa regra é mais dificil de explicar então vou abusar dos exemplos e desenhos!
Um enlace de 10 Gbit entre dois switchs pode transmitir, obviamente, 10 gigabits (10 bilhões de bits).

Se dividirmos ou multiplicarmos esse tempo, a quantidade de banda por unidade de tempo também será alterada mas o meio físico permanece o mesmo:
- 10 Gbit/s é o mesmo que 1 Gbit por um décimo de segundo;
- 10 Gbit/s é o mesmo que 100 Mbit por milésimo de segundo (1 ms, milissegundo);
- 10 Gbit/s é o mesmo que 10 Mbit a cada 100 milionésimos de segundo (100 us);
- 10 Gbit/s é o mesmo que 1 Mbit a cada 10 milionésimos de segundo (10 us);
- 10 Gbit/s é o mesmo que 100 Kbit a cada 1 milionésimo de segundo (1 us);
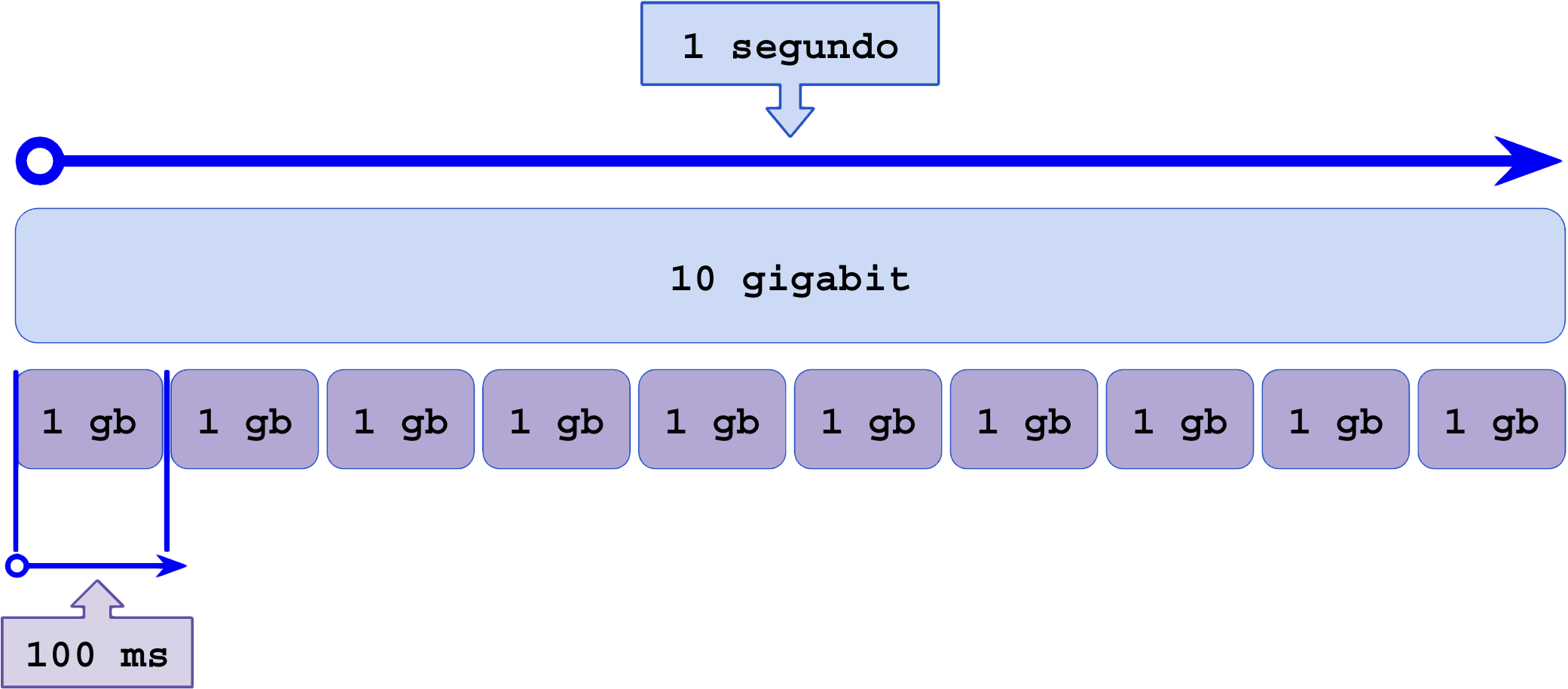
Agora vem o problema: A telemetria atual mede, quando bem, intervalos de 1 segundo. As medições por médias enxergam valores em intervalos considerados muito longos entre as coletas (1 segundo a 5 minutos).
Observe o erro da média de 4.8 Gb na janela de 15 segundos:
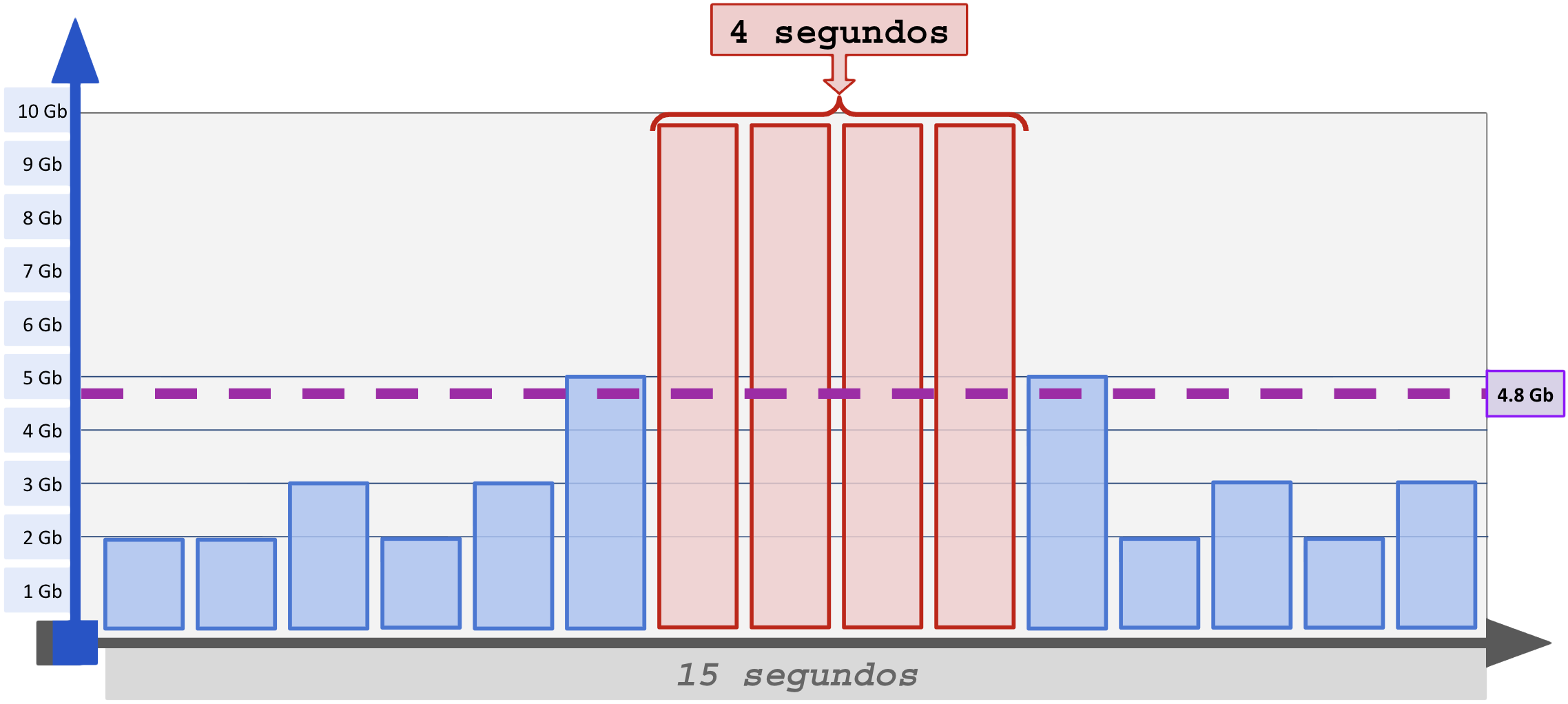
A solução seria medir segundo a segundo, mas observe agora dentro do intervalo de 1 segundo:
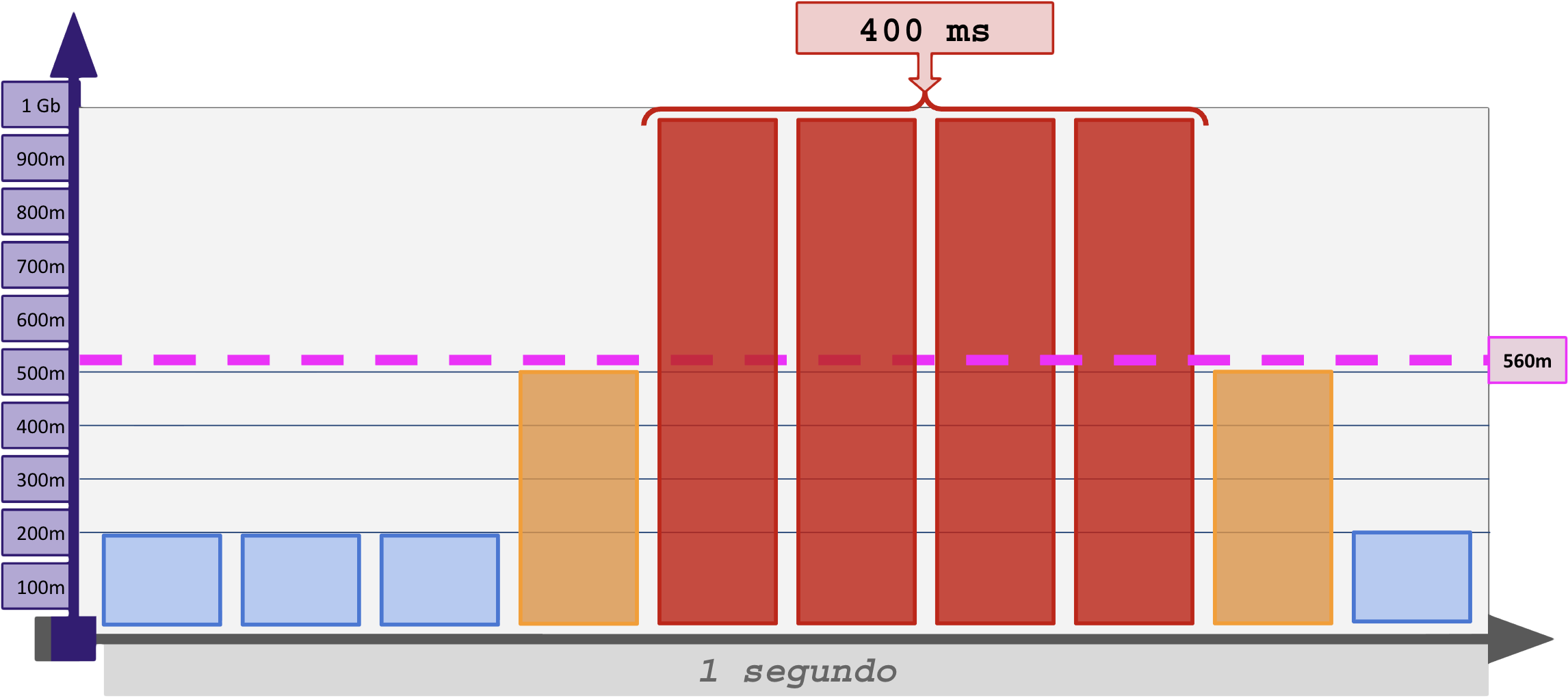
Agora pense na janela abaixo de 100ms em um enlace de 10 Gbit e vá descendo até o tempo de transmissão de um único quadro.
Os micro-gargalos são mais agressivos quando causados por pacotes pequenos que possuem overhead maior:
- Pacote IP: 48 bytes (384 bits);
- Quadro ethernet: 64 bytes (48+14);
- Sequência binária na camada 1: 64 + 20 (preâmbulo e SFD);
- Camada física: 84 bytes (672 bits).
- Pacote enviado com 384 bits ocupou 672 bits na camada 1.
- Overhead: 288 bits, quase o dobro do pacote transmitido.
Os micro-gargalos só podem ser resolvidos com redução do overcommit, upgrade de enlace ou QoS, o ideal é aumentar a frequência física (passar os canais físicos de 10 Gbit para 25 Gbit ou superior).
1.8 – Lane Striping
Quando usamos fibra ópticas (vou desconsiderar o uso de cabos TP/cobre), a velocidade da interface é definida pelo número de lanes (trilhas paralelas).
Interfaces de 10Gbit e 25Gbit são compostas por uma única lane, ou seja, a fibra óptica é utilizada como uma única pista de transmissão em série de bits.
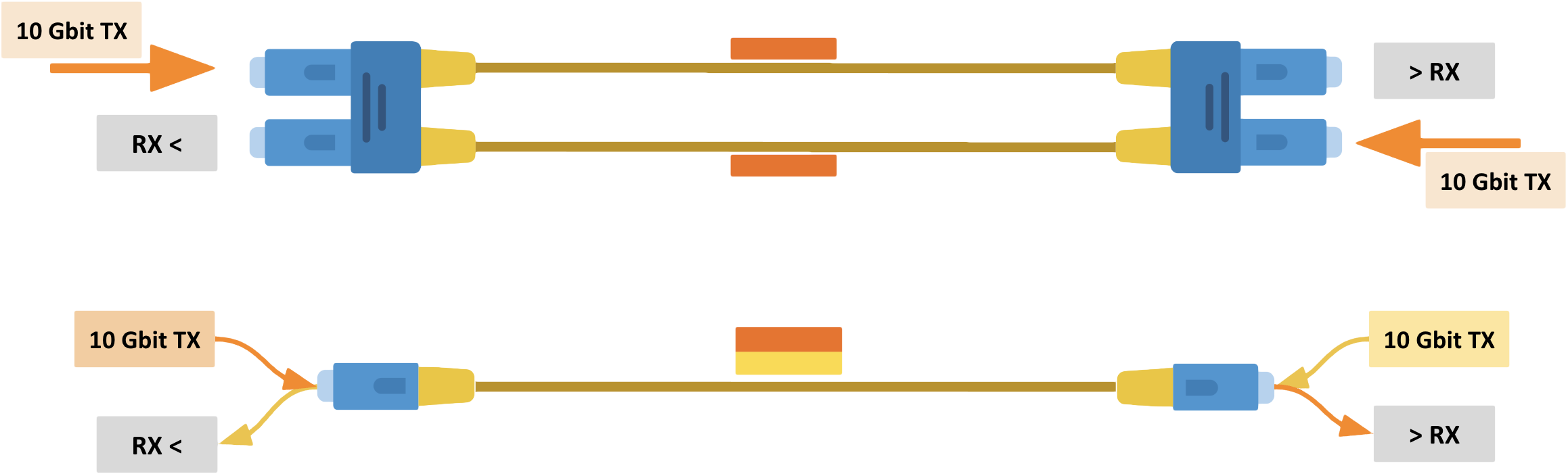
Já em interfaces de 40 Gbit ou superiores é inviável aumentar tanto a frequência dos pulsos luminosos pois isso reduz a distância entre os símbolos (pulsos) aumentando os problemas com interferências.
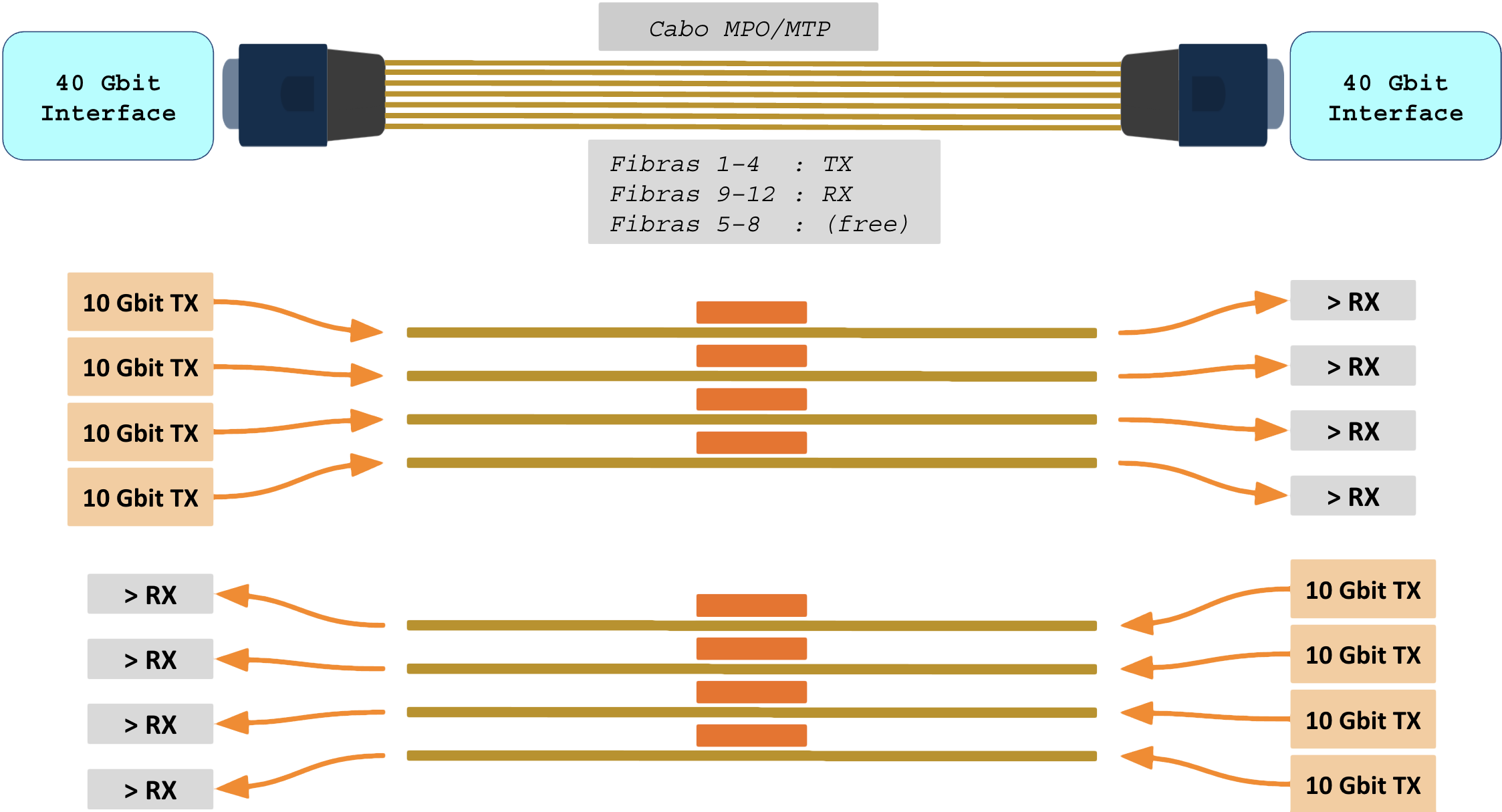
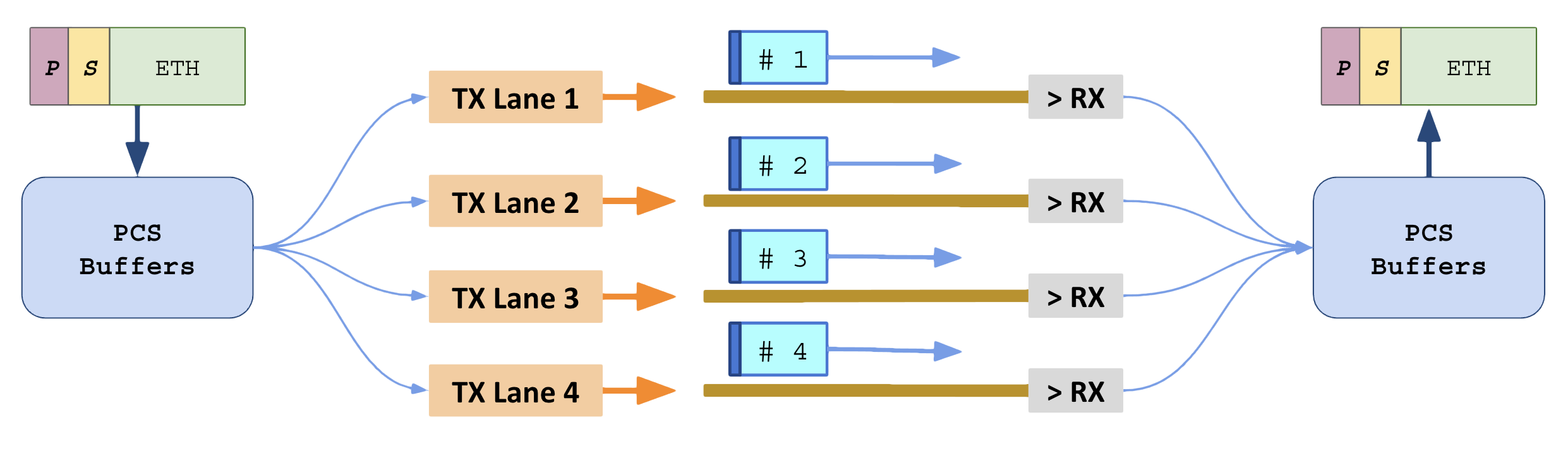
Lane striping: Atingir a banda total utilizando várias trilhas em paralelo. A divisão pode ser feita em várias fibras diferentes (mesma frequência em todas) ou usando WDM (mesma fibra mas sinais em frequências diferentes).
O quadro de camada 1 a ser transmitido é picado em pedaços de 64 bits na sub-camada PCS (Physical Coding Sublayer) e recebe adição de 2 bits para controle (Encoding 64b/66b), cada pedaço (bloco) é enviado em uma lane diferente usando distribuição Round-Robin.
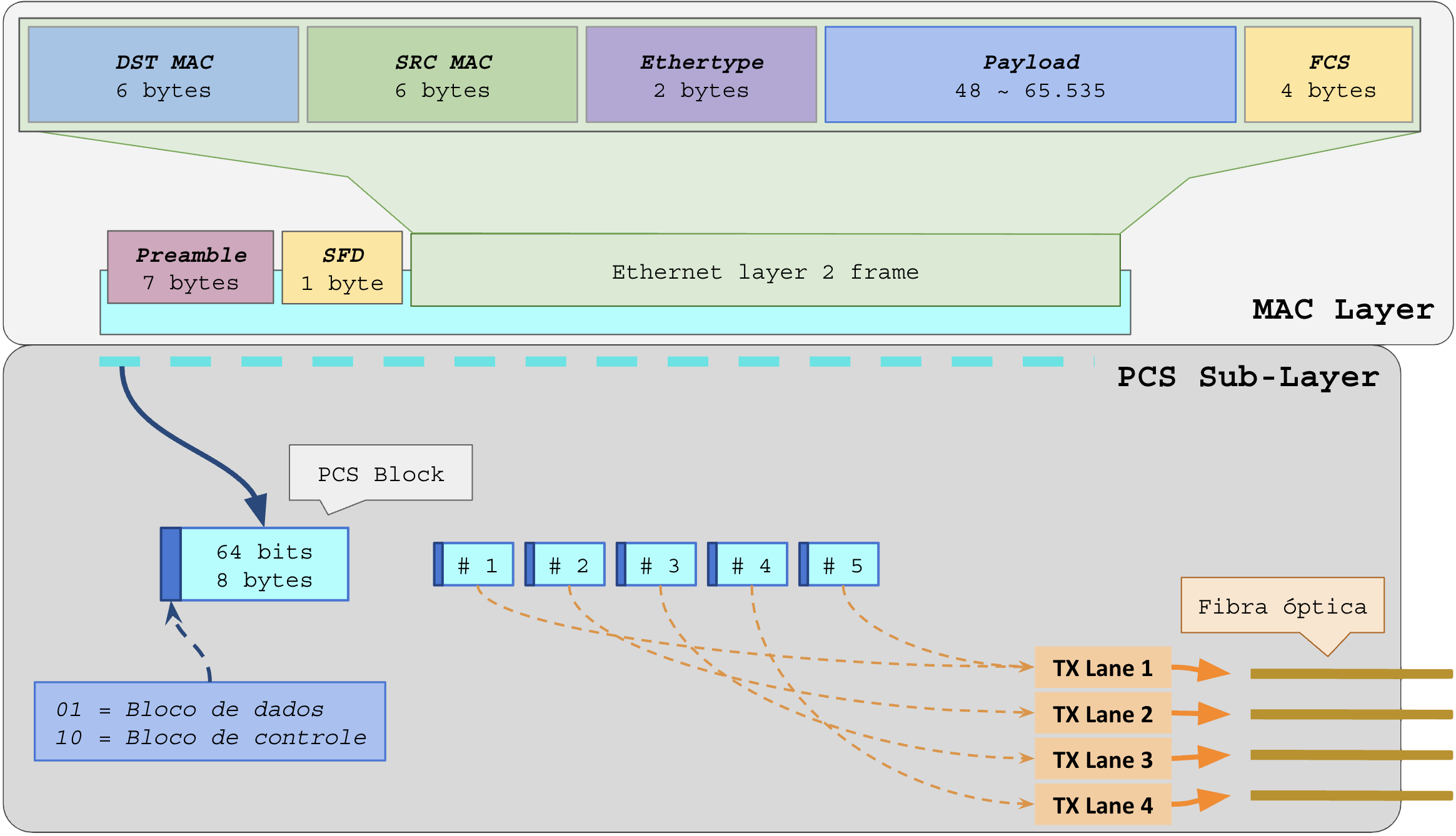
Com essa técnica é possível alcançar velocidades superiores a de uma única trilha.
1.9 – Skew – Assimetria de atraso entre lanes
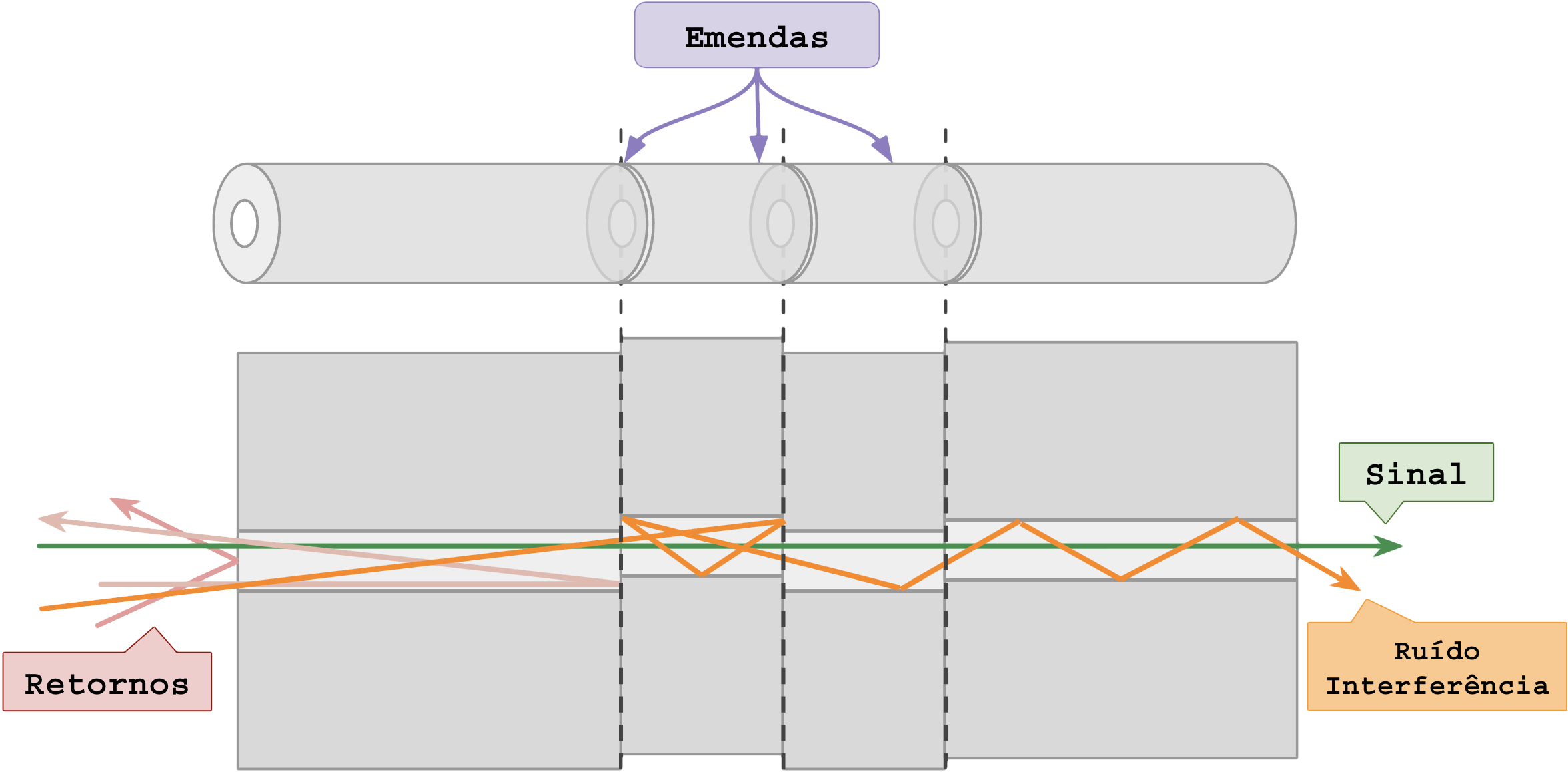
O problema de desalinhamento (skew) acontece quando o tamanho das fibras de cada lane são diferentes, sejam por tamanhos explicitamente diferentes, emendas, dilatação por calor, etc.
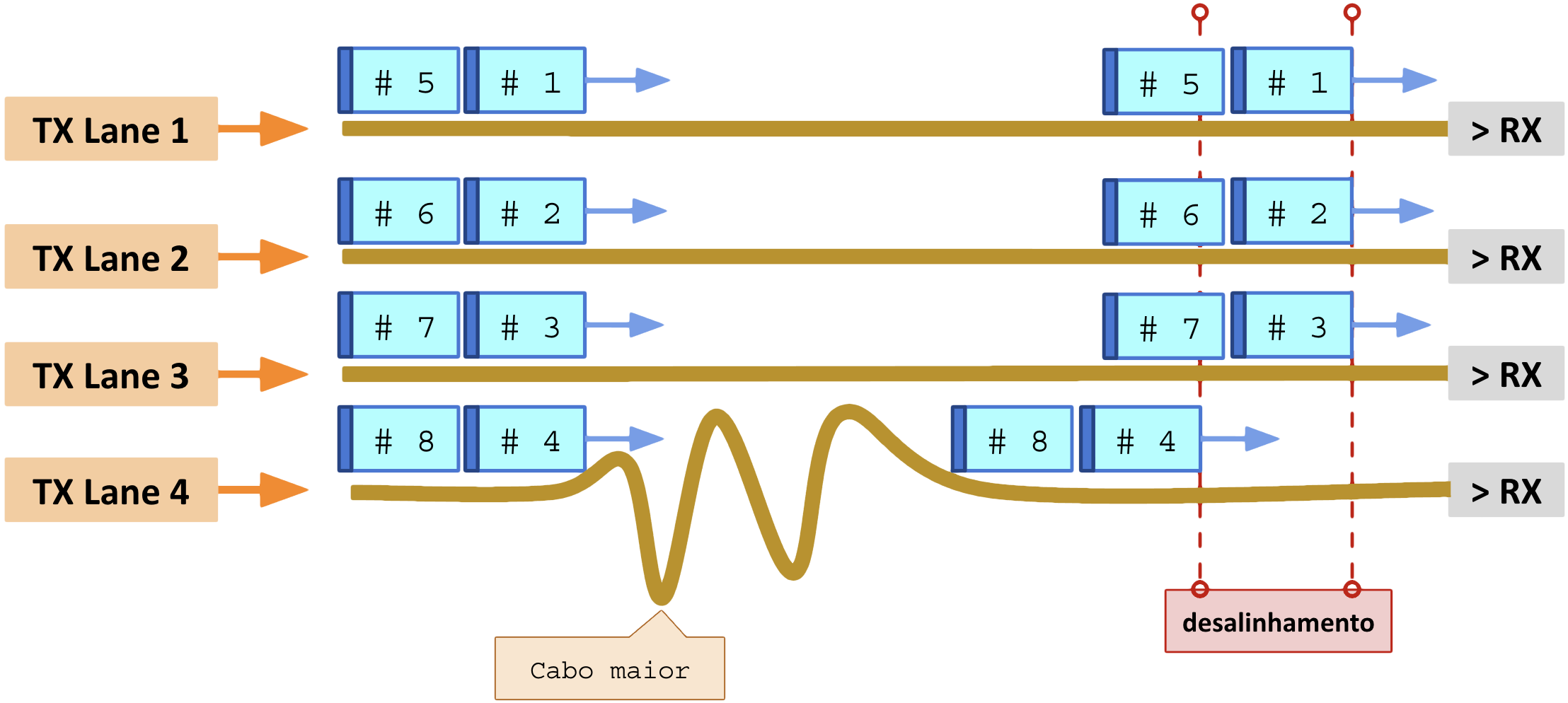
A camada PCS resolve o desalinhamento por meio de testes de controle (bit “10“). Blocos de dados são enviados para os buffers e blocos de controle são enviados para os circuitos que cuidam do alinhamento.
Procedimentos de controle:
- Detecta os marcadores (markers) em cada lane;
- Mede o atraso relativo (skew) entre elas;
- Usa buffers de realinhamento para sincronizá-las;
- Só então remonta os blocos na ordem correta, reconstruindo o quadro.
Você não pode ignorar o skew e deixar isso como “um problema que o PCS resolve“.
O realinhamento por buffers do PCS é projetado para resolver problemas que requerem precisão científica. Fazer com que todas as fibras tenham o mesmo tamanho com diferenças menores que micrômetros é impossível de aplicar em campo por pessoas comuns no dia-a-dia.
Exemplos de limites para o desalinhamento:
- Padrão 40GBASE-SR4 / 100GBASE-SR4: skew máximo de 100 nanosegundos;
- Padrão 400GBASE-SR8: skew máximo de 70 nanosegundos;
- Padrão 800GBASE-SR8: skew máximo de 30 nanosegundos;
Não vou detalhar mas esse tempo tem a ver com o slot time de cada técnica, é baseado no tempo de cada símbolo que transporta os bits e o tamanho do bloco PCS.
Resumindo o skew:
- Skew abaixo da metade do limite: o PCS resolve, ótimo;
- Skew na metade do limite: o PCS resolve, bom;
- Skew no limiar: Link instável, grave, instabilidade;
- Skew acima do limite: O enlace cai, offline.
1.10 – Imbalance – Atenuação diferencial entre fibras
Atenuação diferencial entre fibras (Lane power imbalance) ocorre quando cada fibra que faz parte do enlace possui potências diferentes chegando no RX (receptor).
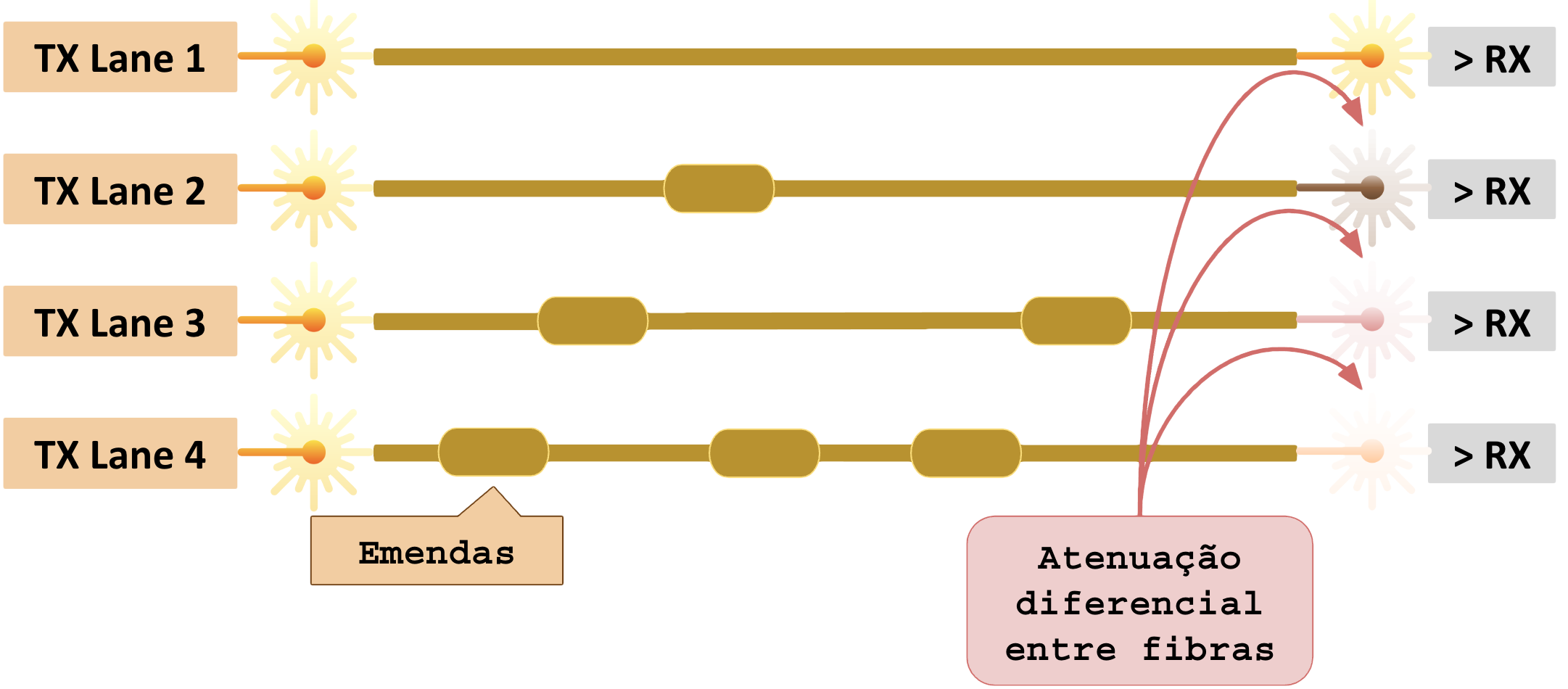
1.11 – Depreciações óptica
Existem inúmeras causas de depreciação dos bits pelo caminho que levam a corrupção do quadro por invalidação por CRC (checksum que verifica se todos os bits originais foram lidos corretamente no destino, consta nos últimos bytes do quadro).
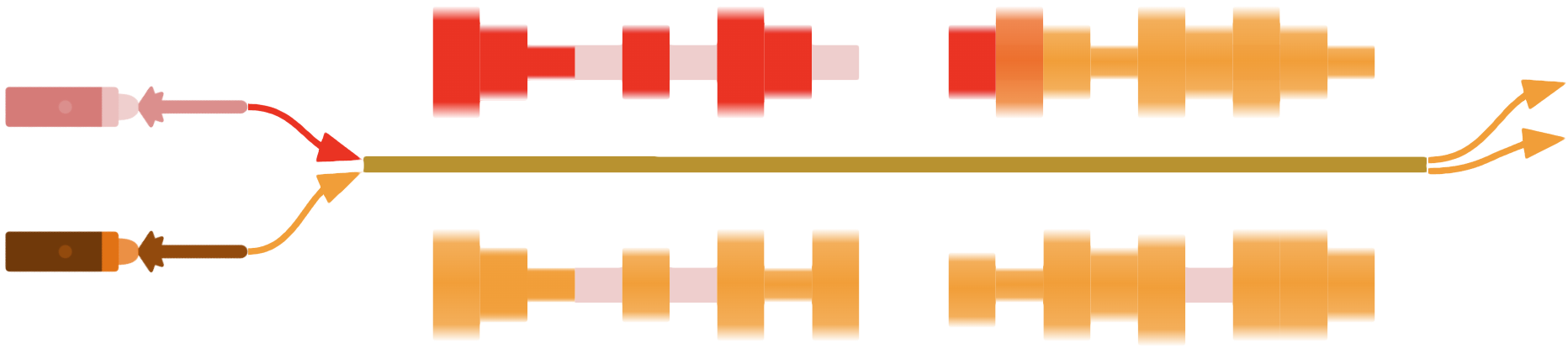
Dispersão modal (Modal Dispersion ou DMD – Differential Mode Delay): Quando a luz percorre múltiplos caminhos dentro do núcleo da fibra, reduzindo a nitidez entre os símbolos (sem pulso, pulso fraco, médio e forte) e misturando-os, alargando, tornando o sinal recebido no RX indistinguível ou impreciso.
Ocorre em relação à distância (quanto maior, pior) e é mais comum em fibra multi-modo (multi mode, MM).
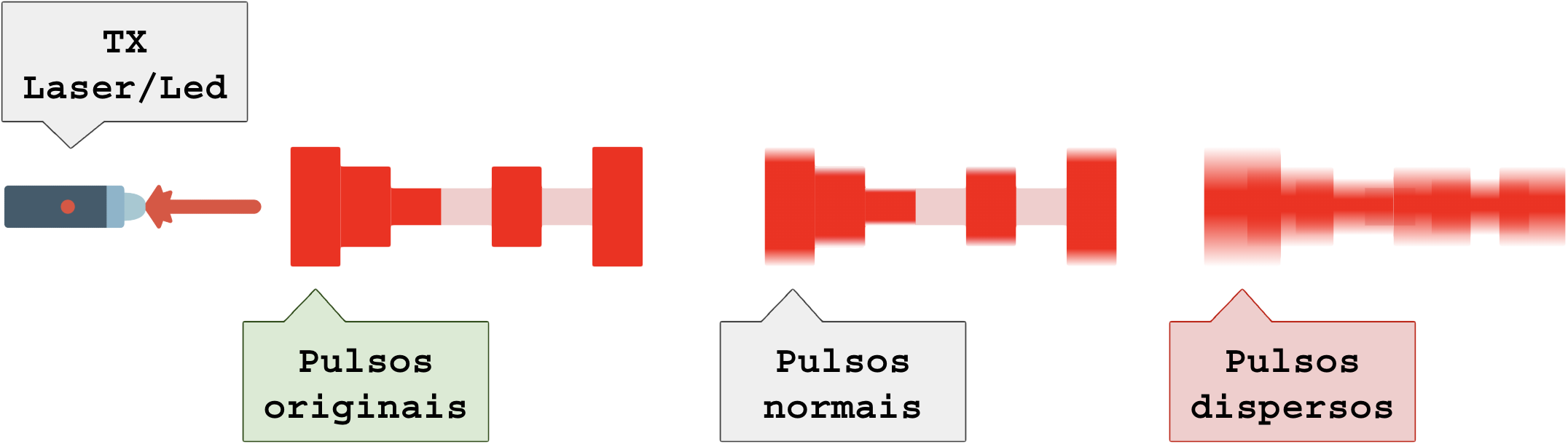
Dispersão cromática: Ocorre em distâncias longas (>10 km) quando o pulso se alarga na frequência ocupada. Diferentes comprimentos de onda dentro do espectro do laser viajam a velocidades ligeiramente diferentes, alargando o pulso e causando interferência entre símbolos.
Soluções:
- DSP com equalização: Transceivers PAM4 incluem um DSP que aplica equalização adaptativa (CTLE + DFE) para compensar a dispersão cromática eletricamente;
- DCF (Dispersion Compensating Fiber): Inserção de um segmento de fibra com dispersão negativa que cancela a dispersão acumulada no trecho principal;
- Modulação coerente com FEC: Em distâncias acima de 40 km, usar transceivers coerentes (DP-QPSK ou DP-16QAM) com DSP coerente que compensam a dispersão cromática e de polarização digitalmente.
Reflexões (ORL — Optical Return Loss): No conector ou emenda imperfeita, parte da luz retorna em direção ao transmissor, entram de volta no laser causando instabilidade no comprimento de onda, refletem novamente para a direção correta chegando atrasada e aumentando o ruído (RIN — Relative Intensity Noise).
1.12 – Store-and-forward
Os quadros e os pacotes fluem pelos equipamentos, obrigatoriamente, em camadas de transferências por meio de buffers. Um buffer é um pequeno espaço de memória ultra rápida, de tamanho limitado, que serve como ante-sala entre dois processos eletrônicos.
Didaticamente, é como uma sequencia de baldes furados alimentando uns aos outros, e o balde que encher perde agua sem prejudicar os demais.

Esse encadeamento de buffers se chama Store-and-forward (armazena e encaminha).
Essa técnica facilita o desenvolvimento e a integração entre tecnologias, entre chips de todos os elementos do equipamento (Data-plane ASIC/FPGA/DPU/CPU, módulos de interfaces, interfaces, transceivers, etc).
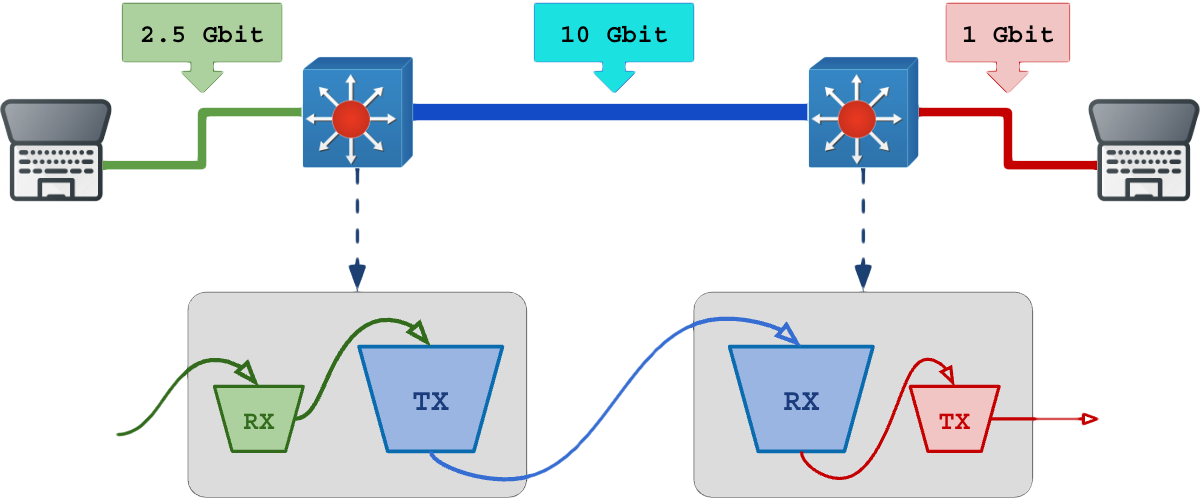
A velocidade de despejo do buffer na próxima saída é vital para evitar que o buffer transborde e cause a perda de quadros/pacotes.
São nos buffers onde os gargalos viram perda de pacotes. O tempo que o pacote fica no buffer é a indução de latência variável e jitter.
Transbordo de buffers de interface:
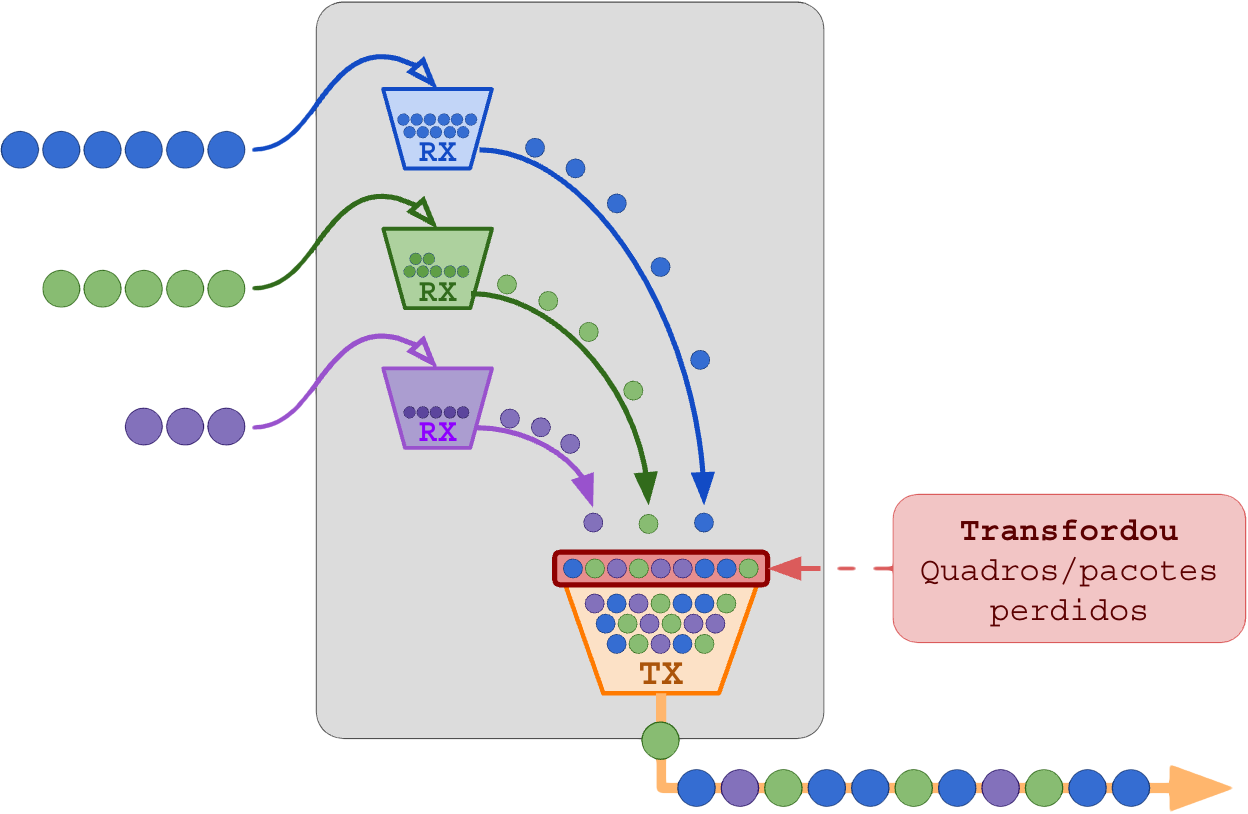
A separação entre os pacotes que antes estavam em série um após o outro também ocorre no buffer por conta da coleta e envio em meio a tantos fluxos misturados.
Localizações dos buffers:
- Buffers de interface: Buffers do protocolo Ethernet e suas camadas:
- Buffer de TX;
- Buffers PCS de divisão de blocos;
- Buffers PCS de remontagem de blocos;
- Buffer de RX;
- Buffers de QoS: Classifica os quadros e pacotes em filas por prioridade, a transferência entre buffers é realizado primeiro nas filas de maior prioridade até que sobre tempo e espaço para as filas de menor prioridade;
- Buffers de aplicação: Recebe e acumula pacotes que serão processados por protocolos específicos (contro-plane, CPU) como SSH, SNMP, ICMP, TCP, UDP, LLDP, CDP, etc.
1.13 – QoS – Qualidade de Serviço
O QoS (Quality of Service), qualidade de serviço, implementa buffers especiais ou coletores de buffers capazes de diferenciar tráfego antes de repassá-los para frente.
O QoS ajuda a priorizar tráfego importante em detrimento dos demais menos relevantes.
A primeira forma de implementar QoS é reduzir o overcommit, afinal, se você vendeu 100x mais banda do que tem capacidade de entregar, o QoS vai melhorar para alguns e piorar ainda mais para os outros.
Muitos fabricantes de chips (QoS em chip) e engenheiros de software preferem implementar por padrão uma fila de QoS chamada SFQ (Stochastic Fairness Queuing), ela garante uma participação justa no buffer, transbordando seletivamente o buffer: Quem envia muito perde muito, quem envia pouco perde pouco.
Cabe ao engenheiro de rede não apenas escolher o QoS, CoS e DSCP/Class padrões, mas declarar explicitamente quais clientes e tráfegos devem ser priorizados.
1.13 – CoS – Classe do serviço
O CoS cuida da classificação e priorização de tráfego na Camada 2 (Ethernet) e define como os quadros devem ser tratados pelos switches ao longo do caminho.
É normalmente aplicado no campo PCP (Priority Code Point) da tag 802.1Q (VLAN).
Na camada 3, os pacotes IPs que saltam entre roteadores e são priorizados pelo DSCP no campo DS Field (Differentiated Services Field) do IPv4 ou Traffic Class do IPv6.
Tabela PCP:
| Valor PCP | Prioridade | Uso típico |
|---|---|---|
| 7 | Crítica de rede | Protocolos de controle (STP, LACP) |
| 6 | Internetwork | OSPF, BGP |
| 5 | Voice | VoIP (voz sobre IP) |
| 4 | Video | Videoconferência |
| 3 | Critical Apps | ERP, bancos de dados, RADIUS, SSH, SNMP, SYSLOG |
| 2 | Excellent Effort | Tráfego priorizado para experiência do usuário (QoE) |
| 1 | Background | Backup e atualizações de software |
| 0 | Best Effort | Tráfego padrão |
A implementação de CoS é obrigatória em ambientes de backbone e datacenter. Pense o qual ridículo seria perder o monitoramento, telemetria e acesso remoto aos equipamentos durante um LOOP ou DDoS.
1.13 – QoE – Qualidade da Experiência
O QoE não é exatamente parte dos protocolos e da homologação. Ele é um principio de que tudo que da feedback psicológico ao usuário deve ser priorizado.
Exemplos do ponto de vista do usuário:
- WhatsApp e Instagram, VoIP, Meet: Se demorar para abrir ou reagir ao click, o usuário ficará irritado e terá a impressão que o serviço não presta.
- Windows Update, sincronismo de emails: O usuário nem sabe que existe, se ficar sem funcionar ou extremamente lento o usuário jamais saberá.
Tabela de QoE:
| Serviço | Prioridade | Uso típico |
|---|---|---|
| DNS | Crítico | Toda a interação depende dele |
| TCP 3way | Crítico | Necessário para abrir conexões antes de trocar dados |
| Ping | Crítico | Usuário leigo atormenta o suporte com testes ICMP |
| Voz | Crítico | Ligações não podem picotar ou serem cortadas e o protocolo deve escolher o codec com melhor nitidez de som (mais banda) |
| Video de feed | Importante | O usuário demora menos de 1 segundo para decidir se quer ver ou pular. Se demorar a abrir ou travar no meio ele se irrita muito. |
| Youtube, Netflix | Importante | Priorizar burst para carregar mais rápido a primeira parte, os próximos pedaços o aplicativo ajusta o download adiantado. |
| Resto | Irrelevante | Tudo que não dá feedback psicológico deve usar o que sobra da banda |
1.14 – Agregação de Portas
O LACP (IEEE 802.3ad) é uma técnica para unir várias interfaces em uma só.
Várias interfaces físicas são representadas como uma única interface virtual.
Ele é usado dois modos de operação:
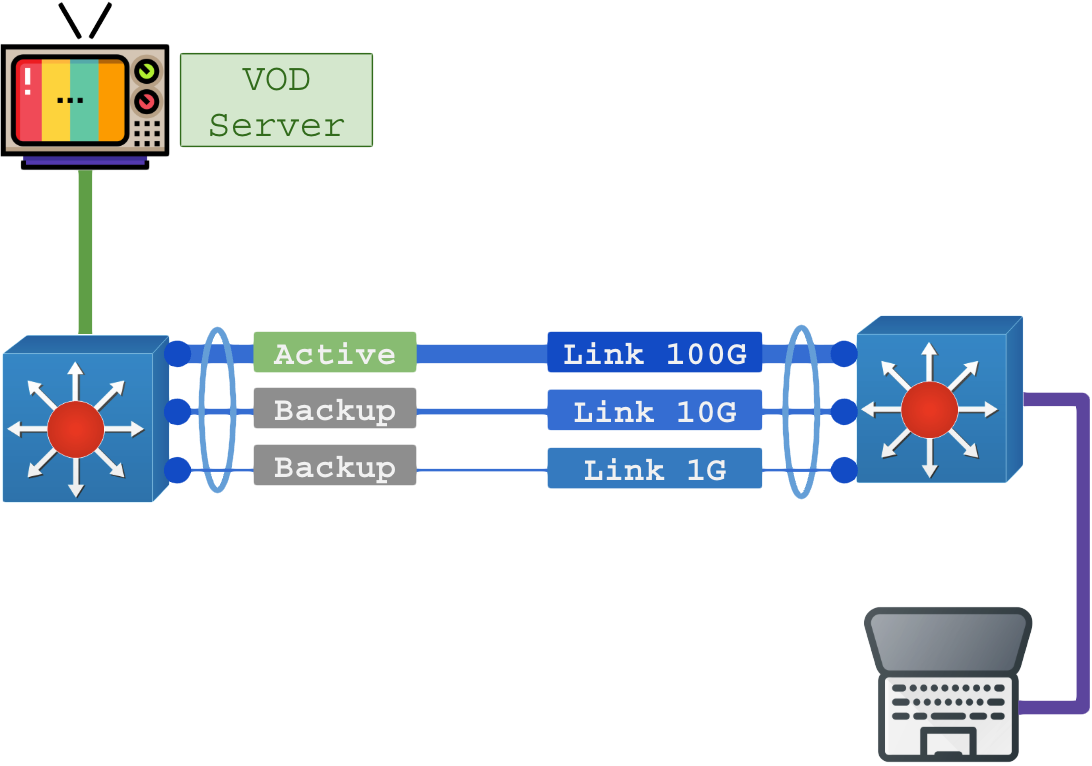
- Active/Backup: Uma porta opera ativa, as demais ficam em backup/stand-by aguardando a falha da primeira para assumir a responsabilidade pelo tráfego;
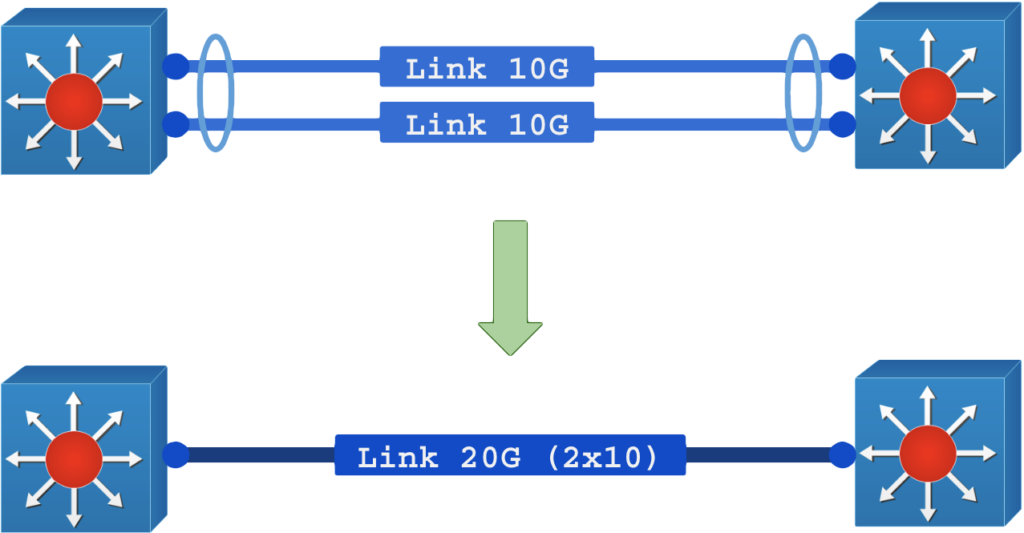
- Bonding: Unir as interfaces físicas para somar a capacidade, um pseudo-balanceamento.
No modo LACP Active/Backup o objetivo é manter o tráfego na interface com melhor qualidade e deixar as demais como garantia, exemplo:
No modo LACP Bonding o objetivo é somar recursos de várias interfaces com adicional de redundância caso uma delas fique offline.
Quando uma porta de 10 Gbit começa a atingir o limite preocupante de uso (acima de 70%) o correto é fazer o upgrade do enlace para 25 Gbit ou 40 Gbit. O LACP é uma maneira de adiar esse upgrade e sua proliferação revela um problema de orçamento e upgrades adiados.
Um truque corriqueiro é iniciar os enlaces de backbone já agregado com uma interface apenas, e adicionar mais interfaces no futuro (evita reconfigurações de IP).
No interior do equipamento, o LACP Bonding atua como um balanceador de distribuição do tráfego de entrada no buffer virtual para os buffers de TX das interfaces afiliadas.
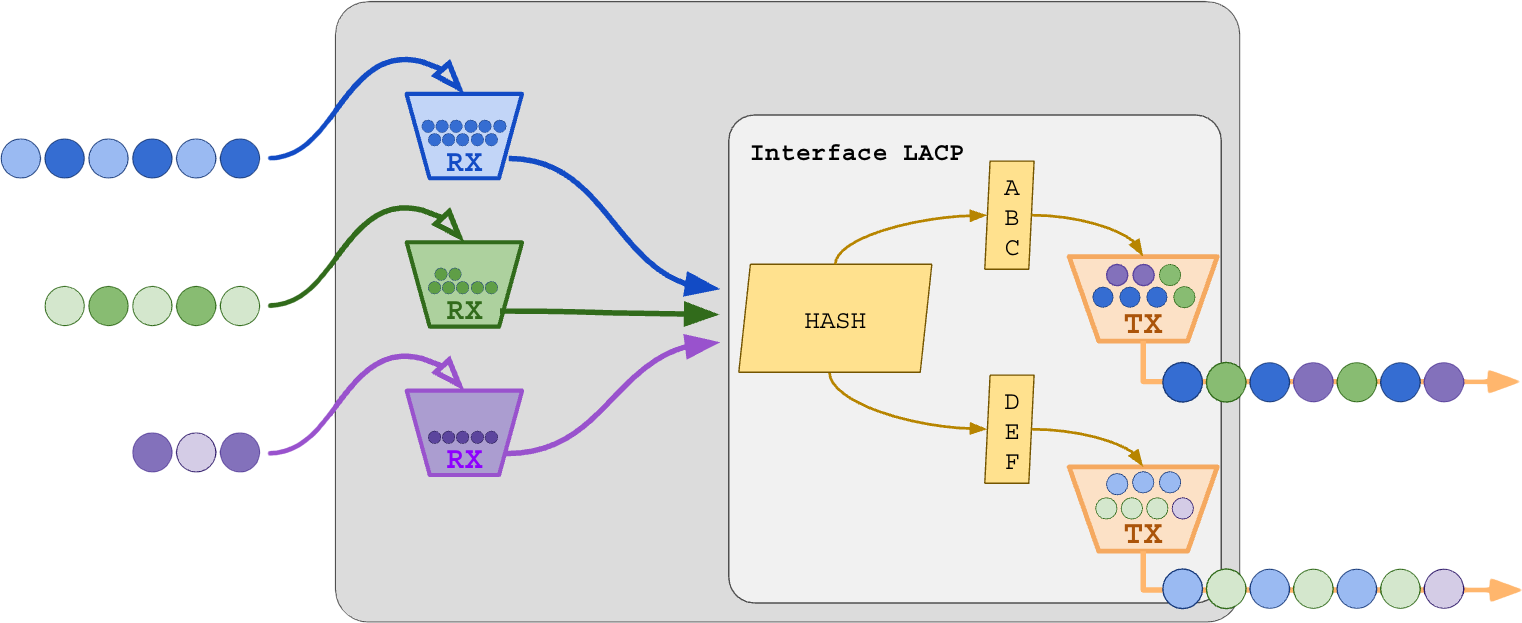
O LACP decide o buffer real de saída baseado no HASH realizado com os cabeçalhos do quadro. Não existe nenhuma operação do LACP no buffer de RX a não ser unificar o aprendizado de MACs na porta virtual.
Cabeçalhos comuns para cálculo do hash:
- MAC-SRC: Considera apenas o MAC de origem do quadro;
- MAC-DST: Considera apenas o MAC de destino do quadro;
- IP-SRC: Considera apenas o IP de origem;
- IP-DST: Considera apenas o IP de destino;
- L4-SRC-PORT: Considera a porta de origem do pacote/segmento;
- L4-DST-PORT: Considera a porta de destino do pacote/segmento;
- MPLS: Considera 1 ou vários labels MPLS;
Cada equipamento tem sua regra ou limitação. Nos melhores você pode combinar vários cabeçalhos para distribuir melhor os quadros.
1.15 – LACP Desbalanceado
Os problemas com o LACP começam quando uma interface física fica sobrecarregada e até topada e a outra (ou demais) ficam ociosas.
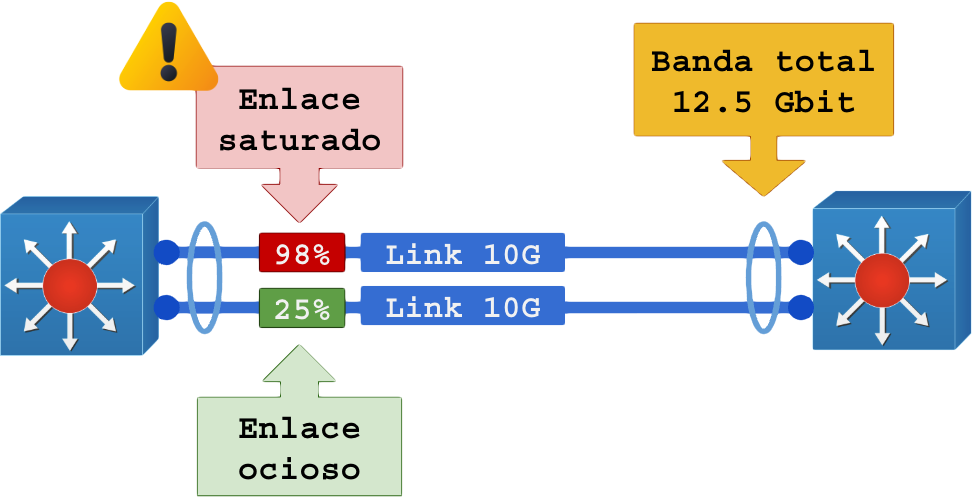
Esse problema acontece quando o HASH usado para distribuir o tráfego não analisa os cabeçalhos corretamente ou uma única conexão é responsável pela maior parte do tráfego.
Principais causadores:
- Circuito MPLS (L2VC/VPWS ou VSI/VPLS) transportando um túnel com muita banda;
- Solução 1: Adicionar label de entropia e adicionar a leitura de labels MPLS no HASH do LACP;
- Solução 2: Dividir em vários túneis MPLS (um para IPv4, outro para IPv6, …);
- Tráfego originado ou destinado a um mesmo IP (servidor CDN, servidor de backup) e o HASH não analisa as portas TCP/UDP para aumentar a distribuição;
- Solução: Adicionar leitura de L4 PORTS no HASH do LACP;
Minha estratégia: Criar várias versões de configuração de LACP (Profile) começando pela que lê o menor número de cabeçalhos e terminando na que lê muitos cabeçalhos ou todos, aplique uma a uma a cada 5 minutos até acertar a distribuição.
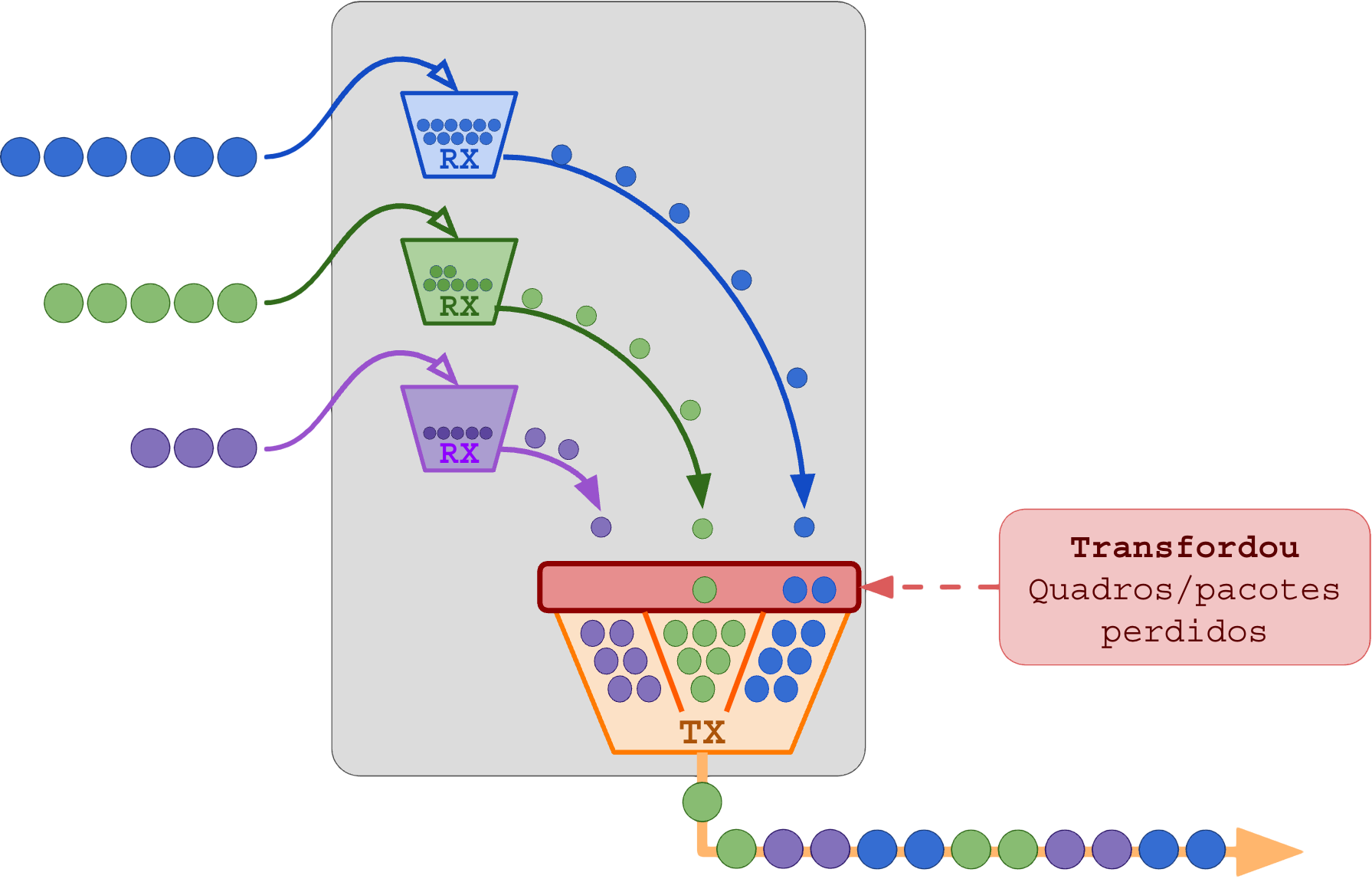
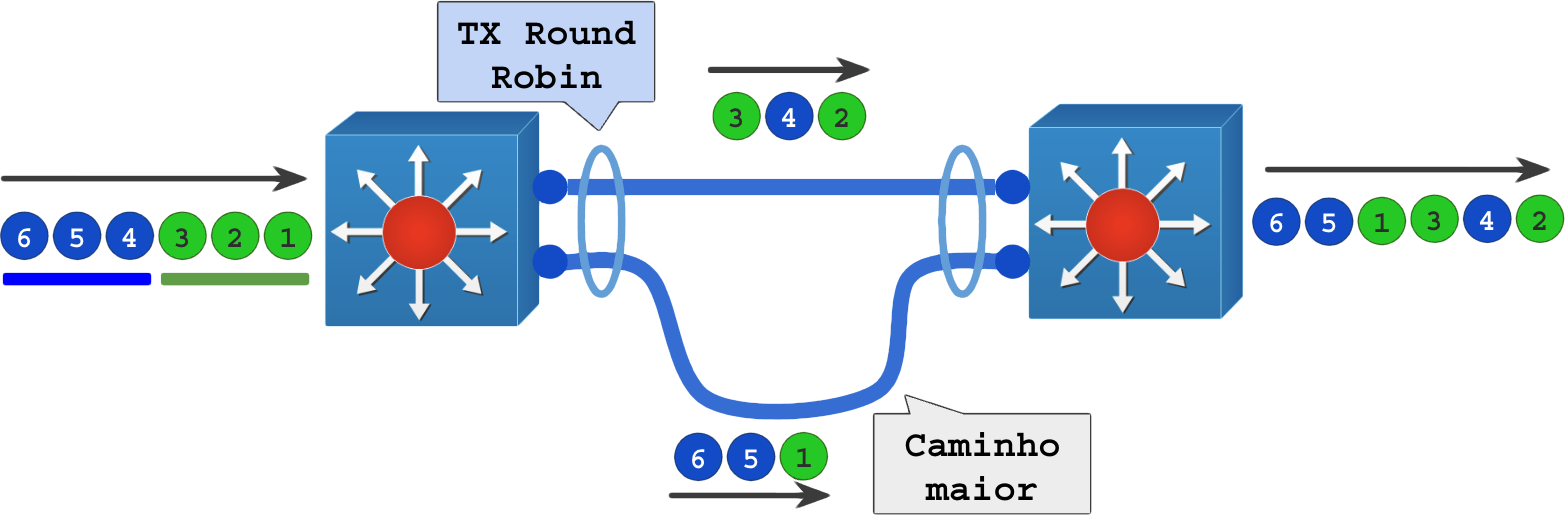
1.16 – Desordenação de Pacotes no LACP
A desordenação de pacotes é um problema grave que pode inviabilizar o uso da rede em vários protocolos mesmo sem apresentar indício de perda de pacotes ou latência alta.
Até redes perfeitas podem apresentar esse problema. Ocorre quando os pacotes saem da origem na ordem seqüencial e chegam no destino fora da ordem.
Ela é criada pelos enlaces que fazem uso de:
- LACP (bondings) na camada 2 com algum nível de aleatoriedade (Round-Robin);
- ECMP na camada 3 por custos iguais no OSPF/BGP que levam ao balanceamento dos pacotes entre esses caminhos;
- Soft-Routers: Roteadores que distribuem processamento em vários núcleos, um núcleo mais ocupado atrasa os pacotes delegados, retirando os atrasados da ordem;
Os primeiros pacotes fora da ordem induzem o TCP a concluir que houve perda de pacotes.
Exemplo em LACP com desordenação de quadros:
Esse problema pode ocorrer com mais gravidade e furtividade quando o LACP é realizado encima de transportes providos por terceiros:
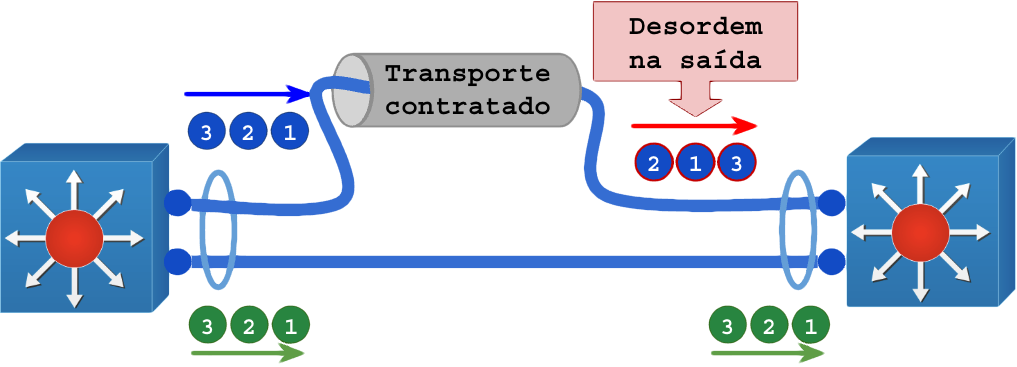
Pode ocorrer em relação a conexões diferentes: Um protocolo que faça duas sessões UDP paralelas podem enfrentar problemas quando cada uma delas recebe pacotes em ordens diferentes, pois esperam os pacotes em pares.
É um problema difícil de identificar e ainda mais difícil de resolver pois envolve retirar o balanceamento do caminho, algo que costuma exigir investimentos em upgrades.
Método de identificação:
- Um lado deve enviar pacotes com micro-timestamp (uTS) no payload, o receptor deve analisar se recebeu os pacotes dentro da regra: (UTS_ATUAL > UTS_ANTERIOR)
- A detecção pode ser feita desativando o offload TCP segmentation offload (TSO), Generic receive offload (GRO) e generic segmentation offload (GSO), capturando o tráfego durante os testes e analisando as capturas no Wireshark para identificar desordenação no recebimento.
1.17 – Desordenação de Pacotes no ECMP
Em uma rede L3 roteada por OSPF ou BGP, dois saltos de roteamento em interfaces diferentes podem ser computadas como tendo o mesmo custo final e a rota é adicionada com 2 ou mais gateways e o tráfego é balanceado. Isso é muito perigoso para a ordem dos pacotes.
O OSPF (ECMP padrão automático) é o principal causador desse problema e raramente acontece em BGP (requer configuração explicita).
A maioria dos casos é muito obvio e até proposital em enlaces duplos diretos de um roteador no outro:
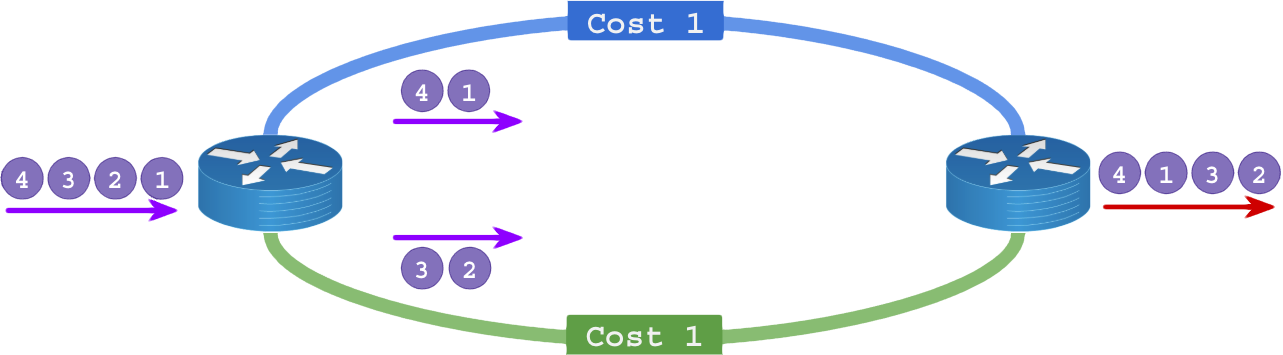
De forma oculta isso ocorre quando há custos iguais por caminhos diferentes em rede com vários roteadores:
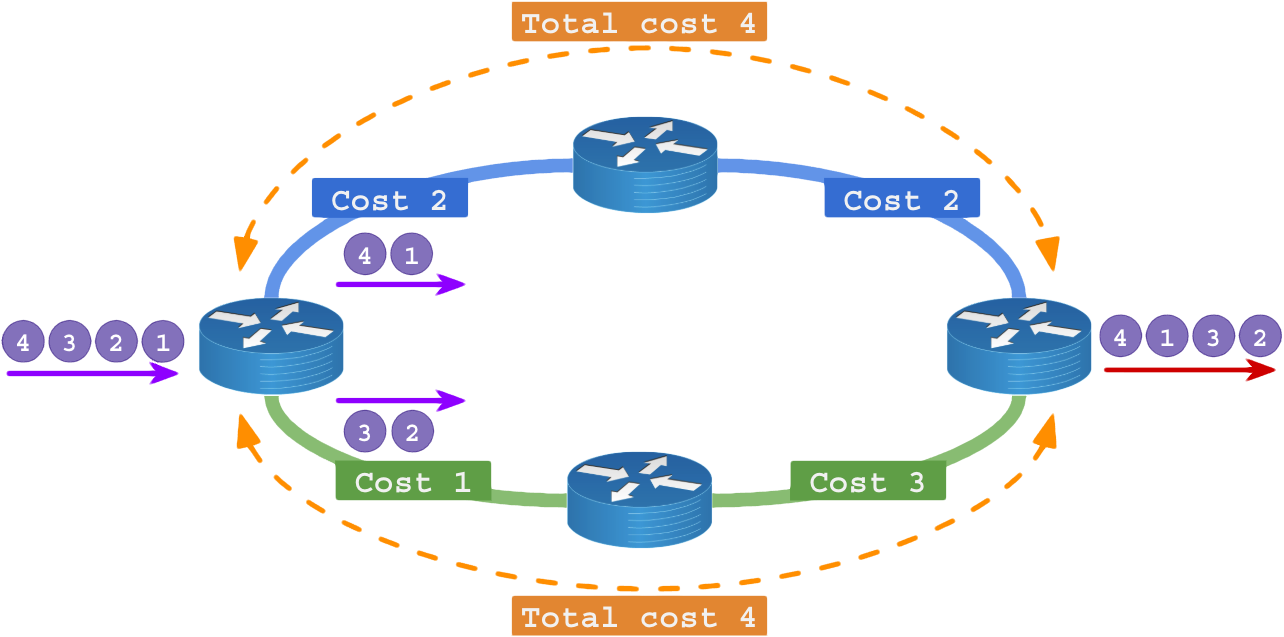
Se a rede crescer muito o ECMP pode ocorrer de maneira totalmente imprevisível entre diferentes pontos da rede:
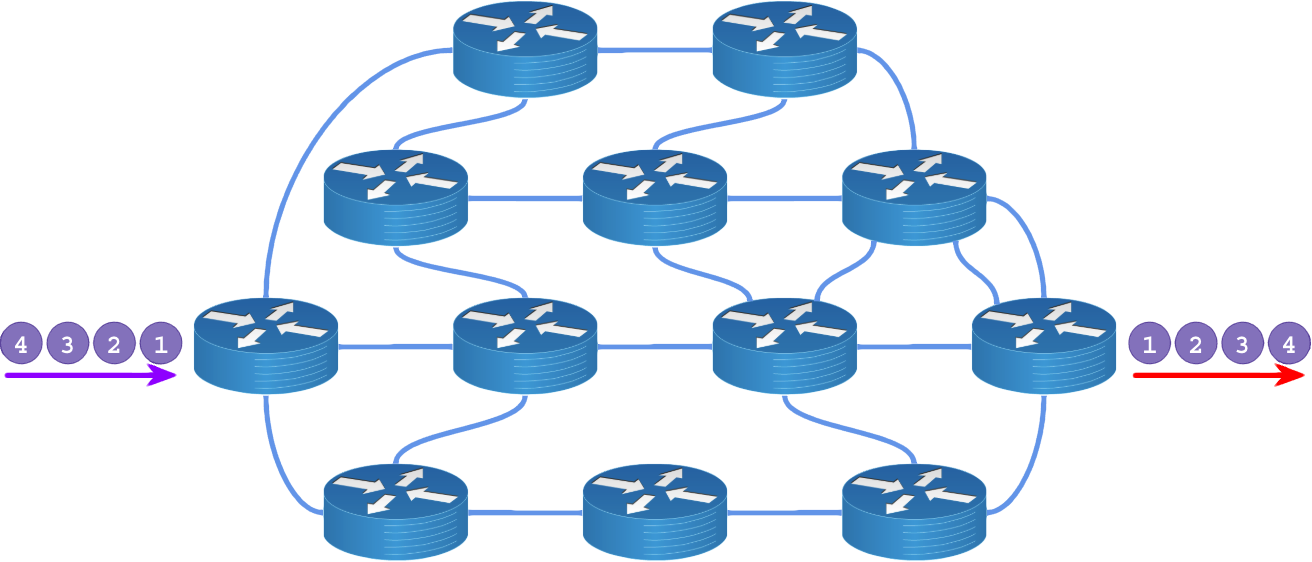
Para resolver esse problema, deve-se criar uma tabela de custos baseado na largura de banda com valores acima de 100 e todos os enlaces que empatam na largura de banda devem ser desempatados pela distância do cabo/fibra.
Com a ordem crescente por banda seguido da distância, cada valor empatado recebe um número primo (1,2,3,5,7,11,13,17,…). Os números primos não podem ser repetidos nos outros desempates.
| Banda | Distância | Custo padrão | Custo final com n. primo |
|---|---|---|---|
| 10 Gbit | 5 KM | 880 | (880+1) = 881 |
| 10 Gbit | 5 KM | 880 | (880+2) = 882 |
| 10 Gbit | 7 KM | 880 | (880+3) = 883 |
| 10 Gbit | 8 KM | 880 | (880+5) = 885 |
| 40 Gbit | 22 KM | 440 | (440+7) = 447 |
| 40 Gbit | 43 KM | 440 | (440+11) = 451 |
| 100 Gbit | 150 metros | 100 | (100+13) = 113 |
| 100 Gbit | 202 metros | 100 | (100+17) = 117 |
Quando um novo enlace entra no meio da tabela, tente dar um valor temporário até refazer os custos de toda a rede (infelizmente é necessário).
2 – Homologando a camada 1
No capítulo 1 abordamos os conceitos que impactam diretamente na qualidade de uma rede.
A camada 1 é responsável pelo transportes dos bits no espaço que existe entre as duas pontas de todo cabo ou fibra óptica.
Você não pode, nem terá sucesso, se tentar resolver por software (update, comando ou configuração) um problema que é de hardware. Não existe comando que faz espirito subir em poste e emendar uma fibra rompida, nem comando que faz gordura na ponta de conector desaparecer.
2.1 – Problemas óbvios
Causas prováveis de problemas repetitivos na camada 1:
- Transceiver (GBIC):
- Emissor (TX): Sujeita na fibra, led/laser com problemas, potência manipulada, gestão de potência ruim, super aquecimento;
- Conector: O mais barato de resolver. Reflexão de entrada, sujeira nos contatos, má fabricação;
- Sensor receptor (RX): Depreciação e insensibilidade, super aquecimento.
- Fibra óptica: Cortes ou emendas mal feitas, atenuações, reflexões nas emendas, emendas mecânicas, fibra velha ou muito fraturada (núcleo e casca comprometidos), chaveamento óptico.
Ações para resolver problemas:
- Troque: Sempre troque os transceivers, cabos curtos e conectores. Essa tarefa é básica e rápida e resolve a maioria dos problemas. Depois de trocar investigue nas peças retiradas qual é o defeito especifico para evitá-lo;
- Contorne: Se há vários cabos e fibras disponíveis no caminho, troque a que vocês está usando por outra e veja se resolve.
2.2 – Certificando a fibra óptica
Existem três equipamentos principais para analise ativa de uma fibra óptica:
- Microscópio Digital
- OLTS – Optical Loss Test Set
- OTDR – Optical Time Domain Reflectometer
Gráfico básico de analise de fibra com OTDR:
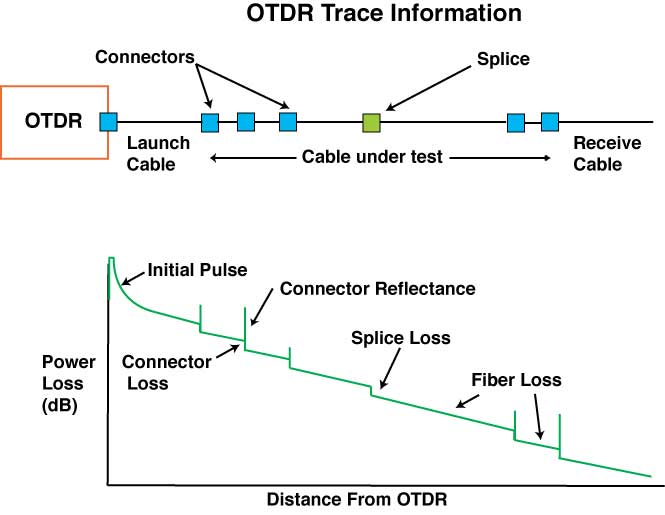
O OTDR deve estar devidamente calibrado, atualizado e certificado como equipamento antes de certificar enlaces.
Ao testar e certificar uma fibra, emita o documento de certificação no próprio OTRD e arquive-o no chamado para que haja prova técnica.
Todas as evidências produzidas com microscópio, OLTS e OTRD devem ser arquivadas com a data/hora, operador e identificação da fibra analisada.
3 – Homologando a camada 2
A camada 2 envolve todos os elementos de rede que possuem algum tipo de chip que manipula, processa, encaminha ou lida com emissão e recepção de sinais que darão forma ao quadro ethernet.
Elementos da camada 2 (ethernet IEEE 802.3):
- Transceivers: Adaptadores SFP, QFP e semelhantes que possuem lasers ou leds emissores (TX) e sensores receptores (RX);
- Portas: Qualquer porta ethernet onde podemos ligar um transceiver ou cabo TP;
- Switchs: Equipamentos dedicados ao processamentos de quadros ethernet mas que não lidam com roteamento IP;
- Switchs L3: Equipamentos capazes de realizar todas as operações dos switchs e possuem capacidades de roteamento IP (IPv4, IPv6 e MPLS);
Não vou abordar nada do mundo wireless pois não participam nem podem colaborar com homologações de redes de fibra óptica (na verdade só atrasam nossa vida).
3.2 – Equipamentos de teste
Realizar testes com emissão de quadros e pacotes requer que o equipamento que emite e detecta esse tráfego tenha capacidade e precisão.
Isso requer processadores específicos e precisão para medir tempos discretos (abaixo de micro-segundos), algo que em sistemas Windows e Linux é bem complicado de conseguir.
Ter um equipamento capaz de testar 1 Gbit/s a 10 Gbit/s é basicamente uma obrigação para médias e grandes empresas, as pequenas devem ter acesso ao aluguel para usar sob-demanda.
Os testadores para bandas acima de 10 Gbit/s (25 Gbit, 40 Gbit, 100 Gbit) são consideravelmente caros e raramente utilizados e devem ficar restritos ao aluguel mesmo, a menos que estejamos falando de uma operadora ou grande provedor.

Existem vários equipamentos para esse fim, todos devem ser aprendidos em cursos do fabricante.
É particularmente humilhante usá-los ou ser vítima deles. Eles encontram erros e não perdoam nenhum detalhe. Fazê-los parar de apontar erros pode ser meio impossível se a rede é feita a base de gambiarras.
Para ficar claro: Nenhum teste de camada 2 deve ser realizado onde a camada 1 não foi finamente corrigida.
3.3 – Testes do padrão RFC 2544
A primeiro padrão de testes é definido na RFC 2544 — Benchmarking Methodology for Network Interconnect Devices.
Conceitos:
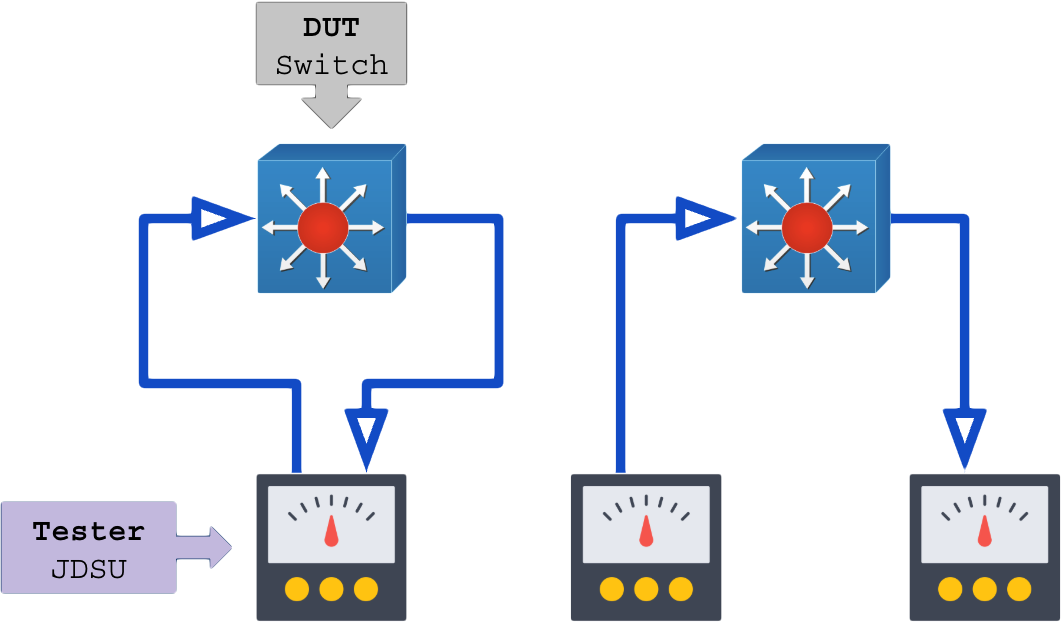
- DUT (Device Under Test): Equipamento a ser testado (alvo);
- Tester: Equipamento que emite os dados e coleta do outro lado, responsável por submeter o DUT à carga.
Testes:
- Camada 2: IP unicast, multicast, broadcast (1%), CDP, LLDP, etc;
- Camada 3: IPv4 e IPv6;
- Camada 4: UDP, TCP, ICMP, …;
- Firewall: Sem firewall, com firewall, com diferentes quantidades de regras (até 25);
- Throughput (Vazão): Banda passante máxima na qual nenhum pacote é perdido. O teste aumenta o volume até encontrar o limite (perdas começam a acontecer);
- Latência: Tempo que um pacote leva para atravessar o DUT, medido em diferentes volumes de banda, do primeiro ao último bit enviado.
- Taxa de Perda de Quadros: Percentual de quadros que não são transmitidos pelo DUT em condições de sobrecarga;
- Rajadas: Número máximo de pacotes consecutivos que o DUT consegue processar sem perdas (teste de buffers);
3.4 – Topologias para teste
O testador (tester) e o DUT (equipamento testado) devem ser explorados porta a porta, transceiver por transceiver e cabo por cabo até a exaustão.
Depois de estressado o equipamento isoladamente, o teste deve evoluir para analisar os conjuntos em série:
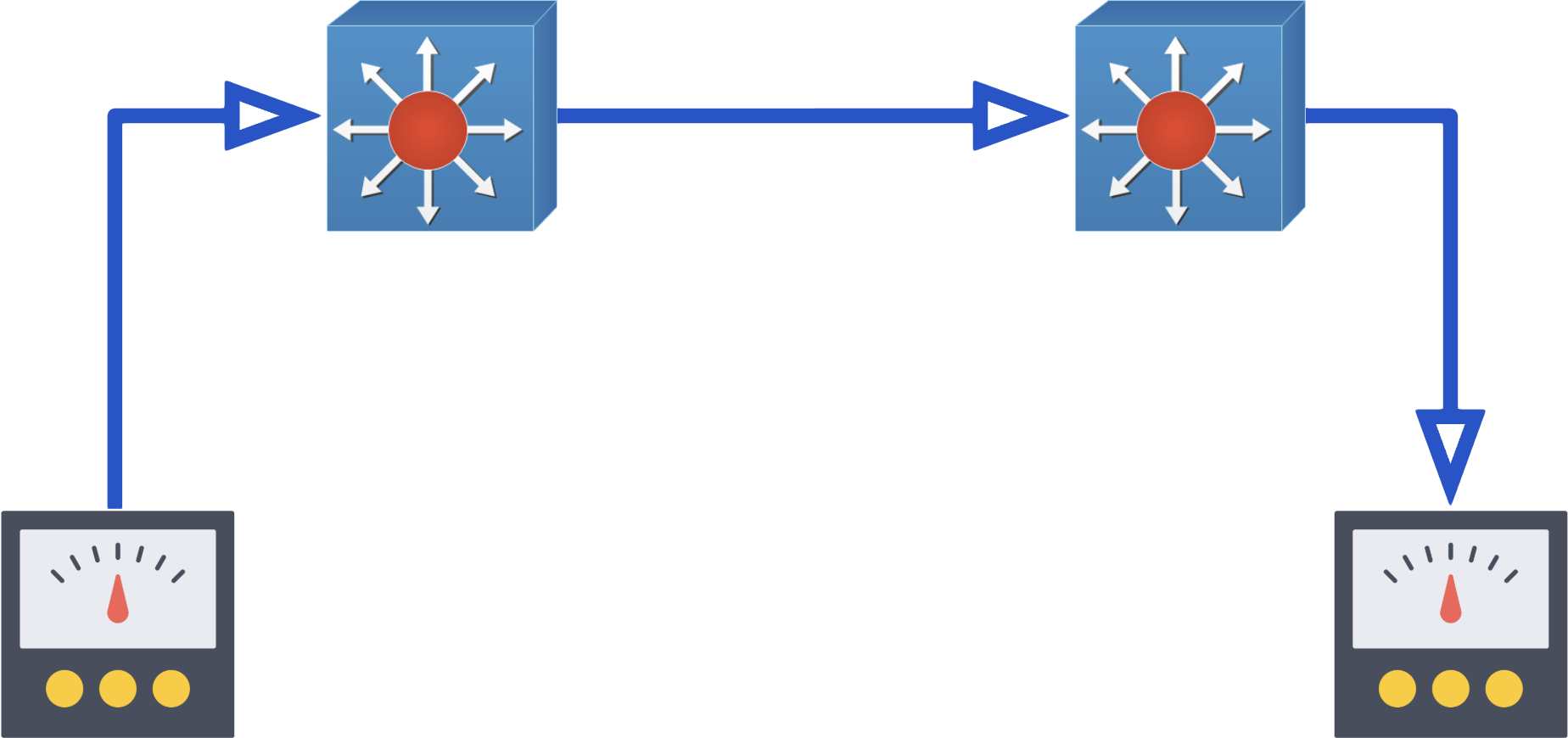
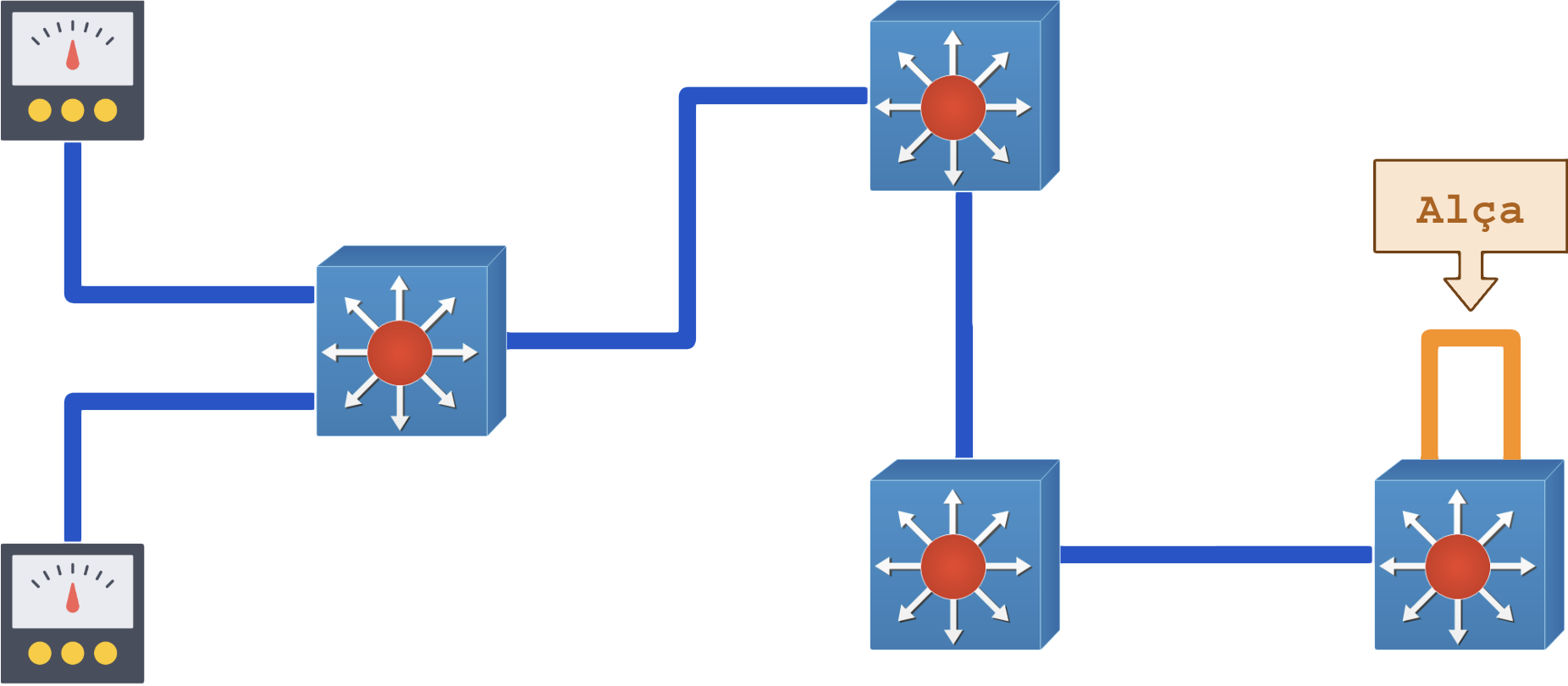
Caso seja necessário testar o full-duplex da rede e envolver equipamentos a longas distâncias, faça uso de um loop “alça de caixão“:
O passo seguinte é homologar o circuito do cliente no backbone MPLS pronto:
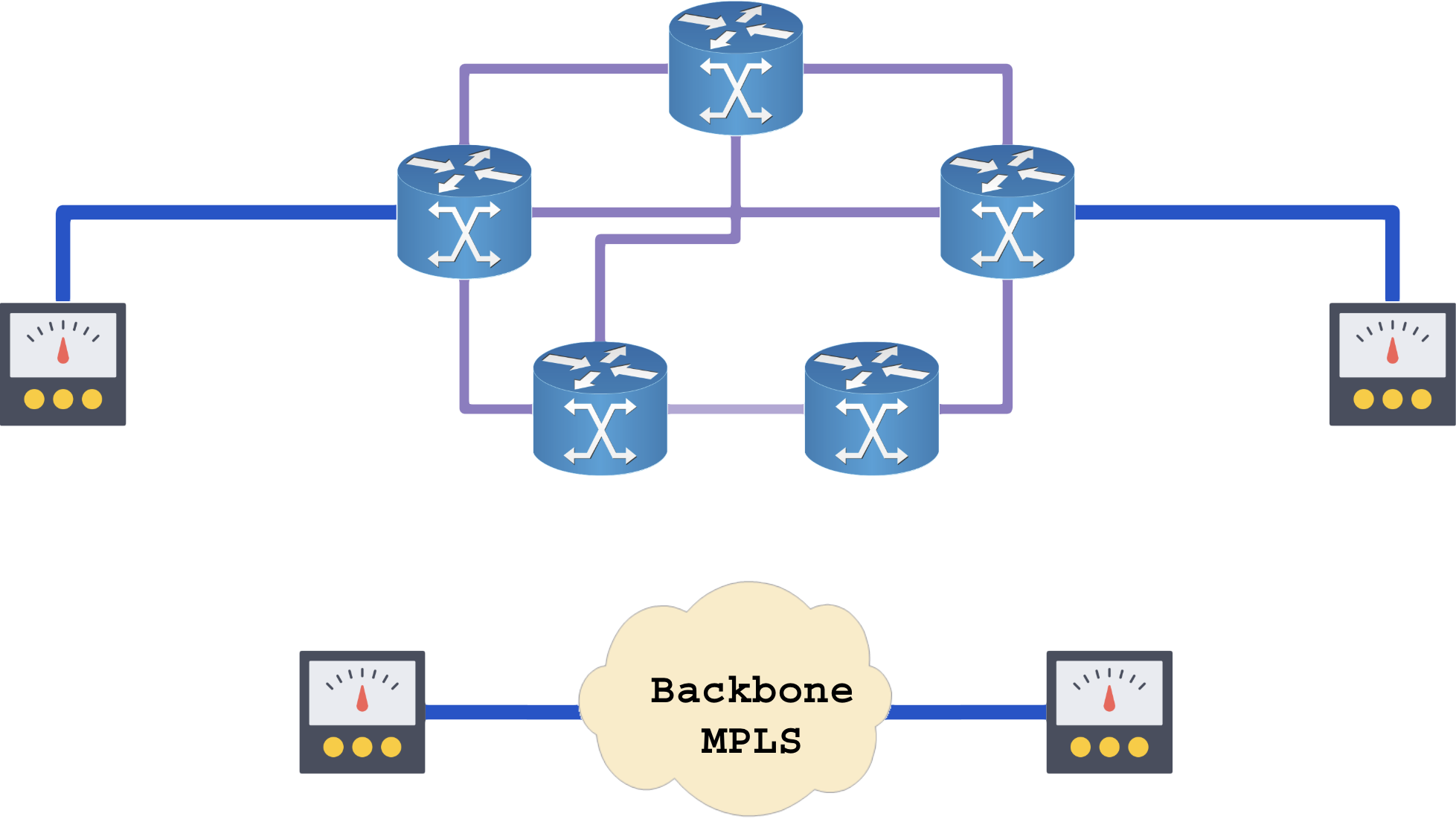
A homologação de backbones MPLS é recomendado apenas em ambientes sem overcommit ou no inicio da construção da rede.
Depois que a rede entra em produção e o LACP + MPLS-TE passam a ser usados como técnicas de prorrogação de upgrades e aliados do overcommit, nenhum teste será bem sucedido em horário comercial (pior ainda em horário de pico ~19:00-22:30).
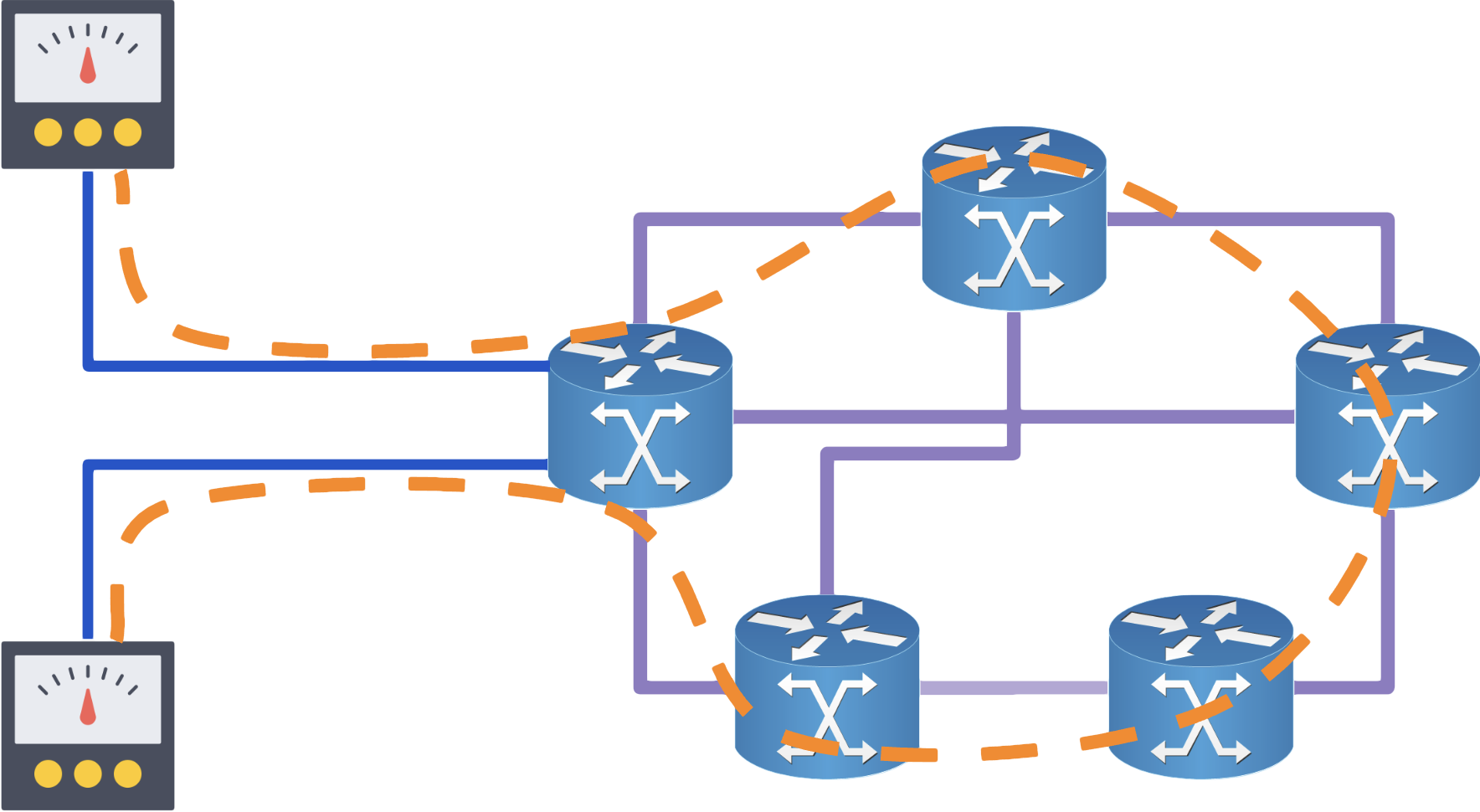
Túneis MPLS-TE podem ajudar a testar caminhos remotamente em loops de TE:
A fronteira final é o teste de homologação entre redes diferentes, raramente é efetivado por falta de cooperação, as empresas não gostam de criar provas contra sí. O overcommit é uma técnica lucrativa ameaçada por homologações.
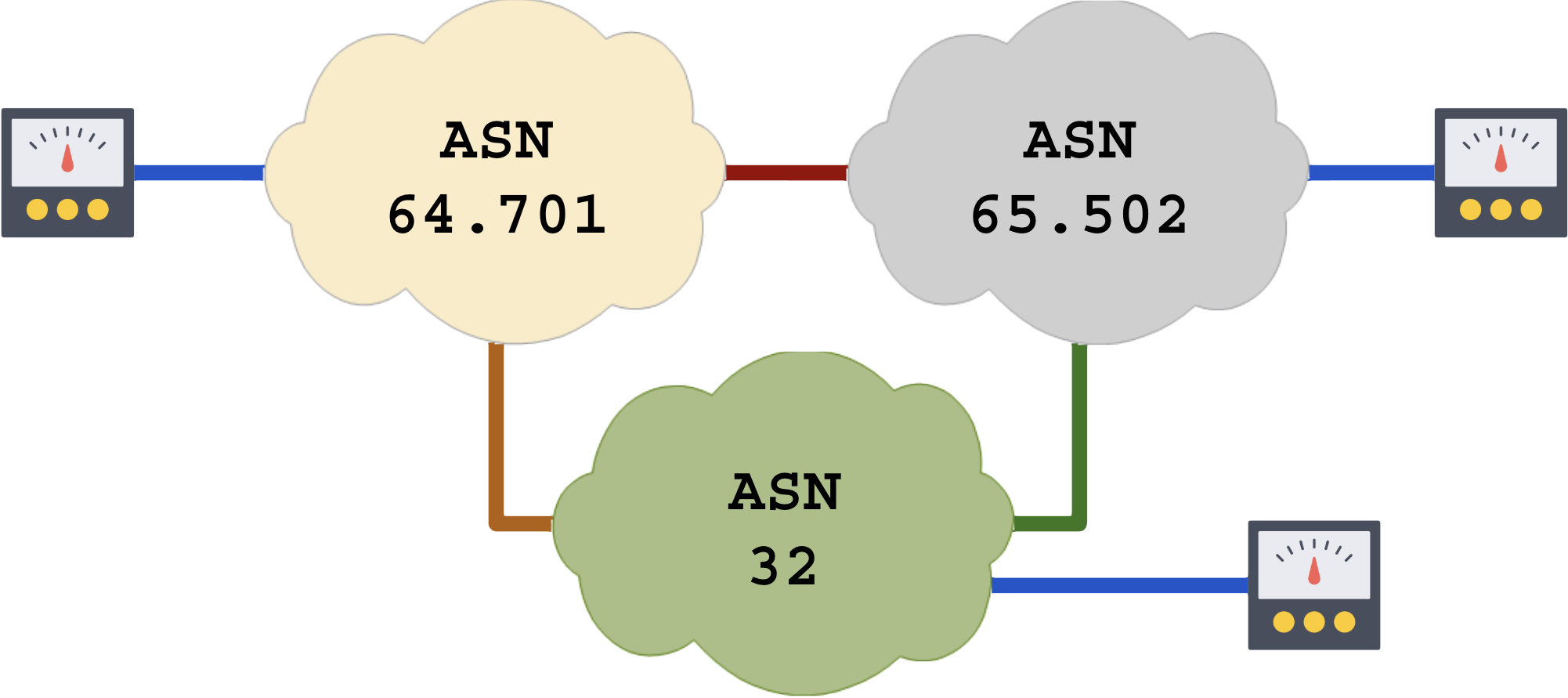
.
4 – Homologando a camada 3
.
4.1 – iPerf3
O iPerf é uma ferramenta de IP Performance desenvolvida para testes de banda entre cliente e servidor iPerf.
Ele não é um software web como o Speedtest. Ele é mais exato, mais avançado e permite testes detalhados com controle de protocolo, burst, paralelismo de conexões e detalhamento de testes nos protocolos TCP, UDP, SCTP, sobre IPv4 e IPv6.
A primeira versão foi criada em 2006 pela NLANR (National Laboratory for Applied Network Research) no grupo de trabalho DAST (Distributed Applications Support Team).
A última versão 3 é mantida pela ESnet (Energy Sciences Network) servindo ao DOE (Department of Energy) dos Estados Unidos.
O iPerf3 é uma ferramenta para medições ativas da largura de banda máxima alcançável em redes IP. Ele suporta o ajuste de vários parâmetros relacionados a temporização, buffers e protocolos (TCP, UDP, SCTP com IPv4 e IPv6). Para cada teste, ele reporta a largura de banda, a perda de pacotes e outros parâmetros. Esta é uma nova implementação que não compartilha código com o iPerf original e também não é compatível com versões anteriores. O iPerf foi originalmente desenvolvido pelo NLANR/DAST . O iPerf3 é desenvolvido principalmente pelo ESnet / Lawrence Berkeley National Laboratory . Ele é distribuído sob uma licença BSD de três cláusulas .
.
“Os homens mais ricos são aqueles que possuem amigos mais poderosos.“
O Poderoso Chefão
Terminamos por hoje!
Patrick Brandão, patrickbrandao@gmail.com